x <- 10L
if ( is.integer(x) ) {
print(
"Yes, x is an integer!")
}[1] "Yes, x is an integer!"if ( is.double(x) ) {
x*2
}Data Science 1 - Programmieren & Visualisieren
Universität Hamburg, IMF
Wintersemester 2024/2025
![]()
Eine Übersicht der wichtigsten Funktionen gibt es hier:

Dieses wie alle anderen DSB Cheatsheets gibt es auf Moodle und der GitHub Repository uham-bio/Cheatsheets.
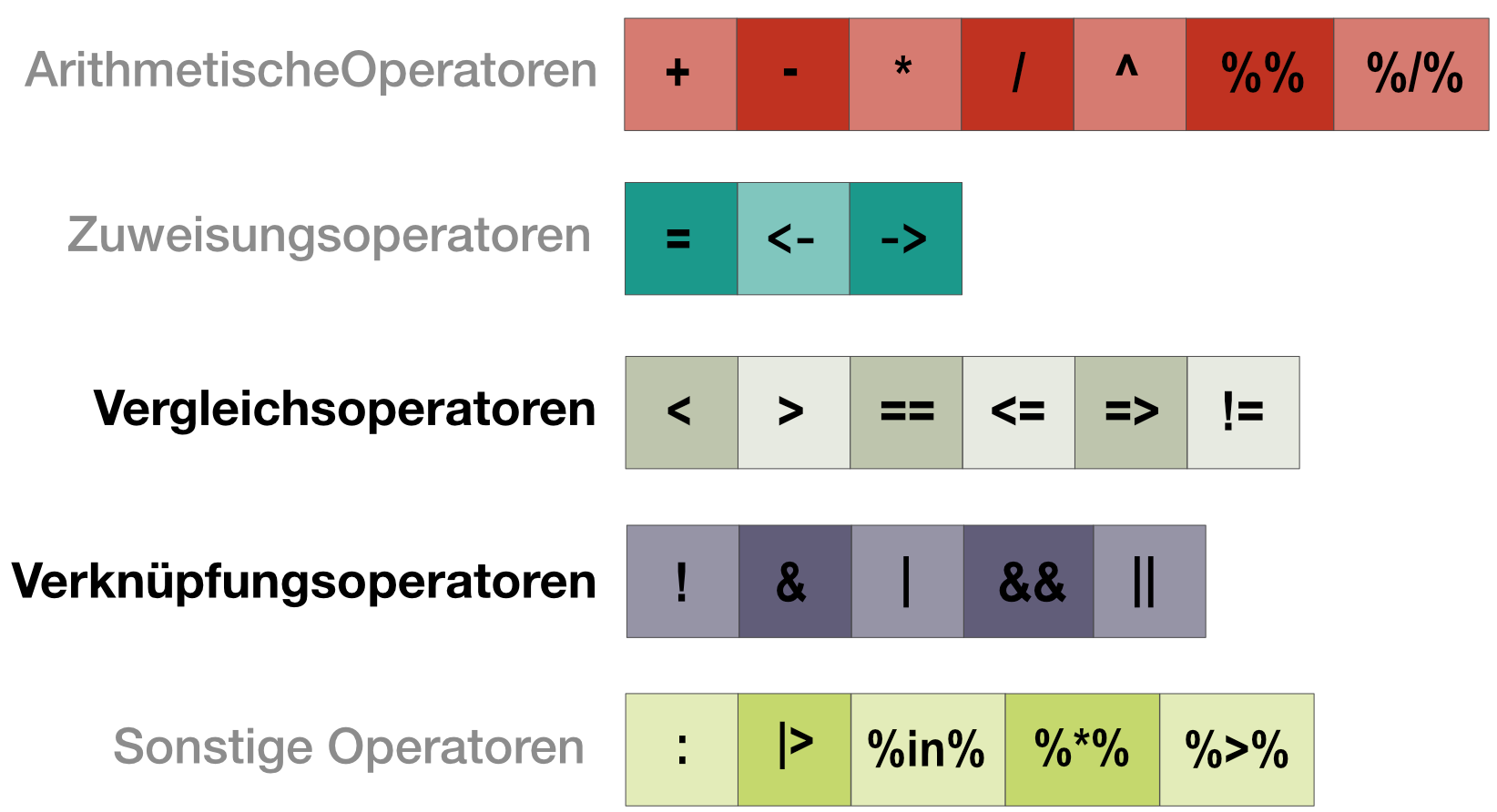
Vergleichs- und Verknüpfungsoperatoren geben immer einen logischen Wert (TRUE oder FALSE) zurück.
