
Resampling Techniken
DS3 - Explorative Datenanalyse & Data Mining
Universität Hamburg, IMF
Wintersemester 2023/2024
Lernziele
![]()
Am Ende dieser VL- und Übungseinheit werden Sie
- das sog. Bootstrap-Verfahrens auf reale Datensätze anwenden können, um Konfidenzintervalle für Punktschätzungen zu erstellen.
- wissen, wie das Bootstrap-Verfahren funktioniert, insbesondere wie Stichproben MIT Zurücklegen aus einer vorhandenen Stichprobe gezogen werden.
- das Konzepts der Permutation von Beobachtungen kennen und wissen, wie Permutationstests auf verschiedene Arten von Daten anzuwenden sind, um Hypothesen über Populationsparameter zu testen.
- in der Lage sein, die Ergebnisse von Permutationstests zu interpretieren und zu verstehen, wie statistische Signifikanz in diesem Kontext definiert ist.
- Permutationstests mit anderen Hypothesentestverfahren zu vergleichen und die Vor- und Nachteile jeder Methode zu verstehen.
Unser Thema heute

Grafik von Nina Garman (Pixabay)
Bootstrapping
Intervallschätzung | 1
Zur Erinnerung ein Beispiel aus DS2
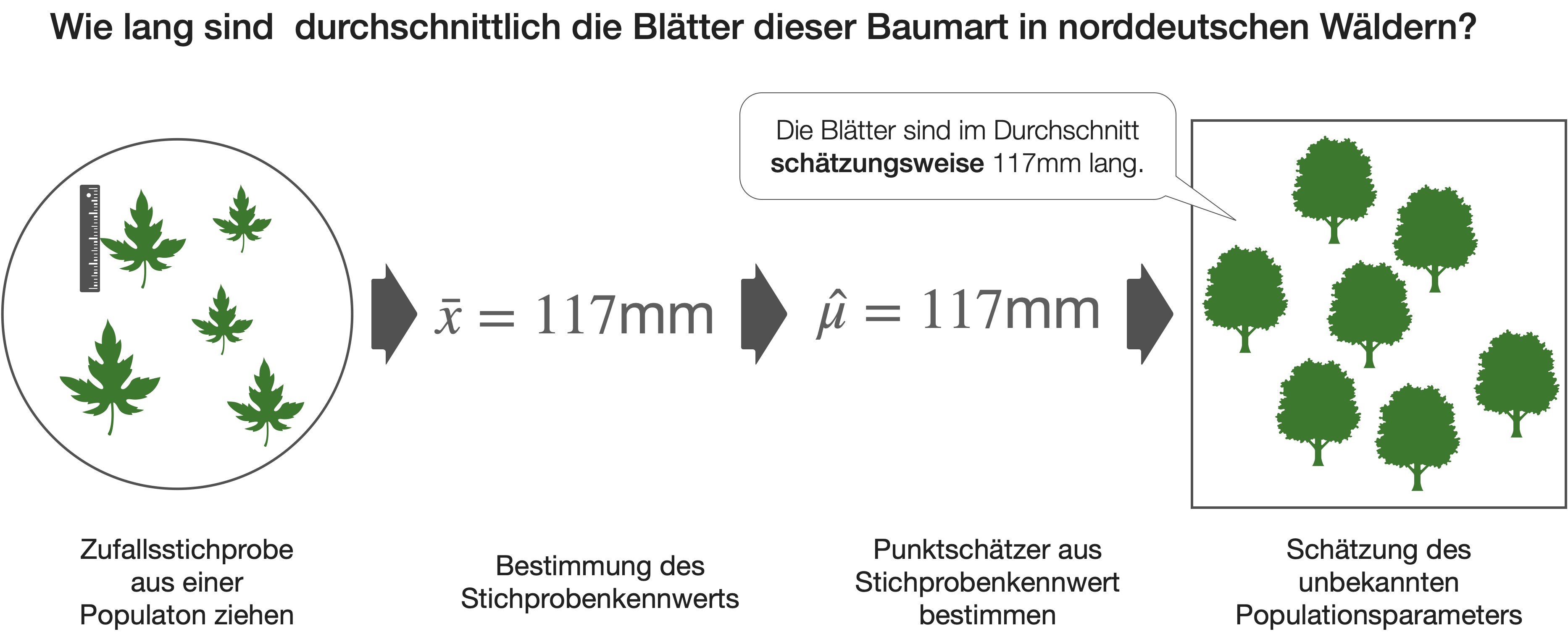
- Wie präzise ist diese Schätzung von 117mm?
- Kann es denn sein, dass der wahre Populationsmittelwert auch 100mm oder 140mm ist und wir einfach Pech mit der Probe hatten?
- In welchem Bereich liegt der wahre Mittelwert höchstwahrscheinlich?
Intervallschätzung | 2
Zur Erinnerung ein Beispiel aus DS2



