Resampling Techniken
DS3 - Vom experimentellen Design zur
explorativen Datenanalyse & Data Mining
Universität Hamburg, IMF
Wintersemester 2025/2026
Lernziele
![]()
Am Ende dieser VL- und Übungseinheit werden Sie
- das sog. Bootstrap-Verfahrens auf reale Datensätze anwenden können, um Konfidenzintervalle für Punktschätzungen zu erstellen.
- wissen, wie das Bootstrap-Verfahren funktioniert, insbesondere wie Stichproben MIT Zurücklegen aus einer vorhandenen Stichprobe gezogen werden.
- das Konzepts der Permutation von Beobachtungen kennen und wissen, wie Permutationstests auf verschiedene Arten von Daten anzuwenden sind, um Hypothesen über Populationsparameter zu testen.
- in der Lage sein, die Ergebnisse von Permutationstests zu interpretieren und zu verstehen, wie statistische Signifikanz in diesem Kontext definiert ist.
- Permutationstests mit anderen Hypothesentestverfahren zu vergleichen und die Vor- und Nachteile jeder Methode zu verstehen.
Unser Thema heute

Grafik von Nina Garman (Pixabay)
Bootstrapping
Intervallschätzung | 1
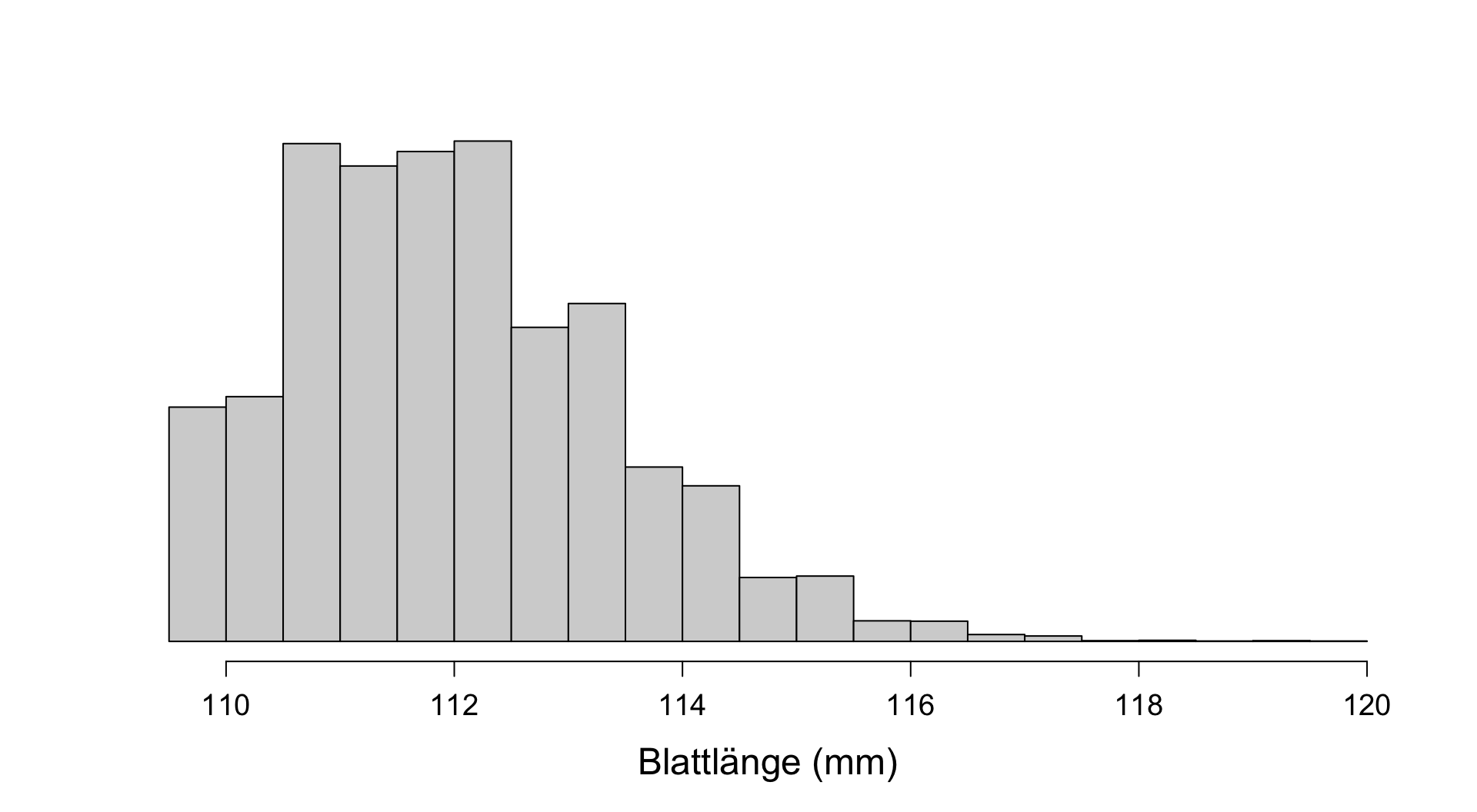
Zur Erinnerung ein Beispiel aus DS2