![]()
# Beispieldatensatz mit Altersangaben
ages <- c(8, 25, 42, 60, 75, 30, 18, 5)
# Erstellung einer neuen Variable auf
# Grundlage des Alters
age_group <- character(length(ages))
# Bedingung innerhalb einer Schleife
for (i in 1:length(ages)) {
if (ages[i] < 18) {
age_group[i] <- "Child"
} else if (ages[i] >= 18 & ages[i] < 65) {
age_group[i] <- "Adult"
} else {
age_group[i] <- "Senior"
}
}
# Kombinieren beider Variablen
result <- data.frame(ages, age_group)age_group, auf der Grundlage der Altersinformationen im Altersvektor.result, enthält die ursprünglichen Altersangaben und die entsprechenden Altersgruppen.Diese Art von if-else-Logik wird häufig in der Datenanalyse verwendet und hilft bei der Kategorisierung von Daten in verschiedene Gruppen auf der Grundlage bestimmter Bedingungen.
ifelse()![]()
01:30
![]()
![]()
Der Körper einer Bedingung (wie auch Schleife und Funktion) wird immer in geschweifte Klammern gesetzt, damit er über mehrere Zeilen gehen kann.
In der Abfrage muss ein Operator stehen, welcher die Abfrage wahr macht, denn der Codeblock in der Bedingung wird ja ausgeführt. Richtig ist daher:
Anhand der zweimaligen geschweiften Klammern wird deutlich, dass es sich um eine ‘if..else..’ Bedingung handelt.
