





data(penguins, package = "palmerpenguins")
penguins_sub <- penguins |>
filter(species %in% c("Adelie","Gentoo")) |>
drop_na() |>
mutate(species = fct_drop(species))
pairs(penguins_sub)
DS3 - Explorative Datenanalyse & Data Mining
Universität Hamburg, IMF
Wintersemester 2023/2024
![]()













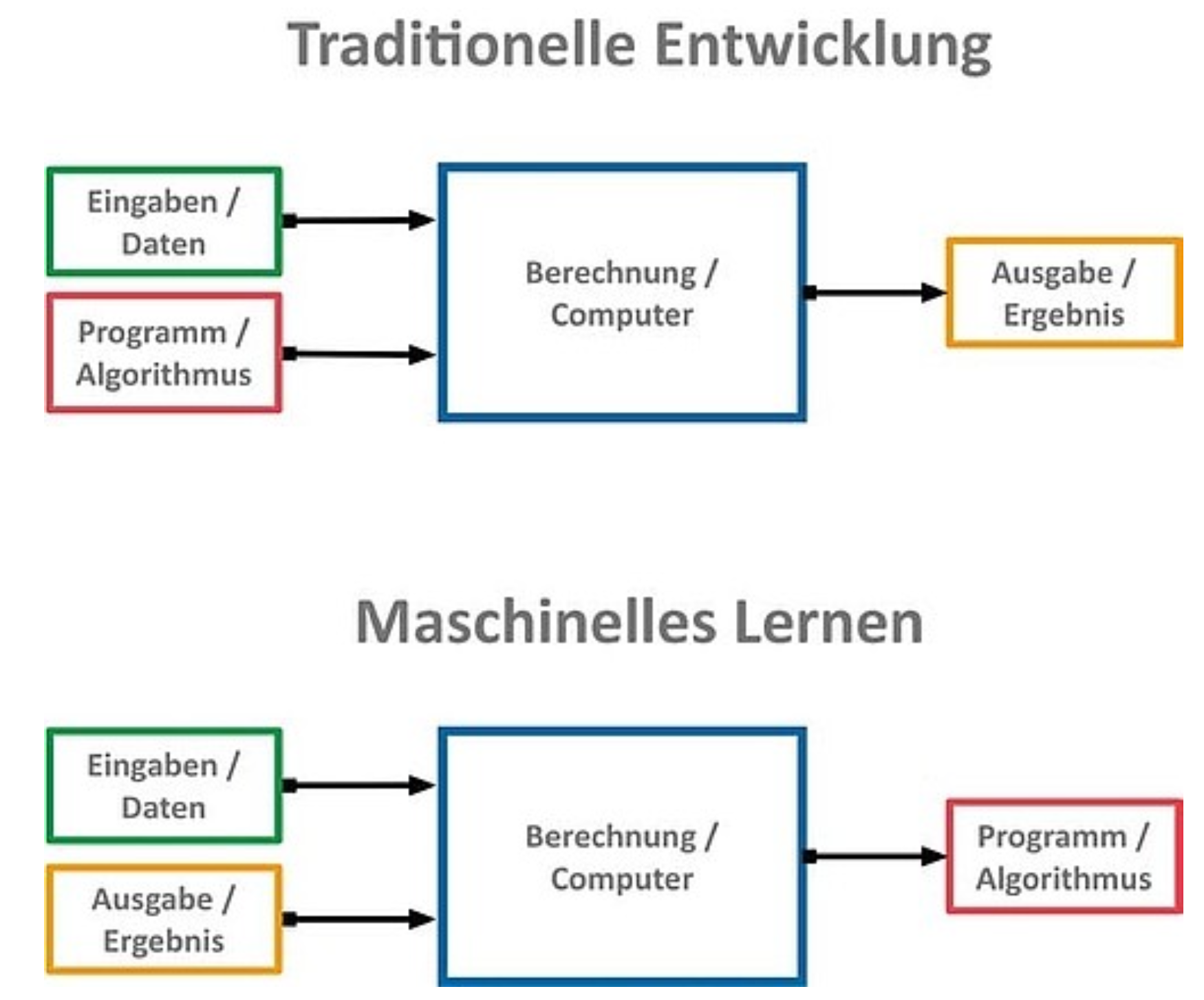
→ Die Wissenschaft des Lernens spielt eine Schlüsselrolle in den Bereichen Statistik, Data Mining und künstliche Intelligenz und überschneidet sich mit Bereichen der Ingenieurwissenschaften und anderen Disziplinen.
