Lineares Modell mit Kovariate(n) & fixem Faktor
DS3 - Explorative Datenanalyse & Data Mining
Universität Hamburg, IMF
Wintersemester 2023/2024
Lernziele
![]()
Am Ende dieser VL- und Übungseinheit werden Sie
- wissen, was die ANCOVA mit einer Regression und ANOVA verbindet bzw. davon unterscheidet.
- die Gründe für die Verwendung einer ANCOVA und ihre Anwendungsgebiete kennen.
- zwischen abhängiger Variable, unabhängiger kategorialer Variable (Faktor) und Kovariate (kontinuierliche Variable) unterscheiden können und die Rolle jeder Variable im ANCOVA-Modell verstehen.
- gelernt haben, wie man ein ANCOVA-Modell in R erstellt und spezifiziert, einschließlich der Einbeziehung von Interaktionstermen, und die Ergebnisse interpretiert.
- den Ablauf einer Modellselektion vertieft haben.
- das Prinzip der Dummy-Variablen kennengelernt haben.
Kovariate & fixen Faktor: Kovarianzanalyse

Die Regressionsgleichung
Bsp.: Gewicht in Abhängigkeit von Alter und Geschlecht
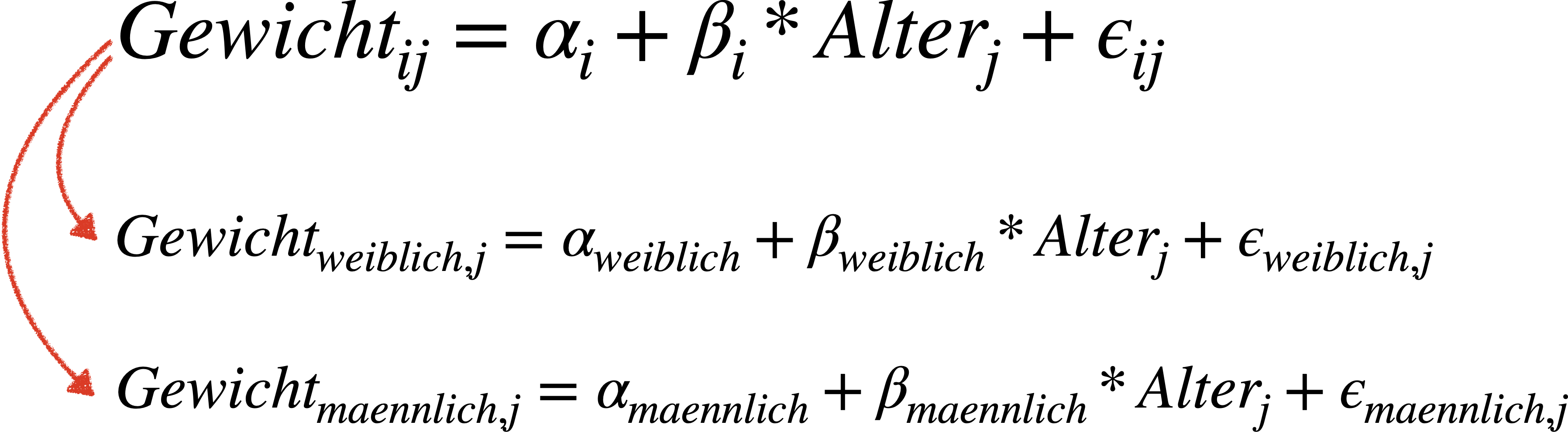