An der Ausgabe 0 ist zu erkennen, dass der Alternativbefehl (in ‘else’) ausgeführt wurde. In die zweite Lücke muss daher ein Operator, bei der die Abfrage FALSE ergibt:
for): führen eine bestimmte Anzahl an Wiederholungen aus, die durch einen Zähler oder einen Index kontrolliert wird. Dieser erhöht sich mit jeder Iteration.while) vs. fußgesteuerte/nachprüfende Schleifen (repeat): basieren auf ein Einsetzen und einer Verifikation durch eine logische Bedingung. Die Bedingung wird zu Beginn oder zum Ende des Schleifenkonstrukts getestet.for Schleife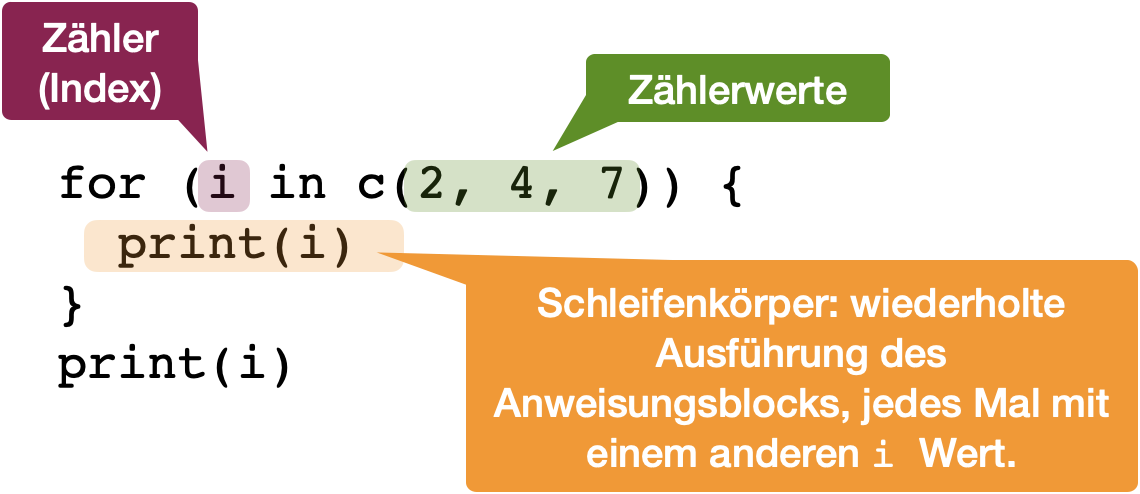
for Schleife
for Schleife - Stile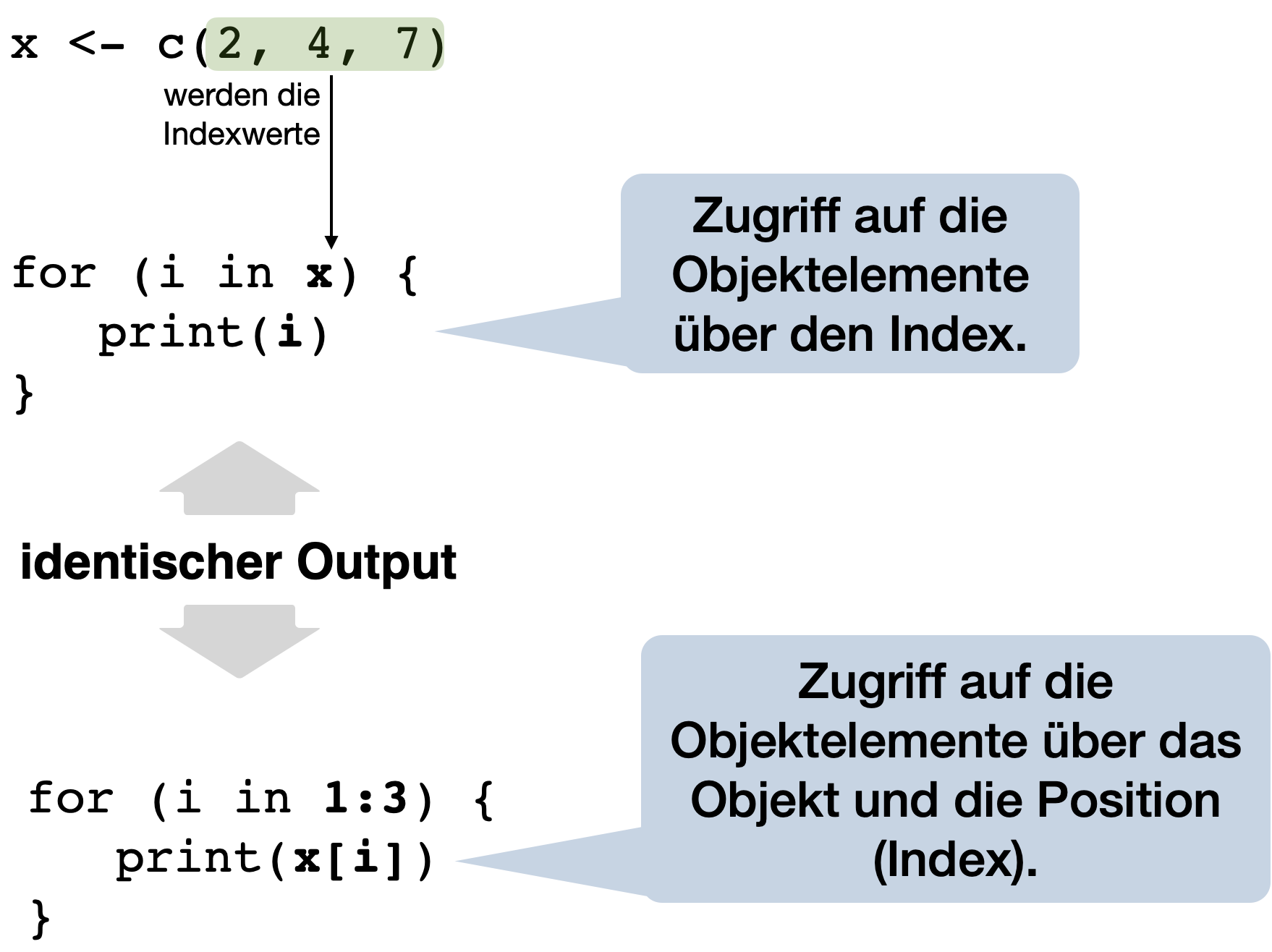
Testen wir die Geschwindigkeit der beiden Funktionen
Unit: milliseconds
expr min lq mean median uq max
grow_obj(500) 0.227181 0.236652 1.1734200 0.247230 1.519706 3.636331
grow_obj(5000) 25.784818 27.081935 27.9111518 28.075037 28.139120 30.474849
index_obj(500) 0.051127 0.057851 0.3215056 0.067404 0.071545 1.359601
index_obj(5000) 0.459282 0.476379 1.1939446 0.485768 0.525620 4.022674
neval cld
5 a
5 b
5 a
5 a In der Spalte mean ist zu sehen, dass die Variante mit der ‘Indexierung’ viel schneller ist als die mit wachsenden Objekten, besonders wenn viele Wiederholungen gemacht werden!