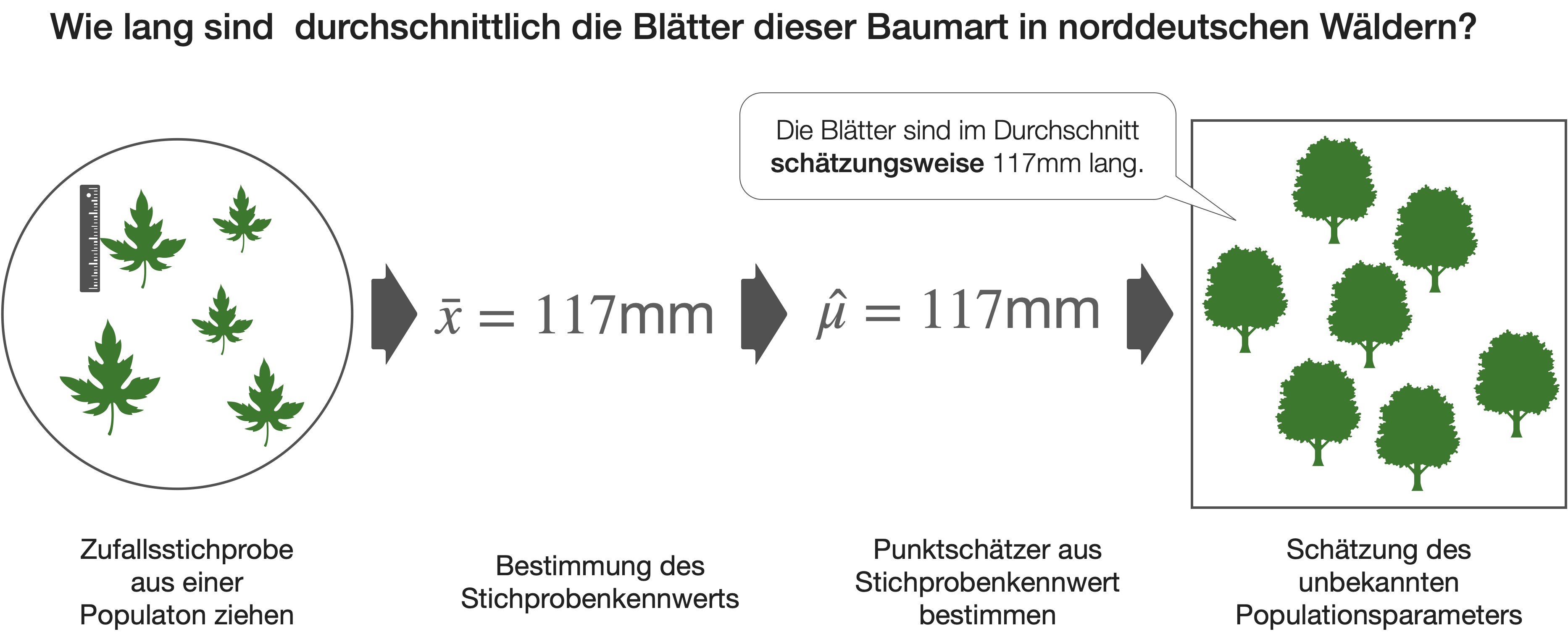
- Wie präzise ist diese Schätzung von 117mm?
- Kann es denn sein, dass der wahre Populationsmittelwert auch 100mm oder 140mm ist und wir einfach Pech mit der Probe hatten?
- In welchem Bereich liegt der wahre Mittelwert höchstwahrscheinlich?
Intervallschätzung | 2
Zur Erinnerung ein Beispiel aus DS2
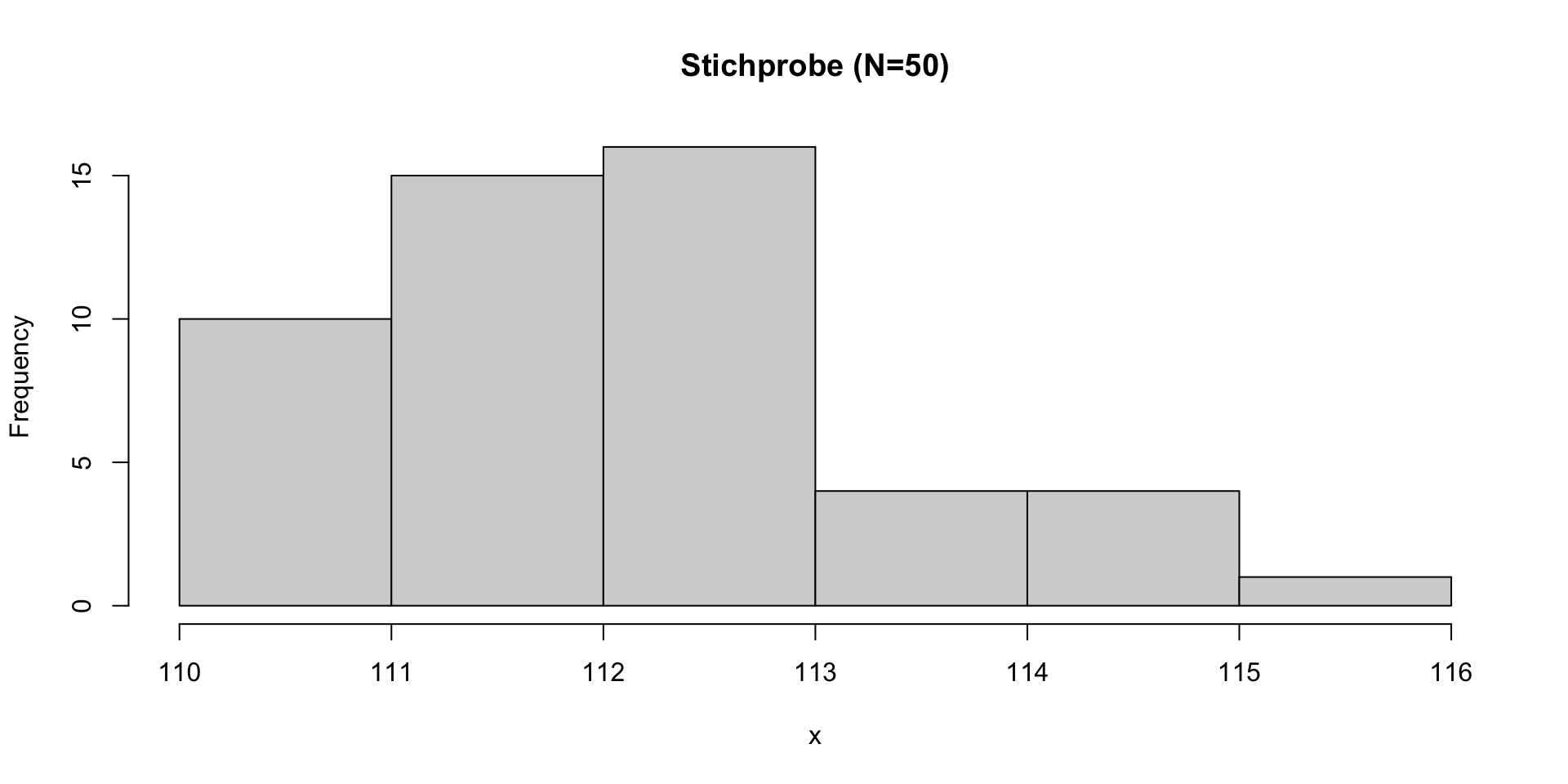


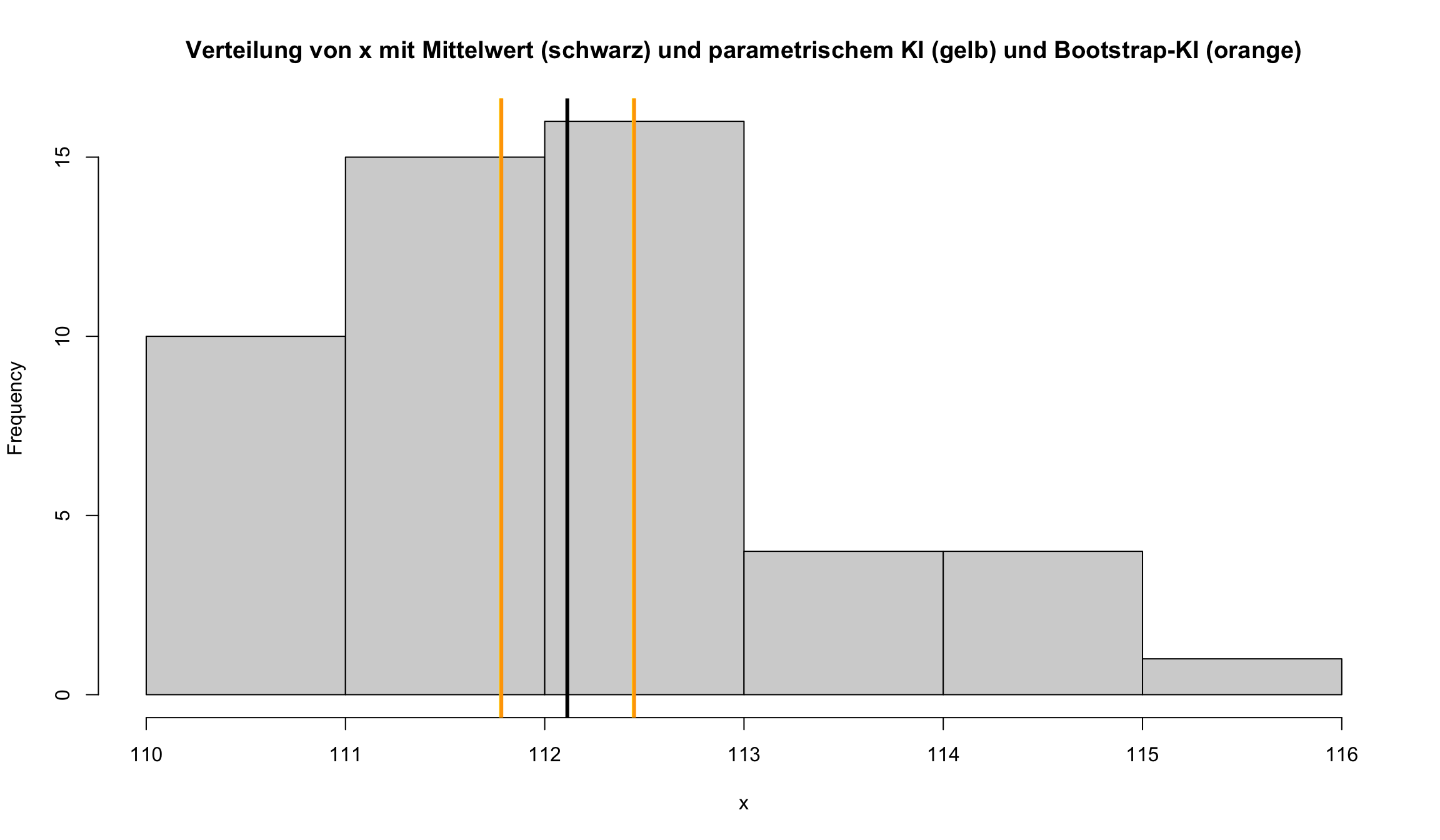
Bootstrapping | Berechnung
→ Das 95%-Bootstrap-Konfidenzintervall für den Populationsmittelwert reicht von 111.8 bis 112.4.