![]()
Bildquelle: Morimoto & Ponton (2021): Virtual reality in biology: could we become virtual naturalists?
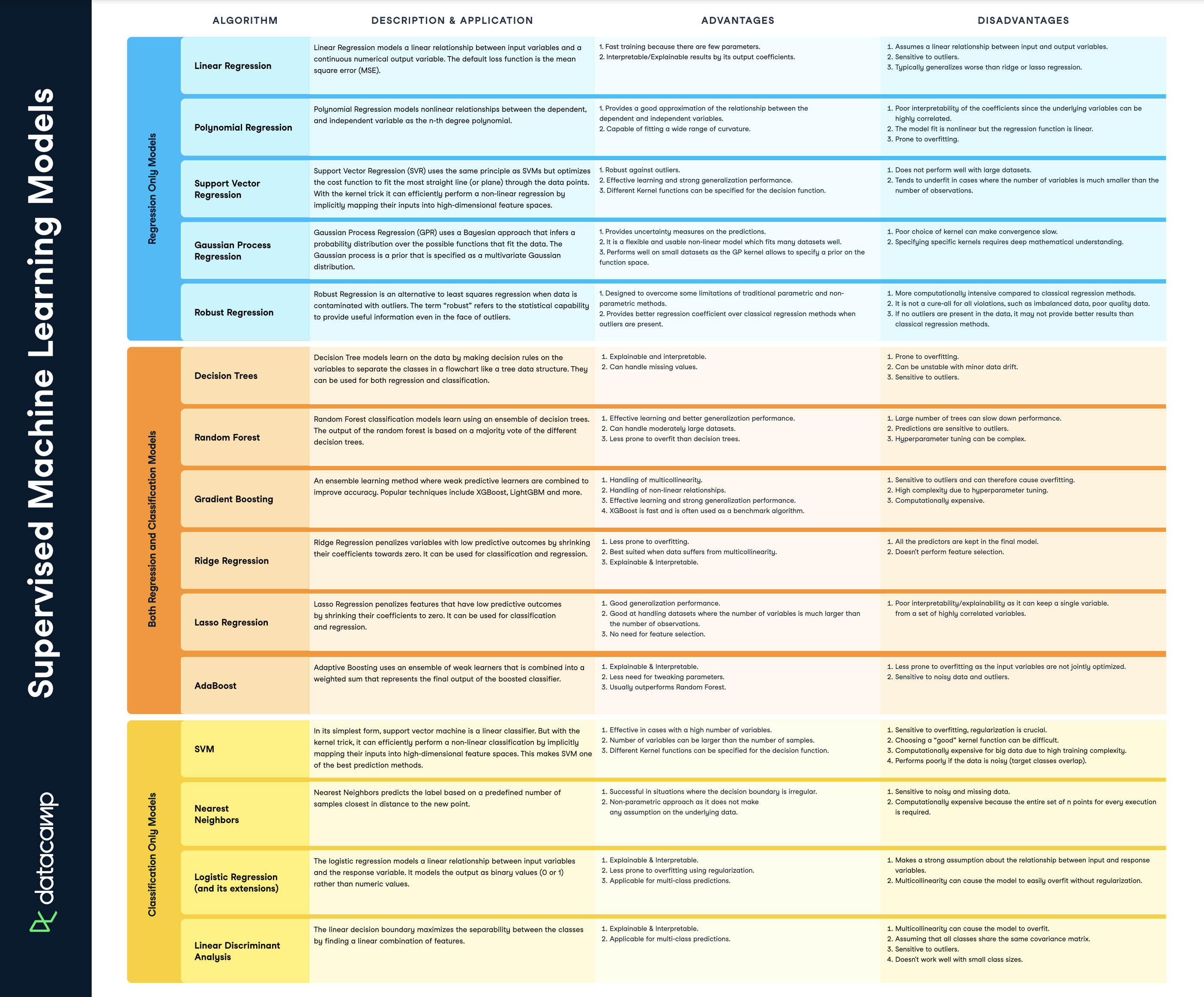
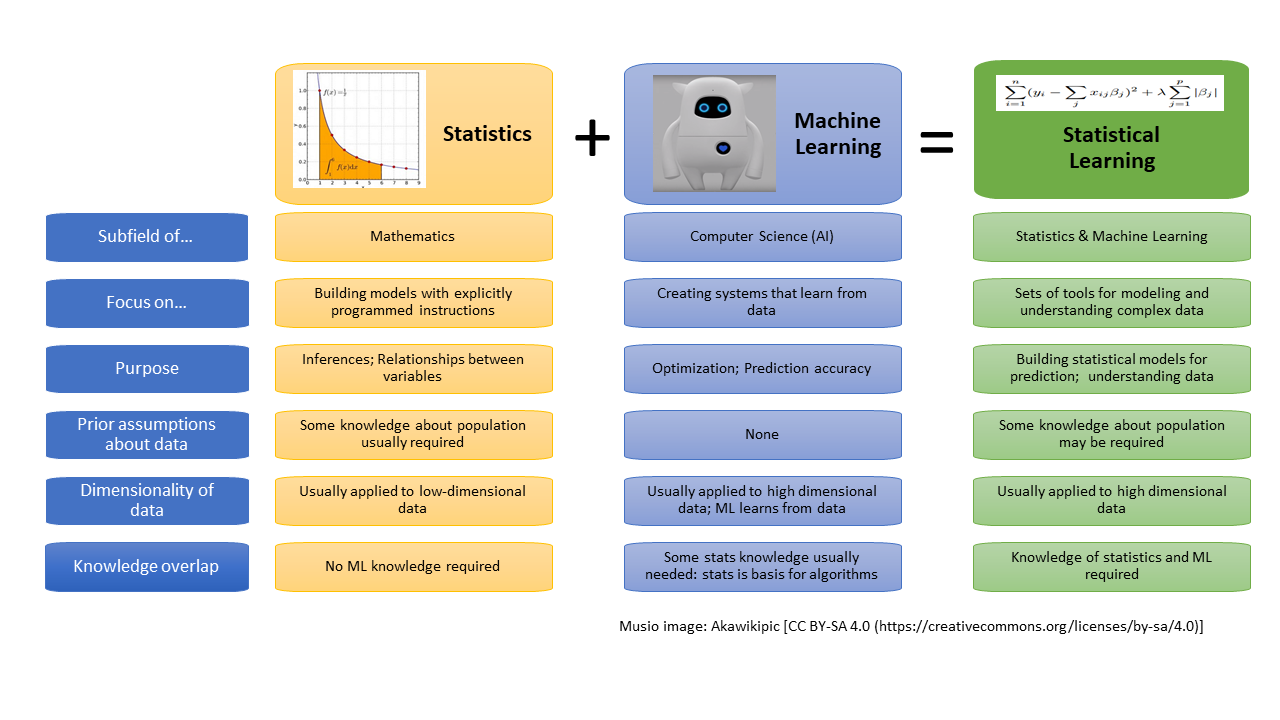
Download-link dieses Cheatsheets: [datacamp.com](https://www.datacamp.com/cheat-sheet/)


Einfach für ein oder zwei Parameter…
Nicht einfach für >> 2 Parameter…
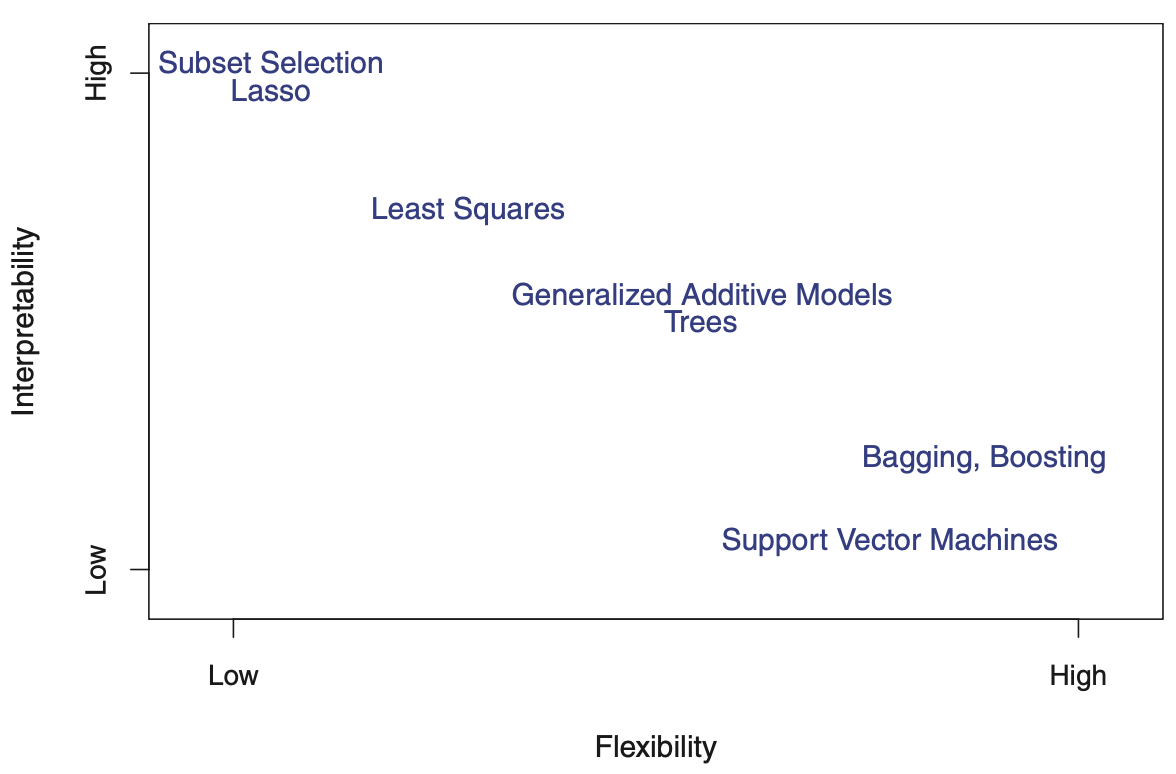
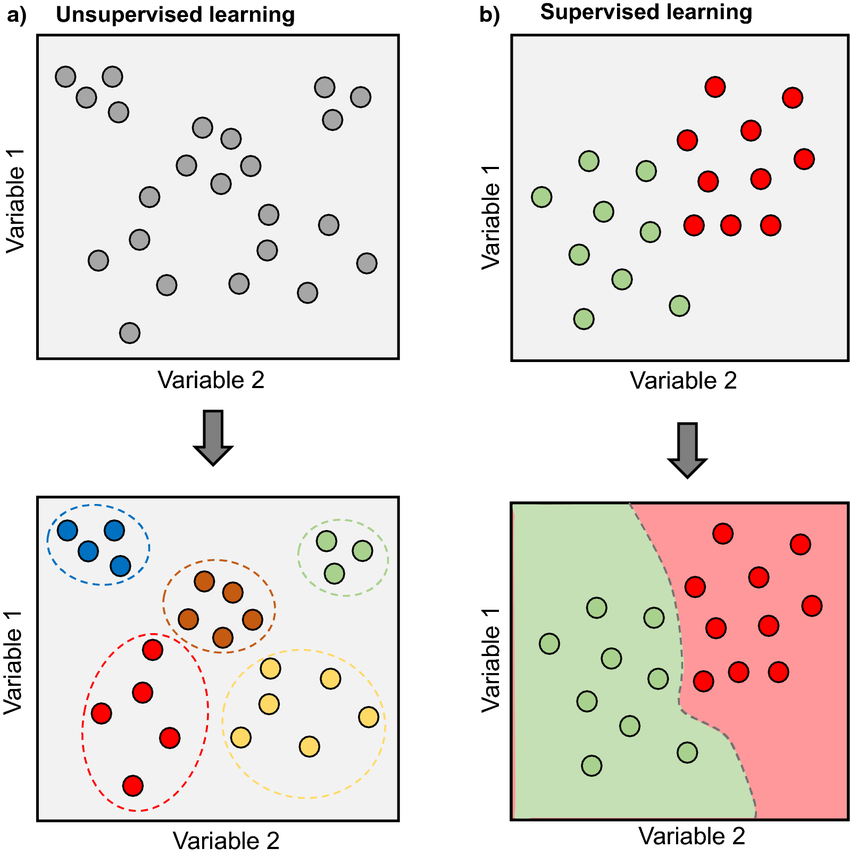