Bootstrapping | Berechnung
→ Wir sind uns nun zu 95% sicher, dass der wahre Mittelwert im Bereich 111.4 - 112.4 liegt.
Bootstrapping | Vergleich

Bootstrapping | ‘boot’ Paket
Statt der manuellen Berechnung können wir die boot() Funktion aus dem gleichnamigen R Paket verwenden:
boot() Funktion im 'boot' Paket
- Die Syntax der Funktion ist recht einfach:
boot(data, statistic, R)datarepräsentiert den Vektor aus dem die Stichproben gezogen werden.statisticsteht für die Funktion, die pro Iteration angewendet werden soll, in unserem Fall für die Berechnung des Mittelwerts.Rdefiniert die Anzahl der Wiederholungsstichproben.
Interpretation | ‘boot’ Paket
Konfidenzintervalle | ‘boot’ Paket
BOOTSTRAP CONFIDENCE INTERVAL CALCULATIONS
Based on 1000 bootstrap replicates
CALL :
boot.ci(boot.out = boot_results)
Intervals :
Level Normal Basic
95% (111.4, 112.4 ) (111.4, 112.3 )
Level Percentile BCa
95% (111.4, 112.4 ) (111.5, 112.5 )
Calculations and Intervals on Original ScaleNormal: parametrisches KI, das auf dem Standardfehler des Mittelwerts und dem Stichprobenumfang basiertPercentile: das sog. Bootstrap-Perzentil-Intervall = Quantil aus den Bootstrap-SchätzungenBCa: angepasstes Bootstrap-Perzentil-Intervall
Schätzung von KI für Regressionsparameter
Wenn Annahmen nicht erfüllt sind
Code
df$res <- residuals(mod_lm)
df$fit <- fitted(mod_lm)
p1 <- ggplot(df, aes(y)) +
geom_histogram(bins = 10, fill = "grey50", colour = "grey10") +
ggtitle("Histogramm von Y")
p2 <- ggplot(df, aes(x, y)) + geom_point() +
geom_smooth(method = "lm", se = TRUE) +
ggtitle("Beziehung Y ~ X")
p3 <- ggplot(df, aes(res)) +
geom_histogram(bins = 10, fill = "grey50", colour = "grey10") +
ggtitle("Histogramm der Residuen")
p4 <- ggplot(df, aes(fit, res)) + geom_point() +
geom_hline(yintercept = 0) +
ggtitle("Residuen vs. fitted")
gridExtra::grid.arrange(p1, p2, p3, p4)
Estimate Std. Error t value Pr(>|t|)
(Intercept) -55.960944 22.550127 -2.481624 1.761662e-02
x 8.135234 1.464779 5.553899 2.329342e-06- Der Steigungsparameter b der Stichprobe als Punktschätzer für die Population beträgt 8.1.
- Gegeben, das die Daten normalverteilt und varianzhomogen sind → können wir uns zu 95 % sicher sein, dass bei einer Wiederholung der Datenerhebung die Regressionssteigung für diese neuen Daten zwischen 5.3 und 11.0 liegen würde.
Schätzung von KI für Regressionsparameter
Bootstrapping
set.seed(32)
it <- 10000
boot_b <- numeric(it)
for (i in 1:it){
n <- nrow(df)
indices <- sample(1:n, replace = T)
y_sample <- df$y[indices]
x_sample <- df$x[indices]
model <- lm(y_sample ~ x_sample)
boot_b[i] <- coef(model)[2]
}
quantile(boot_b,c(0.025,0.975)) 2.5% 97.5%
4.663306 11.757071 → Der Konfidenzbereich liegt nun zwischen 4.7 und 11.8.