![]()
![]()
[1] "file_001.csv" "file_002.csv" "file_003.csv" "file_004.csv" "file_005.csv"
[6] "file_006.csv" "file_007.csv" "file_008.csv" "file_009.csv" "file_010.csv"Import aller 10 Dateien und Zusammenführung zu EINEM data frame
# Leere Liste für die importierten Datensätze
data_list <- vector("list", length = length(files))
# Schleife, bei der in jeder Iteration eine Datei importiert wird
for (i in seq_along(files)) {
data_list[[i]] <- read.csv(files[i])
}
# Zusammenfügen der einzelnen data frames in der Liste
data_df <- dplyr::bind_rows(data_list)'data.frame': 200 obs. of 3 variables:
$ station: chr "A" "A" "A" "A" ...
$ x : int 40 24 23 12 46 48 34 35 36 41 ...
$ y : num 28.93 14.49 1.67 9.51 20.64 ...# A tibble: 10 × 2
# Groups: station [10]
station n
<chr> <int>
1 A 20
2 B 20
3 C 20
4 D 20
5 E 20
6 F 20
7 G 20
8 H 20
9 I 20
10 J 20![]()
01:30
![]()
![]()
Anhand der Abfrage ist erkennbar, dass es sich um eine ‘while..’ Schleife handeln muss. Auch hier gilt wieder: der Schleifenblock gehört in geschweifte Klammern!
Und da eine ‘while..’ Schleife nur mehrere Iterationen durchgeht, wenn der Input in der Abfrage sich ändert, muss sich hier a im Schleifenkörper um den Wert erhöhen, den der Output sich erhöht (weil dieser a darstellt.)
Hier ist keine Abfrage jeweils zu sehen, sondern es wird ein Zählerindex definiert. Also muss es sich um die Zählschleife (‘for..’) handeln. Und zwar 2 ineinander verschachtelte. Wichtig ist hierbei, dass der Zähler unterschiedlich ist. Die erste Schleife hat meist den Index i, die nächste j, etc.).
Der innerste Schleifenkörper macht folgendes: es sollen die beiden Indizes zusammengefügt werden (mittels Funktion paste()) unter Verwendung des Trennzeichen ‘/’ . Damit dies auch wirklich in der Konsole sichtbar ist, braucht es aber die Funktion print(), welche als Input paste() enhält.

Das diskrete logistische Wachstum mit Dichte-Abhängigkeit lässt sich mit folgender Gleichung beschreiben:
\[N_{t+1}=N_t+rN_t\left(1-\frac{N_t}{K}\right)\]
Nt <- 1 # neuer Start
# Grafik erstellen mit Startwert
plot(0, Nt,
xlim = c(0, 50), # t max = 50
ylim = c(0, 120), # weil K=100
col="black", pch = 16,
xlab = "Generation",
ylab = "Population size")
for (t in 1:50) {
Nt1 <- Nt + r*Nt * (1 - (Nt/K))
# neuen Wert in die Grafik fügen
points(t, Nt1,
col="red", pch = 16)
Nt <- Nt1
# Verzögerung der Simulation:
Sys.sleep(0.2)
}Hier mit 50 Zeiteinheiten:
![]()
02:30
![]()
![]()
\[N_{t+1}=N_t+rN_t\left(1-\frac{N_t}{K}\right)\]
N0 <- 1
N <- numeric(20)
N[1] <- N0
r <- 0.5
K <- 100
for (t in 2:20) {
N[t] <- N[t-1] + r*N[t-1] * (1 - (N[t-1]/K))
}
N [1] 1.000000 1.495000 2.231325 3.322093 4.927958 7.270514 10.641469
[8] 15.395999 21.908814 30.463241 41.054816 53.154734 65.604972 76.887397
[15] 85.772736 91.874293 95.607011 97.707014 98.827218 99.406732
\[\gamma_1 = \frac{\frac{1}{n}\sum\limits_{i=1}^{n} \left(x_{i} - \bar{x}\right)^{3}} {(\frac{1}{n}\sum\limits_{i=1}^{n} \left(x_{i} - \bar{x}\right)^{2})^{3/2}}\]
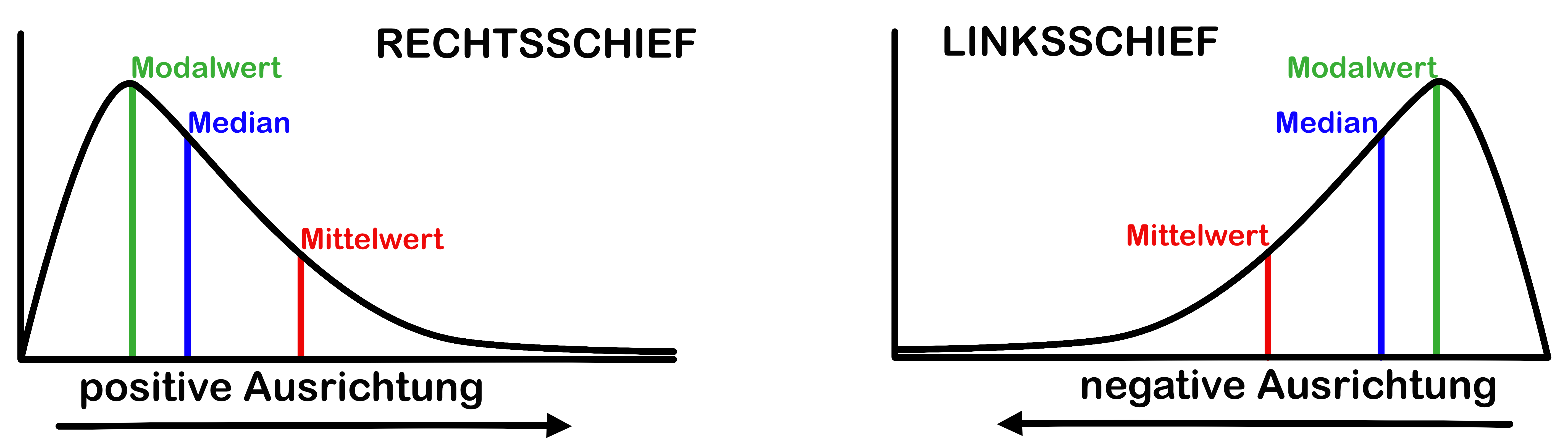
\[\gamma_1 = \frac{\frac{1}{n}\sum\limits_{i=1}^{n} \left(x_{i} - \bar{x}\right)^{3}} {(\frac{1}{n}\sum\limits_{i=1}^{n} \left(x_{i} - \bar{x}\right)^{2})^{3/2}}\]
Was machen wir, wenn der Vektor NAs enthält?
Wir führen ein weiteres Argument ein und bauen eine Bedingung in die Funktion!
[1] 0.3237934![]()
01:30
![]()
![]()
Die Funktion mit der eine Funktion definiert wird nennt sich function(). Um den Funktionskörper in einer nächsten Zeile anzeigen zu können und ggf. auch über mehrere Zeilen, braucht es die schweiften Klammern vorher und nachher.
Eine Funktion sollte nicht auf Skalare und andere Objekte zugreifen, die nicht innerhalb der Funktion definiert werden bzw. als Argument übergeben werden. Hier wird auf x und y zugegriffen, daher müssen diese als Argument definiert werden (function(x,y)). Das berechnete Produkt z wird explizit mit return(z) ausgegeben.