Bildquelle: James et al. (2013): Introduction to Statistical Learning
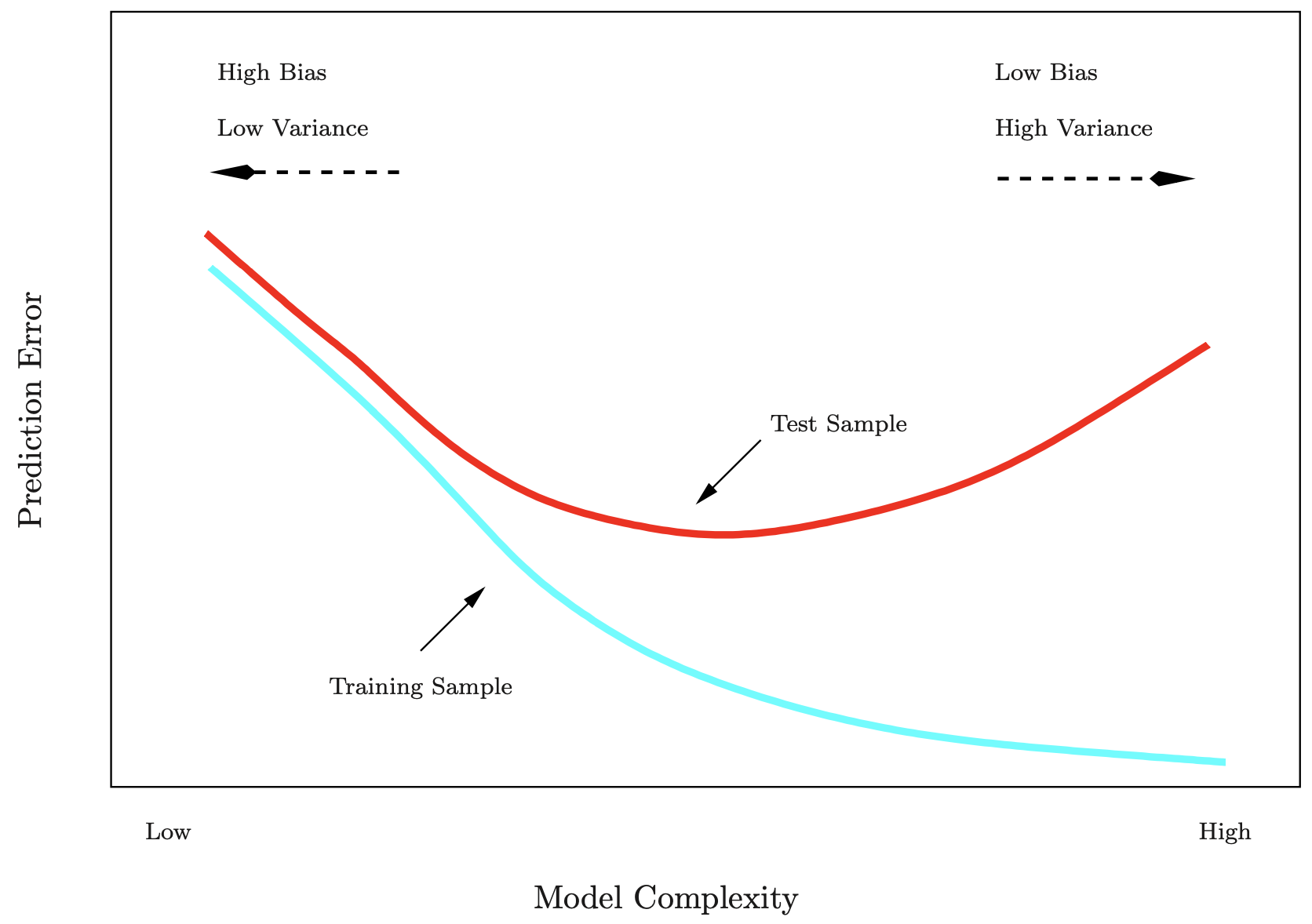
Die Trainingsfehlerrate (\(MSE_{train}\)) unterscheidet sich oft erheblich von der Testfehlerrate (\(MSE_{test}\)). Insbesondere bei sehr flexiblen Modellen kann die Trainingsfehlerrate die Testfehlerrate drastisch unterschätzen.
Bildquelle: James et al. (2013): Introduction to Statistical Learning

Bildquelle: James et al. (2013): Introduction to Statistical Learning