Hybrid aus ANOVA und linearer Regression
Bsp.: Gewicht in Abhängigkeit von Alter und Geschlecht

6 mögliche Modelle
Bsp.: Gewicht in Abhängigkeit von Alter und Geschlecht
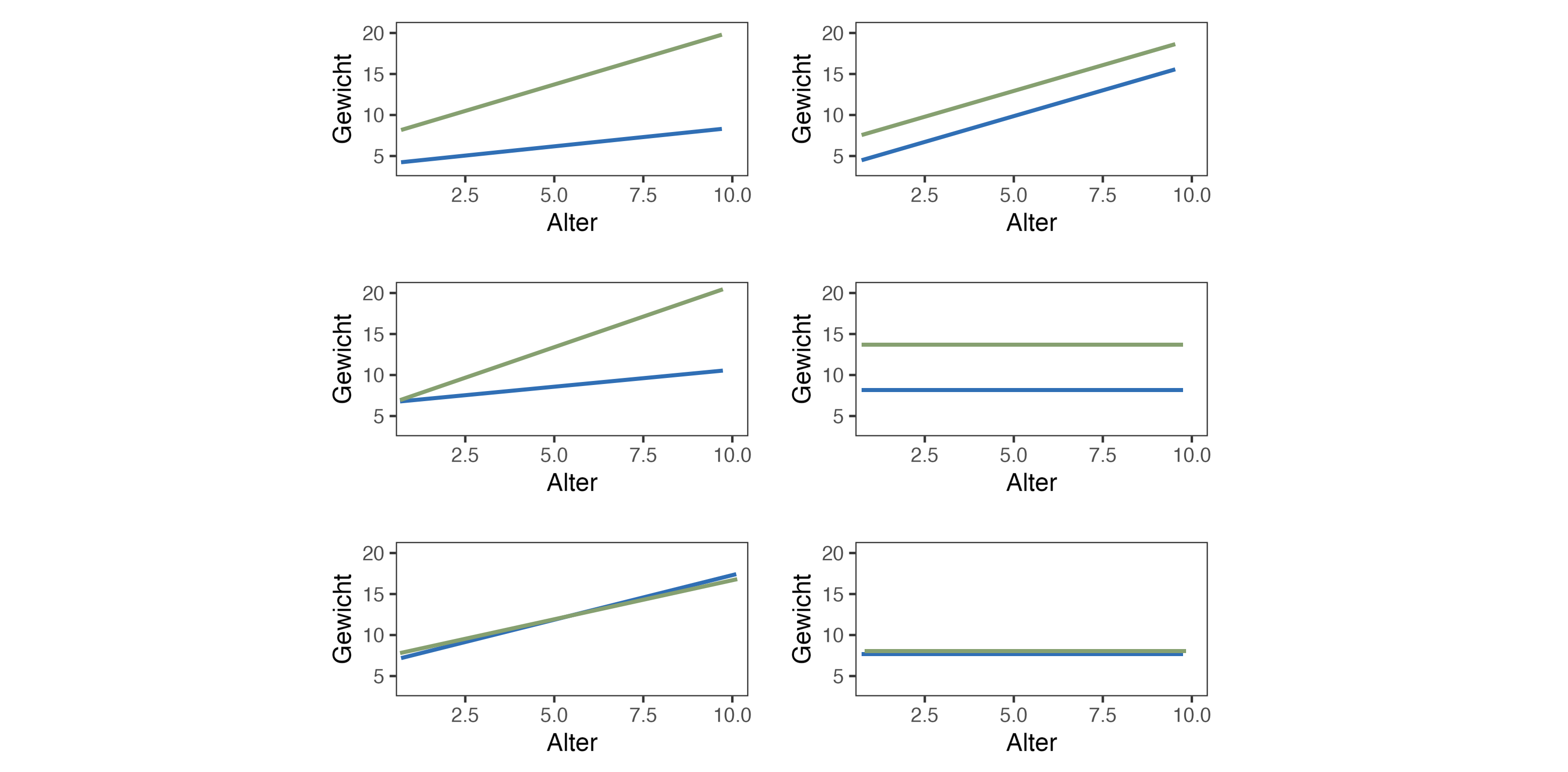
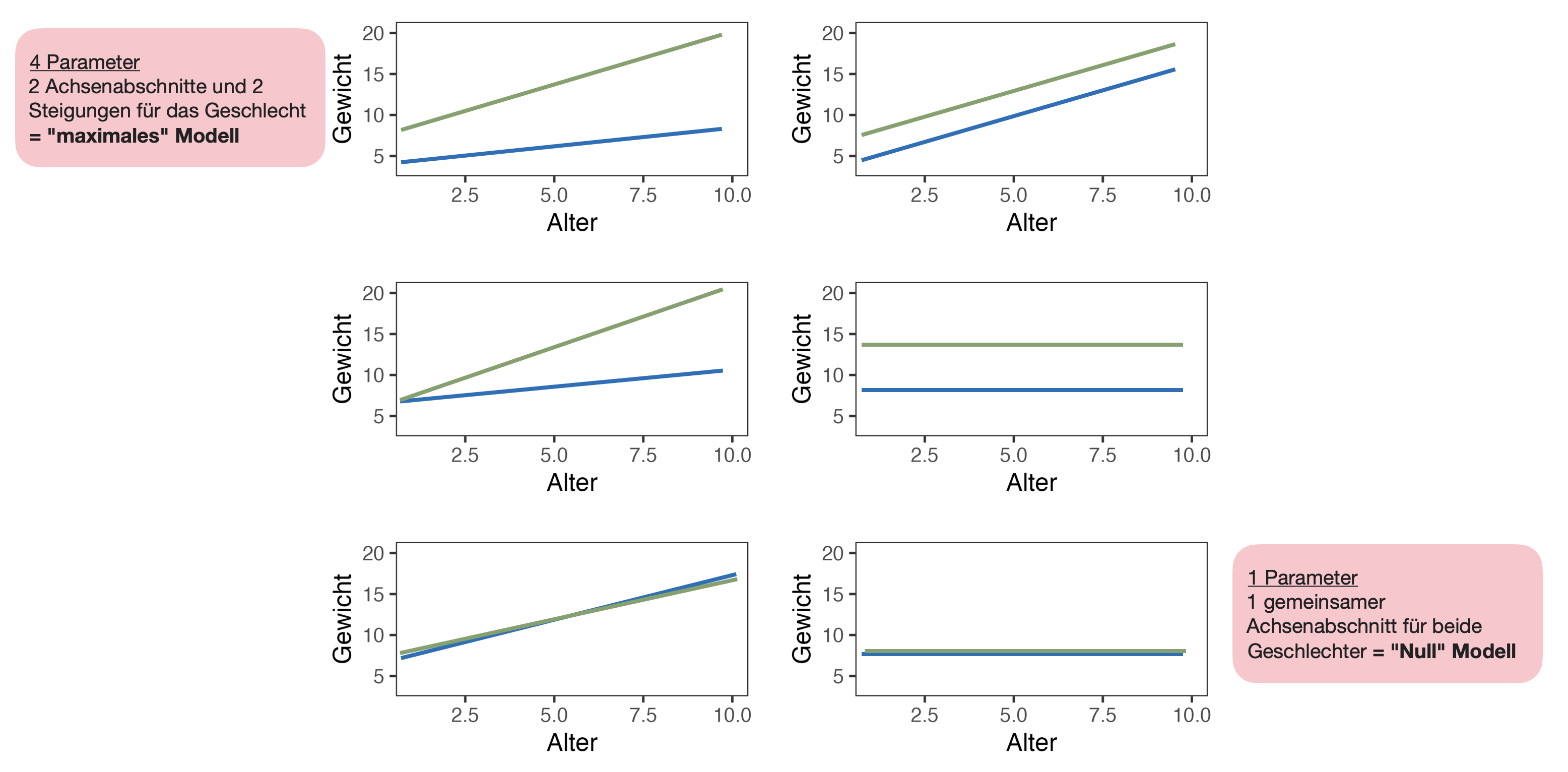
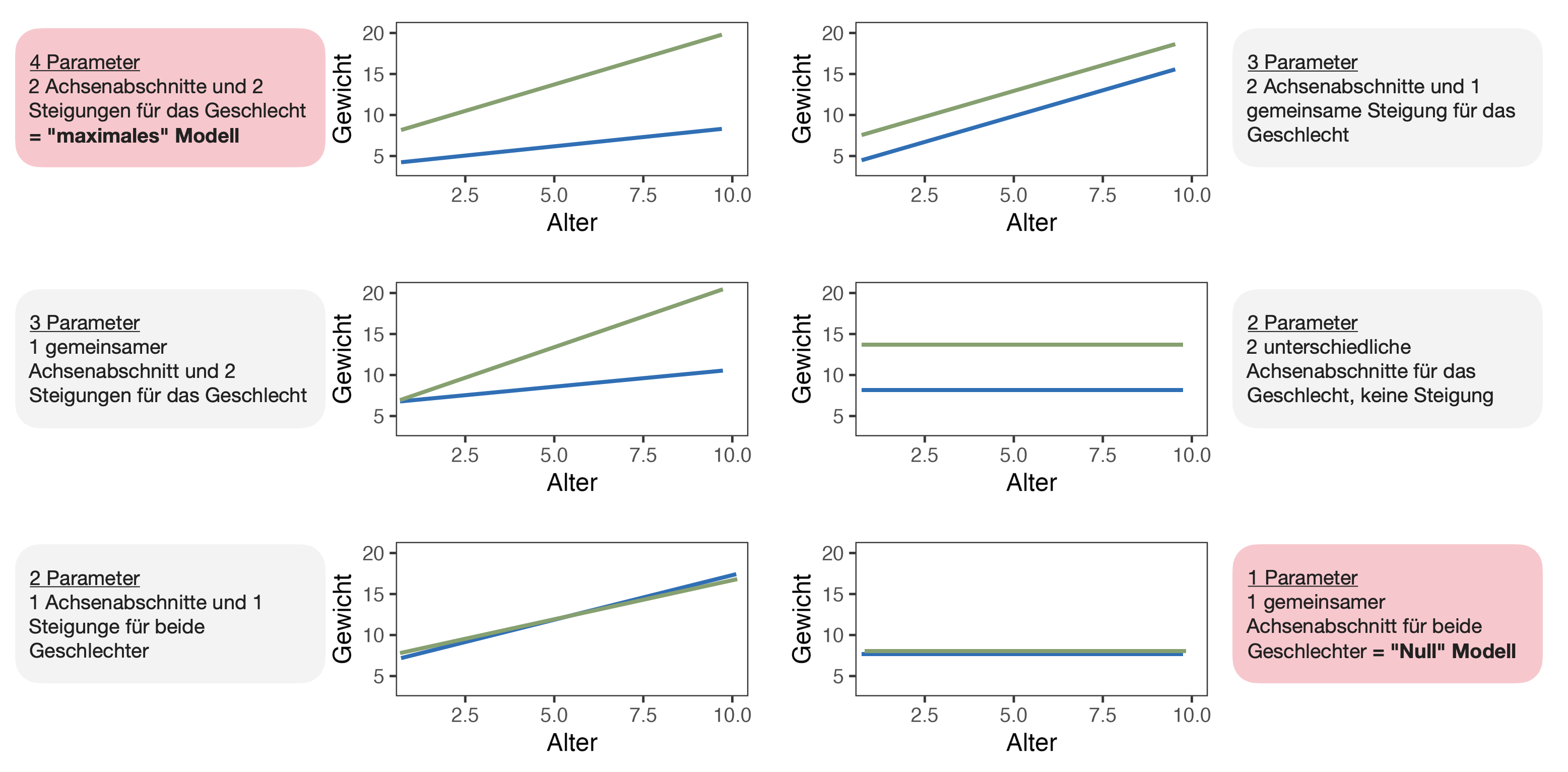
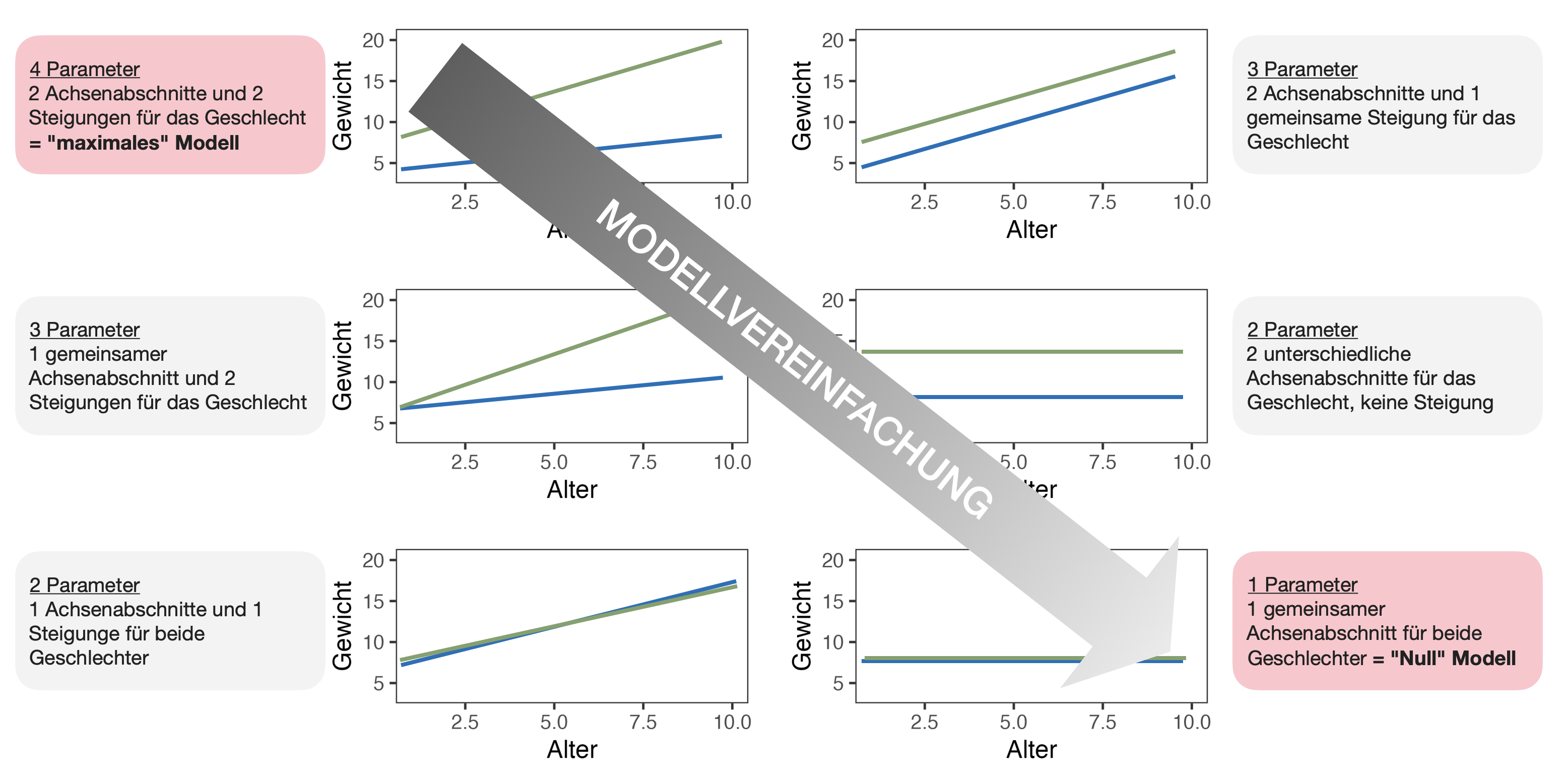
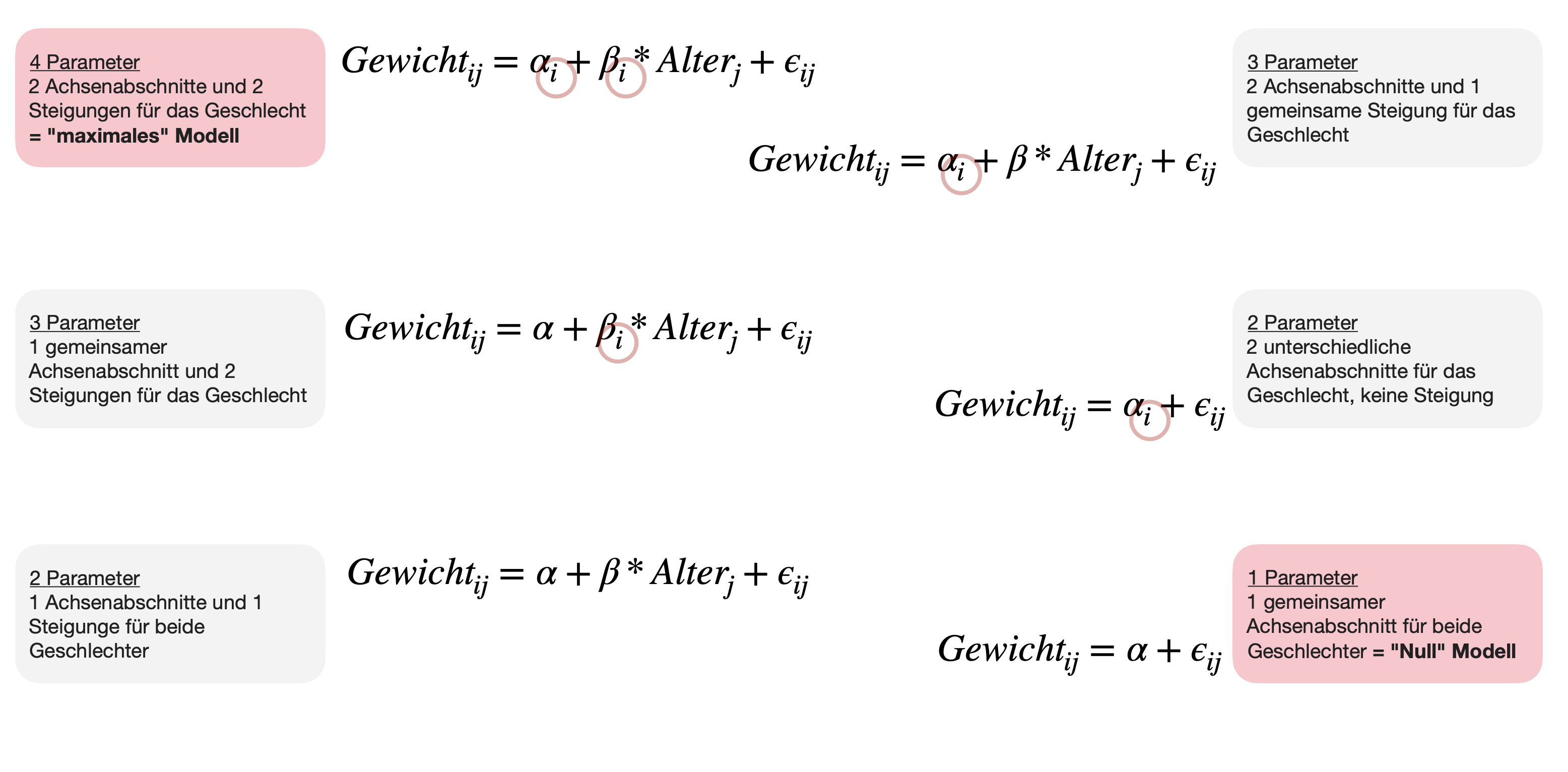
Herangehensweise in R
![]()
- Lineare Regression (Y ~ X) für jede Faktorstufe mittels