![]()
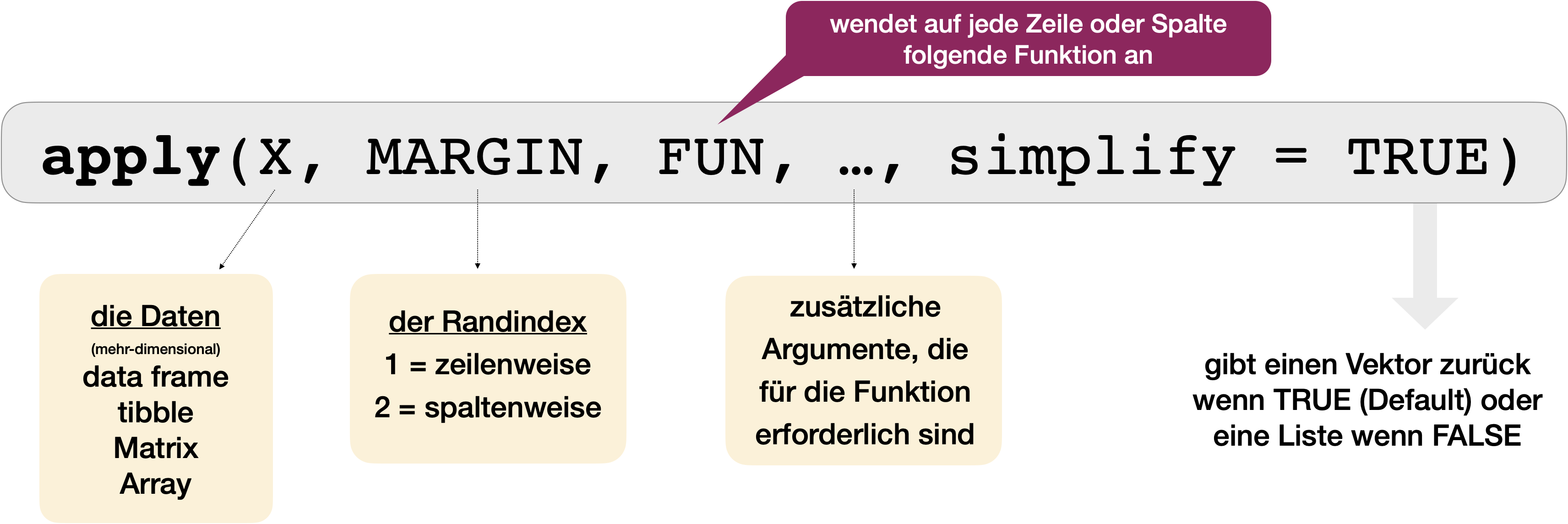
apply(), lapply(), sapply(), vapply(), tapply(), mapply()) macht genau das: Diese Funktionen wenden eine ausgewählte oder selbst definierte Funktion mit einer oder mehreren optionalen Argumenten auf Listen, Vektoren, ‘data frames’, Matrizen oder Arrays an.
Summe der 3 Spalten pro Zeile (Output als Vektor)
[1] 0.12799996 0.71241794 -0.06410025 0.16259230 0.26057783 -1.58409228
[7] 0.69621551 0.03610525 -0.01471492 0.99366090 3.26856660 -0.32497088
[13] 0.10755072 -3.39786802 1.18089506 1.52047173 -0.77770169 -0.15961181
[19] 2.49096619 1.22202247Summe der 3 Spalten pro Zeile (Output als Liste)
[[1]]
[1] 0.128
[[2]]
[1] 0.7124179
[[3]]
[1] -0.06410025
[[4]]
[1] 0.1625923
[[5]]
[1] 0.2605778
[[6]]
[1] -1.584092
[[7]]
[1] 0.6962155
[[8]]
[1] 0.03610525
[[9]]
[1] -0.01471492
[[10]]
[1] 0.9936609
[[11]]
[1] 3.268567
[[12]]
[1] -0.3249709
[[13]]
[1] 0.1075507
[[14]]
[1] -3.397868
[[15]]
[1] 1.180895
[[16]]
[1] 1.520472
[[17]]
[1] -0.7777017
[[18]]
[1] -0.1596118
[[19]]
[1] 2.490966
[[20]]
[1] 1.222022
![]()

Sie sind jetzt so weit, …
..dass Sie selbst versuchen können, eine Funktion für die Kurtosis und Schiefe und Standardfehler zu erstellen.


Dann testen Sie doch Ihr Wissen in folgendem Abschlussquiz…
![]()
Bei weiteren Fragen: saskia.otto(at)uni-hamburg.de

Diese Arbeit is lizenziert unter einer Creative Commons Attribution-ShareAlike 4.0 International License mit Ausnahme der entliehenen und mit Quellenangabe versehenen Abbildungen.