MSE einer einzelnen (schwarz) vs mehrfachen Aufteilung

Bildquelle: James et al. (2013): Introduction to Statistical Learning

Bildquelle: James et al. (2013): Introduction to Statistical Learning

Bildquelle: http://www.saedsayad.com/logistic_regression.htm
![]()
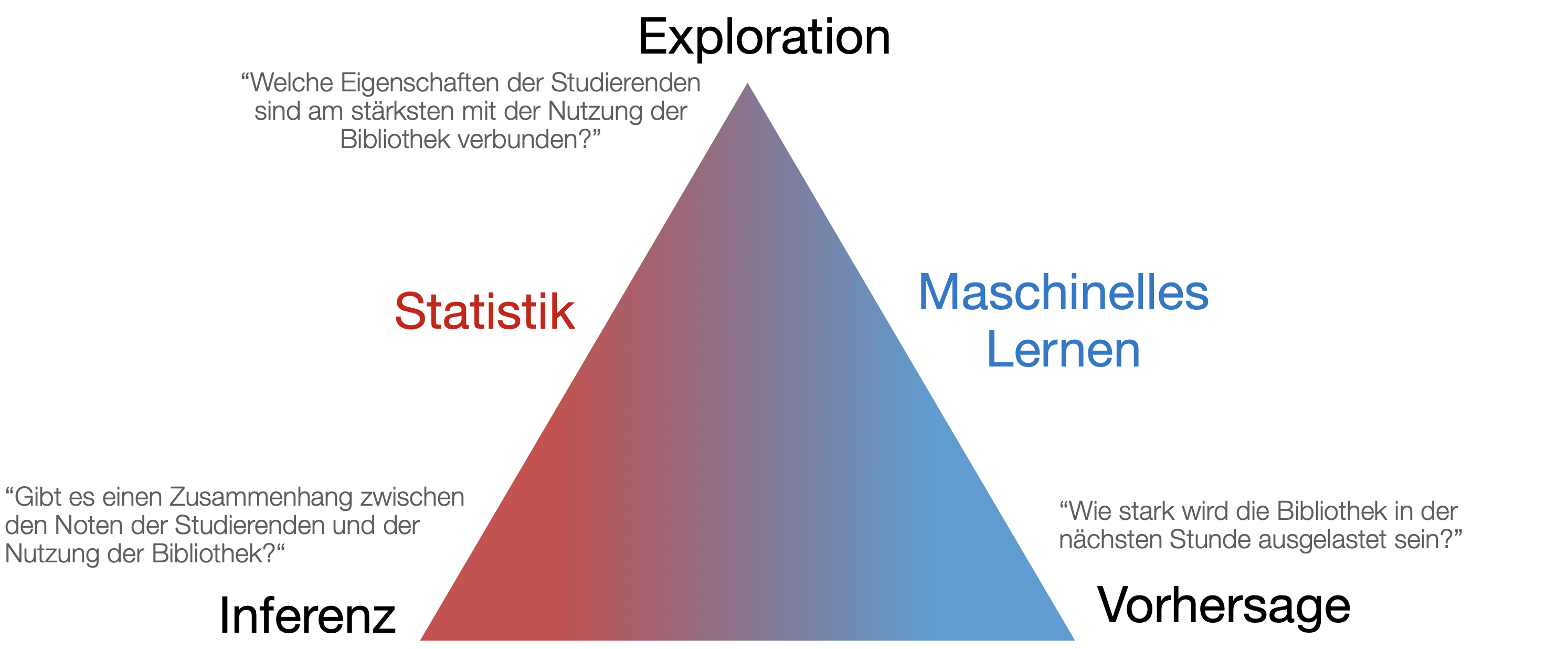
Können wir anhand der Flossenlänge die Artzugehörigkeit (‘Adélie’ oder ‘Gentoo’) bestimmen?
![]()





![]()
Call:
glm(formula = species ~ flipper_length_mm, family = "binomial",
data = penguins_sub)
Deviance Residuals:
Min 1Q Median 3Q Max
-2.60000 -0.00584 -0.00023 0.01513 1.91868
Coefficients:
Estimate Std. Error z value Pr(>|z|)
(Intercept) -147.0506 37.3471 -3.937 8.24e-05 ***
flipper_length_mm 0.7162 0.1805 3.967 7.27e-05 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
(Dispersion parameter for binomial family taken to be 1)
Null deviance: 364.612 on 264 degrees of freedom
Residual deviance: 20.887 on 263 degrees of freedom
AIC: 24.887
Number of Fisher Scoring iterations: 10Hier interessieren uns jetzt primär nur die Koeffizienten.
penguins_sub |>
mutate(
species_num = case_when(species == "Gentoo" ~ 1, .default = 0),
pred = predict(log_reg, type = "response")) |>
ggplot(aes(x = flipper_length_mm, y = pred)) +
geom_point(aes(y = species_num)) +
geom_line() +
geom_point(data = data.frame(fl = fl, pred_fl = pred_fl),
mapping = aes(x = fl, y = pred_fl), colour = "red", size = 2.5) +
geom_hline(yintercept = 0.5, linetype = 2) +
ylim(0,1) +
ylab("Probability") +
theme_light()
![]()


Dann testen Sie doch Ihr Wissen in folgendem Abschlussquiz…
![]()
Bei weiteren Fragen: saskia.otto(at)uni-hamburg.de

Diese Arbeit is lizenziert unter einer Creative Commons Attribution-ShareAlike 4.0 International License mit Ausnahme der entliehenen und mit Quellenangabe versehenen Abbildungen.