lm()Funktion. - Schätzung der Koeffizienten für jede Faktorstufe im maximalen Modell.
- Vereinfachung des Modells:
- Wir passen das komplizierteste Modell zuerst an und validieren es.
- Dann vereinfachen wir es mit Hilfe eines Auswahlkriteriums wie einem F-Test oder dem AIC
- bis ein minimal adäquates Modell übrig bleibt (bei dem alle Parameter signifikant von Null verschieden sind), welches wir auch noch mal validieren.
- R-Funktionen für Modellvergleich:
- F-Test →
drop1(mod_full, test = "F")oderanova(mod_full, mod_red)(Modelle müssen verschachtelt sein) - AIC →
AIC(mod_full, mod_red)bzw.step(mod_full)(automatische Auswahl)
- F-Test →
Längen-Gewichts-Beziehungen | 1
Ein typisches Beispiel für eine Beziehung, die nicht mit einer linearen Grafik dargestellt werden kann, ist in der Biologie die Beziehung zwischen dem Gewicht (W) eines Tieres (z.B. eines Fisches) und seiner Länge (L).
Für die meisten Arten folgt sie einer 2-Parameter Powerfunktion: W = aL^{b}
Beispiel: Königslachse
Längen und Gewichte für Königslachse von drei Orten in Argentinien (Daten sind aus dem FSA)*. 

*Originalartikel zum Datensatz: Soto, D., I. Arismendi, C. Di Prinzio, & F. Jara (2007): Establishment of Chinook Salmon (Oncorhynchus tshawytscha) in Pacific basins of southern South America and its potential ecosystem implications. Revista Chilena d Historia Natural, 80:81-98. Link
Längen-Gewichts-Beziehungen | 2
Logarithmus-Transformation
Die Potenzfunktion wird linear, wenn man sie doppelt logarithmiert!