Bootstrapping | Vergleich
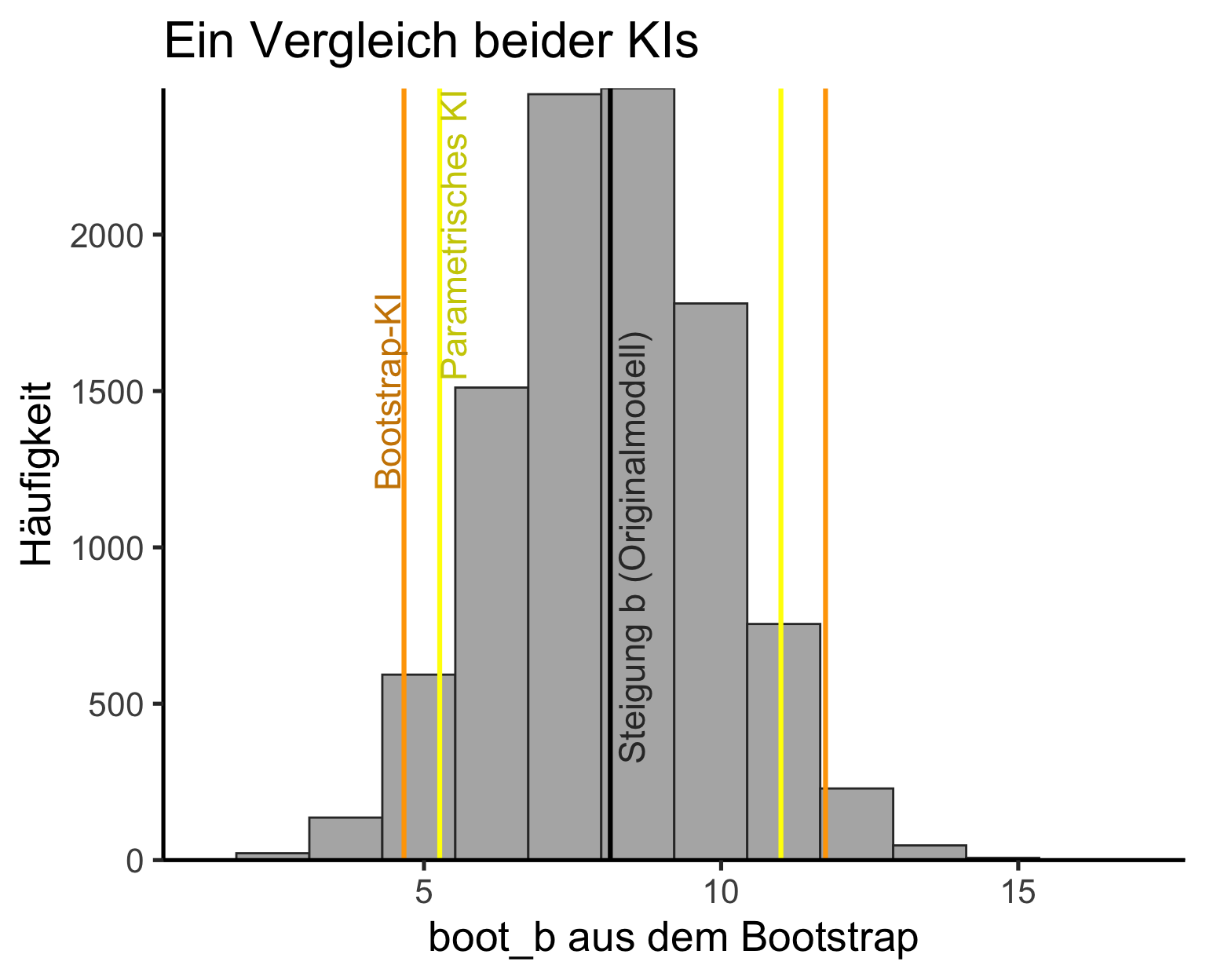
Schätzung von KI für Regressionsparameter
Wenn Annahmen nicht erfüllt sind
- Der Steigungsparameter b der Stichprobe als Punktschätzer für die Population beträgt 8.1.
- Gegeben, dass die Daten normalverteilt und varianzhomogen sind → können wir uns zu 95 % sicher sein, dass bei einer Wiederholung der Datenerhebung die Regressionssteigung für diese neuen Daten zwischen 5.3 und 11.0 liegen würde.
Code
df$res <- residuals(mod_lm)
df$fit <- fitted(mod_lm)
p1 <- ggplot(df, aes(y)) +
geom_histogram(bins = 10, fill = "grey50", colour = "grey10") +
ggtitle("Histogramm von Y")
p2 <- ggplot(df, aes(x, y)) + geom_point() +
geom_smooth(method = "lm", se = TRUE) +
ggtitle("Beziehung Y ~ X")
p3 <- ggplot(df, aes(res)) +
geom_histogram(bins = 10, fill = "grey50", colour = "grey10") +
ggtitle("Histogramm der Residuen")