Permutationstest
Beispiel 1: Zwei-Stichproben-Vergleich
Schneckenrennen
Unterscheiden sich zwei Schneckenarten in ihrer Laufgeschwindigkeit (in m/Stunde)?

Zwei-Stichproben-Vergleich | Daten
A <- c(4,2,7,9,2,8)
B <- c(7,10,9,5,8,11)
Rennen <- data.frame(
Art = c(rep("A", 6), rep("B", 6)),
Geschw = c(A,B)
)
Rennen |>
group_by(Art) |>
summarise(
Mittelwert = mean(Geschw),
Standardabweichung = sd(Geschw)
)# A tibble: 2 × 3
Art Mittelwert Standardabweichung
<chr> <dbl> <dbl>
1 A 5.33 3.08
2 B 8.33 2.16
Zwei-Stichproben-Vergleich | Verteilung

Korrelation | Permutation 3

[1] 5394[1] 0.5394- INTERPRETATION: die Wahrscheinlichkeit, dass die beobachteten Daten unter der Annahme der H0 auftreten, liegt bei 54 %. Wir können daher die H0 nicht ablehnen, es gibt keine signifikante Korrelation.
Beispiel 3: ANCOVA
Schnabellänge bei Adélie Pinguinen (Insel Dream)
![]()
Call:
lm(formula = body_mass_g ~ flipper_length_mm + sex, data = penguin_subs)
Residuals:
Min 1Q Median 3Q Max
-524.73 -186.57 6.13 128.46 716.22
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 696.634 1112.928 0.626 0.5341
flipper_length_mm 14.095 5.918 2.382 0.0209 *
sexmale 643.629 76.015 8.467 2.34e-11 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 267.3 on 52 degrees of freedom
Multiple R-squared: 0.6585, Adjusted R-squared: 0.6454
F-statistic: 50.13 on 2 and 52 DF, p-value: 7.387e-13
ANCOVA | Permutation 1
![]()
Wir extrahieren zuerst die t- und F-Statistiken aus der summary() bzw. drop1() Funktion.
ANCOVA | Permutation 2
![]()
ANCOVA | Permutation 2
![]()
Wir schreiben die Schleife
set.seed(123)
it <- 10000 # 10000 Iterationen
mystats_flipper <- numeric(it)
mystats_sex <- numeric(it)
for (i in 1:it){
# Schleifenkörper
df <- penguin_subs
df$body_mass_g_shuffled <- sample(df$body_mass_g)
mod <- lm(body_mass_g_shuffled ~ flipper_length_mm + sex, df)
mystats_flipper[i] <- summary(mod)$coefficients[2, "t value"]
mystats_sex[i] <- drop1(mod, test = "F")$`F value`[3]
}ANCOVA | Permutation 3
![]()
Verteilung der Teststatistiken

INTERPRETATION: die Wahrscheinlichkeit, dass die beobachteten Daten unter der Annahme der H0 auftreten, liegt bei beiden Kovariaten unter 5 %. Wir können daher heweils die H0 ablehnen, es gibt einen signifikanten Effekt beider Variablen.
Fragen..??

Total konfus?
Buchkapitel zum Nachlesen
- The R Book von M.J. Crawley:
- Kapitel 8.12 Bootstrap
- Wikipedia zu Bootstrap (https://en.wikipedia.org/wiki/Bootstrapping_(statistics))
- Dokumentation des ‘coin’ Pakets (https://cran.r-project.org/web/packages/coin/vignettes/coin.pdf)
Übungsaufgabe
 r
r
Übung
![]()
- Aufgaben im Übungsskript DS3_06_Uebungen_Resampling.Rmd mit abschließendem Quiz in Moodle (zuhause VOR der Übung)
- Gegebenenfalls Anwendung der Resampling-Techniken in Ihrer Fallstudie.
- WÄHREND der Übungsstunde: Besprechung der Lösung und Fragenrunde
R Notebook und Datensätze sind im Moodlekurs (Woche 6) zu finden.
Total gelangweilt?

Dann testen Sie doch Ihr Wissen in folgendem Abschlussquiz…
Abschlussquiz
![]()
Bei weiteren Fragen: saskia.otto(at)uni-hamburg.de

Diese Arbeit is lizenziert unter einer Creative Commons Attribution-ShareAlike 4.0 International License mit Ausnahme der entliehenen und mit Quellenangabe versehenen Abbildungen.