Beispiel: Königslachse
\begin{align} W &= aL^{b} \\ ln(W) &= ln(aL^{b})\\ ln(W) &= ln(a) + b*ln(L)\\ \Rightarrow Y &= a + b*X \end{align}

Königslachse | Fragestellung

- Frage 1: Unterscheiden sich die Lachse der 3 Beprobungsorte in ihrem durchschnittlichen Gewicht? →ANOVA
- Frage 2: Wie ist die Längen-Gewichts-Beziehung bei den gemessenen Königslachsen? →Regression
- Frage 3: Unterscheidet sich diese Beziehung zwischen Individuen der 3 Beprobungsorte (Río Petrohuyé, Lago Puyehue, Río Futaleufú en Argentina)? → Interaktion
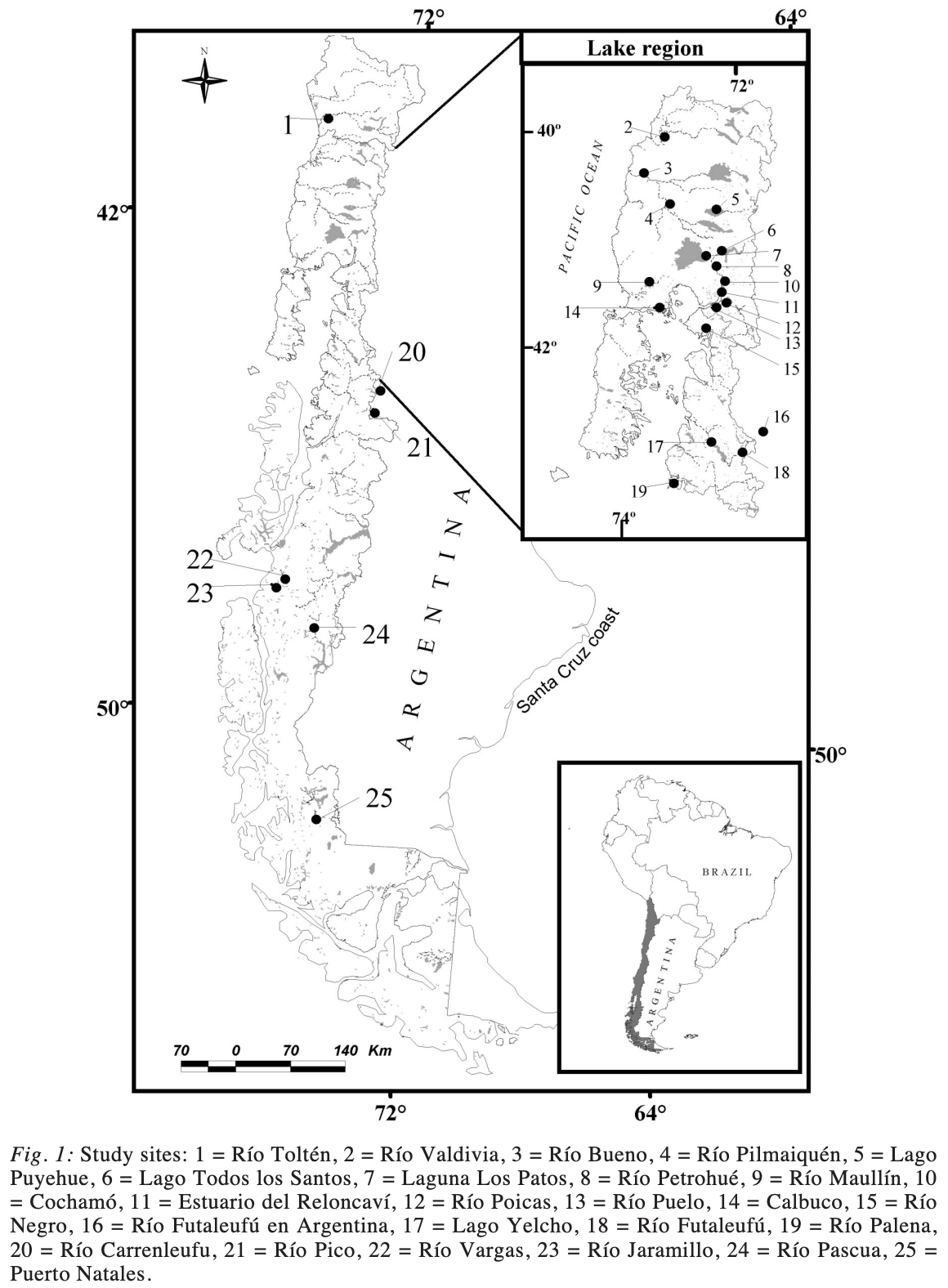
Aus Soto et al. (2007)
Königslachse | Das Maximalmodell
Wir starten mit dem Maximalmodell, welches
- den Beprobungsort (Faktor
loc= location), - die Länge (Kovariate
tl_ln= total length in cm, logarithmiert) und - den Interaktionsterm enthält.