p4 <- ggplot(df, aes(fit, res)) + geom_point() +
geom_hline(yintercept = 0) +
ggtitle("Residuen vs. fitted")
gridExtra::grid.arrange(p1, p2, p3, p4)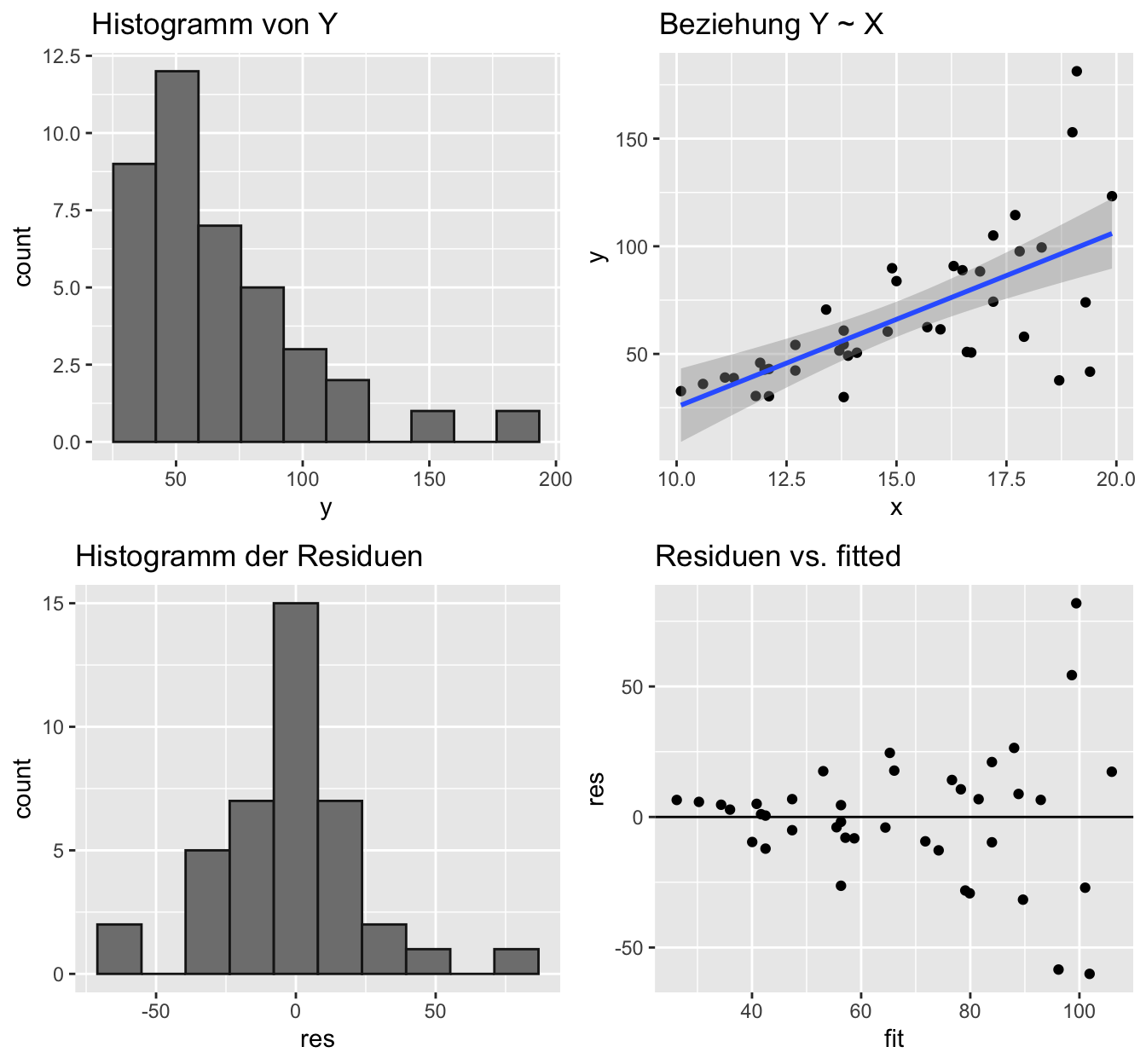
Schätzung von KI für Regressionsparameter
Bootstrapping
2.5% 97.5%
4.663306 11.757071 → Der Konfidenzbereich liegt nun zwischen 4.7 und 11.8.
Permutationstest
Beispiel 1: Zwei-Stichproben-Vergleich
Schneckenrennen
Unterscheiden sich zwei Schneckenarten in ihrer Laufgeschwindigkeit (in m/Stunde)?

Zwei-Stichproben-Vergleich | Daten
# A tibble: 2 × 3
Art Mittelwert Standardabweichung
<chr> <dbl> <dbl>
1 A 5.33 3.08
2 B 8.33 2.16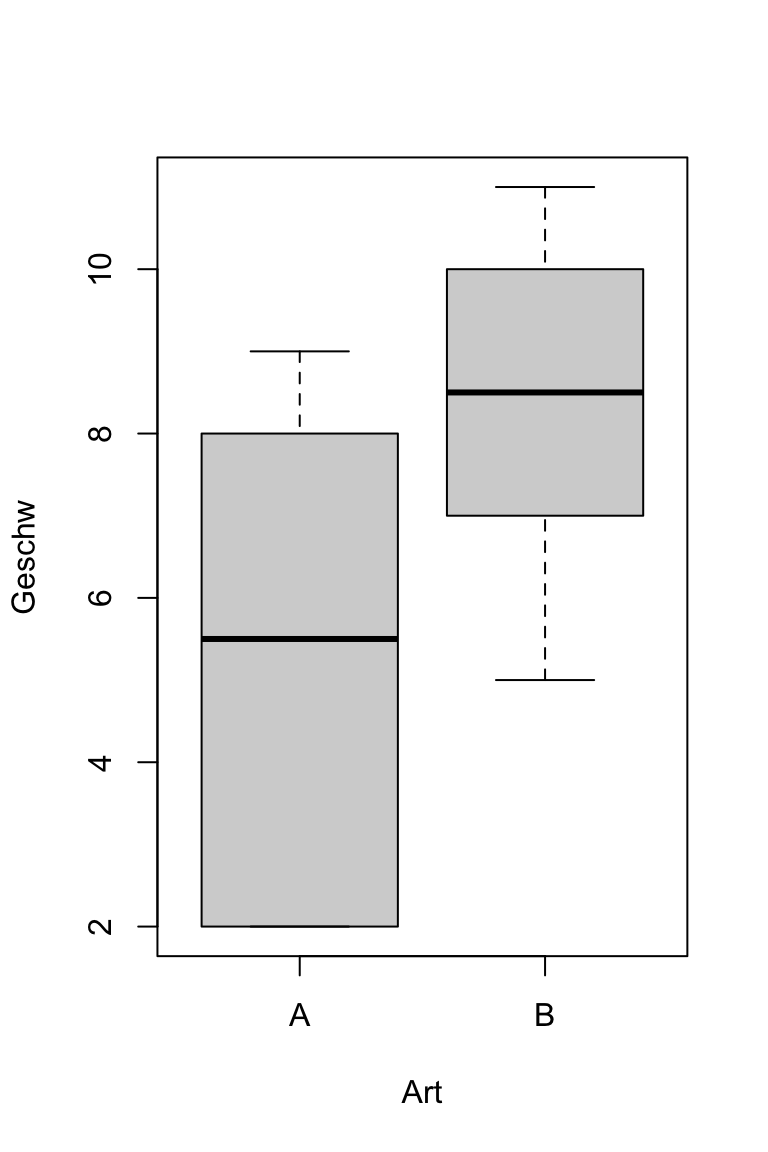
Zwei-Stichproben-Vergleich | Verteilung
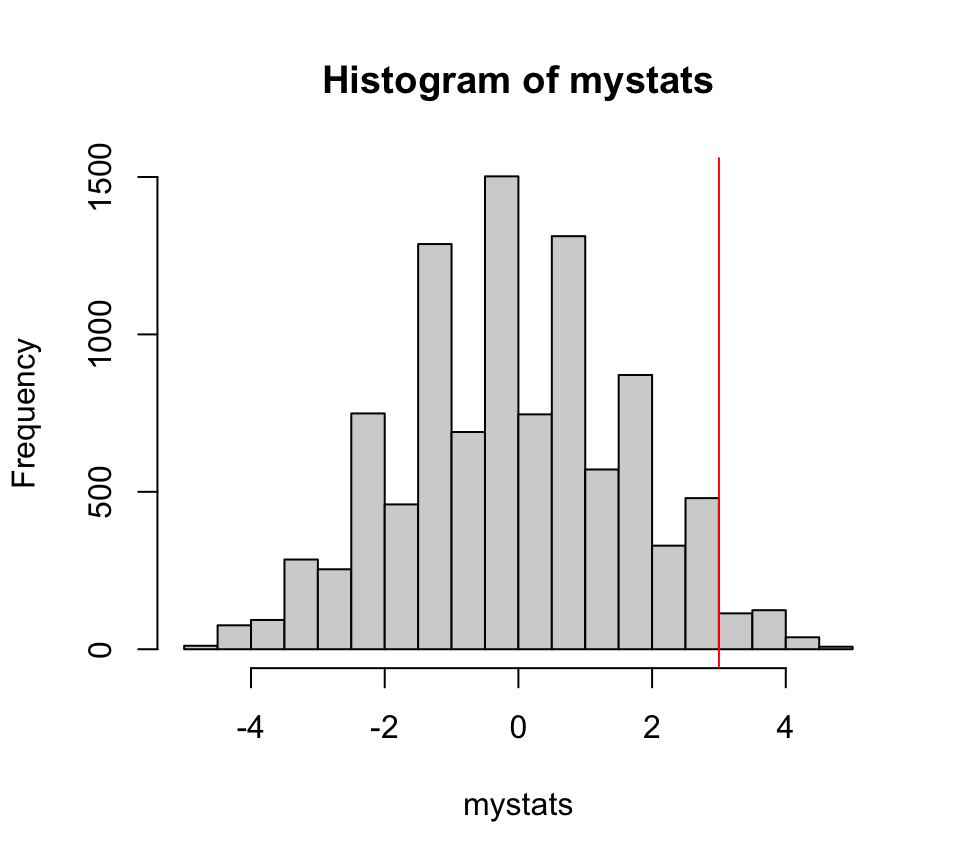
[1] 475[1] 0.0475[1] 940[1] 0.094Beispiel 2: ANCOVA
Schnabellänge bei Adélie Pinguinen
![]()
Call:
lm(formula = body_mass_g ~ flipper_length_mm + sex, data = adelie)
Residuals:
Min 1Q Median 3Q Max
-662.85 -213.18 -6.27 207.42 743.73
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 305.087 755.580 0.404 0.687
flipper_length_mm 16.314 4.019 4.059 8.08e-05 ***
sexmale 599.343 52.246 11.472 < 2e-16 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 295.1 on 143 degrees of freedom
Multiple R-squared: 0.5918, Adjusted R-squared: 0.5861
F-statistic: 103.6 on 2 and 143 DF, p-value: < 2.2e-16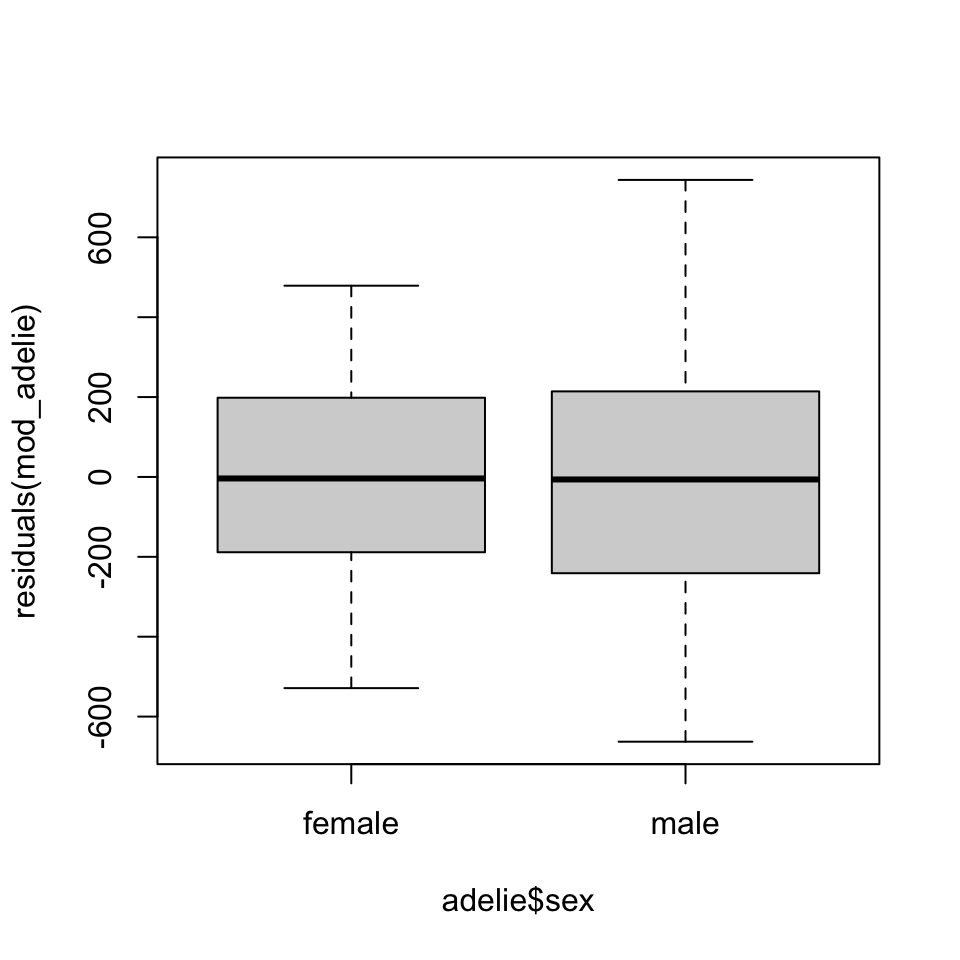
Beispiel 2: ANCOVA
Schnabellänge bei Adélie Pinguinen
![]()
Hier gibt es 2 Möglichkeiten der Permutation:
- Permutation des Faktors:
- Testet den Effekt des Faktors auf die Antwortvariable, nachdem die Kovariate kontrolliert wurde. Fokus auf den Faktoreffekt.
- Permutation der Antwortvariable:
- Testet die gesamte Modellanpassung, d. h. ob der Faktor und die Kovariate zusammen die Antwortvariable erklären. Fokus auf die Gesamtanpassung des Modells.
ANCOVA | Permutation des Faktors 1
![]()
Wir extrahieren zuerst die F-Statistik aus der drop1() Funktion.
Single term deletions
Model:
body_mass_g ~ flipper_length_mm + sex
Df Sum of Sq RSS AIC F value Pr(>F)
<none> 12450275 1663.6
flipper_length_mm 1 1434486 13884760 1677.5 16.476 8.077e-05 ***
sex 1 11457596 23907871 1756.9 131.598 < 2.2e-16 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1ANCOVA | Permutation des Faktors 2
![]()
ANCOVA | Permutation des Faktors 2
![]()
Wir schreiben die Schleife
ANCOVA | Permutation des Faktors 3
![]()
Verteilung der Teststatistik
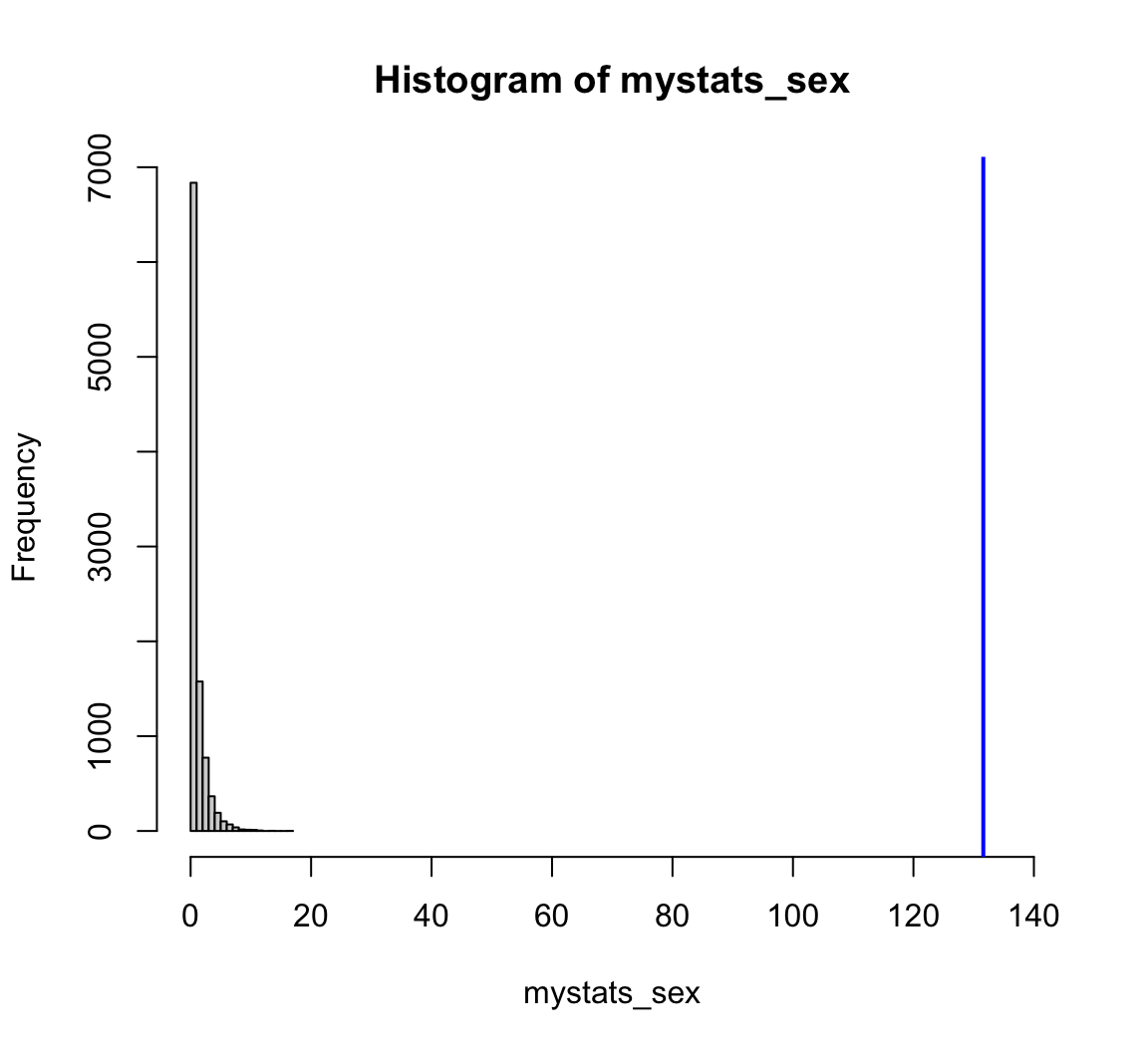
[1] 0[1] 0INTERPRETATION:
- die Wahrscheinlichkeit, dass die beobachteten Daten unter der Annahme der H0 auftreten, liegt beim Faktor ‘sex’ unter 5 %.
- Wir können daher die H0 ablehnen, es gibt einen signifikanten Effekt des Geschlechts.
Your turn …
![]()
Quiz 1+2 | Bootstrap-KI für den Mittelwert
![]()
Quiz 3 | Permutation 2-Stichproben-Vergl. 1
![]()
Quiz 4 | Permutation 2-Stichproben-Vergl. 2
Interpretation
![]()
Bootstrap & Permutation bei linearer Regression
Bei der folgenden einfachen linearen Regression sind nicht alle Modellannahmen erfüllt, wie Residuenplots (rechts) zeigen:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 48.907219 10.776106 4.538487 1.373153e-05
area 5.403289 1.780359 3.034943 2.960263e-03lower_ci upper_ci
1.913785 8.892793 Wir wollen daher für den Steigungsparameter das Konfidenzintervall per Bootstrapverfahren und den p-Wert per Permutationstest berechnen.
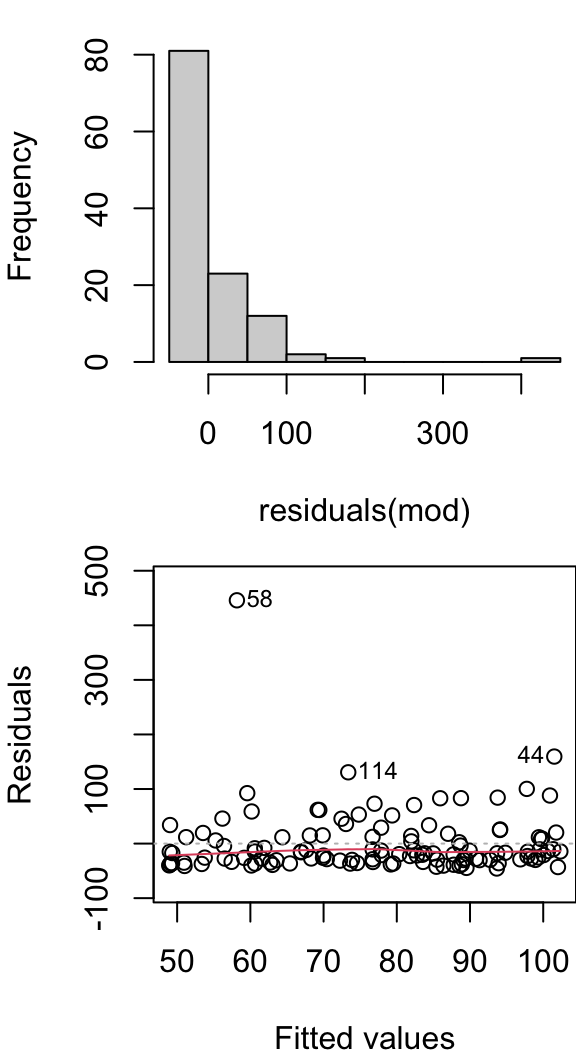
Quiz 5 | Lineare Regression
![]()
![]()
Quiz 6 | Lineare Regression
Interpretation
![]()
Übungen
Übungswoche 5
![]()
1. Bootstrap-Konfidenzintervall bei Graugänsen
2. Permutationstest zur Alpakawolle
Vorbereitung @home
Mit Schleifen programmieren
- Sehen Sie sich die letzte Vorlesung in Data Science 1 zum Thema Schleifen & Simulationen erneut an: 14-advanced-programming.html#/schleifen-simulationen
- Bearbeiten Sie die Lektion 4 (L04-Schleifen und erste Simulationen) des swirl-Kurses ‘DSB-06-Fortgeschrittene_R_Programmierung’.
- Beantworten Sie vor der fünften Übungsstunde die Fragen zu Schleifen im Moodle-Quiz.
Fragen..??

Total konfus?

Buchkapitel zum Nachlesen
- The R Book von M.J. Crawley:
- Kapitel 8.12 Bootstrap
- Wikipedia zu Bootstrap (https://en.wikipedia.org/wiki/Bootstrapping_(statistics))
Total gelangweilt?

Dann testen Sie doch Ihr Wissen in folgendem Abschlussquiz…
Abschlussquiz
![]()
Bei weiteren Fragen: saskia.otto(at)uni-hamburg.de

Diese Arbeit is lizenziert unter einer Creative Commons Attribution-ShareAlike 4.0 International License mit Ausnahme der entliehenen und mit Quellenangabe versehenen Abbildungen.