- Unsere Antwortvariable ist
w_ln(=weight in kg, logarithmiert).
Validierung des Maximalmodells

Ergebnisse des Maximalmodells
Analysis of Variance Table
Response: w_ln
Df Sum Sq Mean Sq F value Pr(>F)
tl_ln 1 92.083 92.083 898.4819 < 2.2e-16 ***
loc 2 2.634 1.317 12.8526 1.005e-05 ***
tl_ln:loc 2 0.101 0.051 0.4932 0.612
Residuals 106 10.864 0.102
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1Single term deletions
Model:
w_ln ~ tl_ln + loc + tl_ln:loc
Df Sum of Sq RSS AIC F value Pr(>F)
<none> 10.864 -249.31
tl_ln:loc 2 0.1011 10.965 -252.27 0.4932 0.612Aus diesen beiden Funktionen können wir den p-Wert für den Faktor bzw. die Interaktion entnehmen!
Call:
lm(formula = w_ln ~ tl_ln + loc + tl_ln:loc, data = ChinookArg)
Residuals:
Min 1Q Median 3Q Max
-0.58273 -0.18471 -0.00186 0.13088 1.63620
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) -6.6750 1.5904 -4.197 5.64e-05 ***
tl_ln 1.9836 0.3530 5.619 1.56e-07 ***
locPetrohue -2.3957 3.1494 -0.761 0.449
locPuyehue -2.0696 1.6868 -1.227 0.223
tl_ln:locPetrohue 0.4795 0.6928 0.692 0.490
tl_ln:locPuyehue 0.3624 0.3793 0.955 0.342
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 0.3201 on 106 degrees of freedom
Multiple R-squared: 0.8972, Adjusted R-squared: 0.8924
F-statistic: 185 on 5 and 106 DF, p-value: < 2.2e-16Hieraus entnehmen wir den p-Wert für die Kovariate!
Modellreduktion | Interaktion
Können wir die Interaktion entfernen?
Vergleich volles und reduziertes Modells mittels anova()
Analysis of Variance Table
Model 1: w_ln ~ tl_ln + loc + tl_ln:loc
Model 2: w_ln ~ tl_ln + loc
Res.Df RSS Df Sum of Sq F Pr(>F)
1 106 10.864
2 108 10.965 -2 -0.1011 0.4932 0.612INTERPRETATION:
- Das vollere Modell ist NICHT signifikant besser (p = 0.612) als das reduzierte Modell.
- → Wir können den Interaktionsterm entfernen.
Modellreduktion | Faktor & Kovariate
Können wir den Faktor oder die Kovariate jetzt auch noch entfernen?
Single term deletions
Model:
w_ln ~ tl_ln + loc
Df Sum of Sq RSS AIC F value Pr(>F)
<none> 10.965 -252.267
tl_ln 1 34.175 45.140 -95.779 336.615 < 2.2e-16 ***
loc 2 2.634 13.599 -232.151 12.974 8.917e-06 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1INTERPRETATION:
- Nein, in beiden Fällen ist das ‘vollere’ Modell, die ANCOVA ohne-Interaktion, signifikant besser (p < 0.05 jeweils) als die beiden reduzierten ANOVA- und Regressionsmodelle.
- Auch der AIC ist beim volleren Modell am niedrigsten → beide Terme bleiben im Modell.
Automatische Modellselektion
Wir können auch die (automatische) Modellauswahl basierend auf dem AIC mittels step() Funktion durchführen:
Start: AIC=-249.3
w_ln ~ tl_ln + loc + tl_ln:loc
Df Sum of Sq RSS AIC
- tl_ln:loc 2 0.1011 10.965 -252.27
<none> 10.864 -249.31
Step: AIC=-252.27
w_ln ~ tl_ln + loc
Df Sum of Sq RSS AIC
<none> 10.965 -252.267
- loc 2 2.634 13.599 -232.151
- tl_ln 1 34.175 45.140 -95.779
Call:
lm(formula = w_ln ~ tl_ln + loc, data = ChinookArg)
Coefficients:
(Intercept) tl_ln locPetrohue locPuyehue
-8.1217 2.3049 -0.2281 -0.4570 - Zum Schluss wird das ‘optimale’ Modell zusammengefasst.
- Auch hier wird das Modell mit beiden Variablen ohne Interaktion als ‘bestes’ Modell gewählt.
Validierung des finalen Modells
par(mfrow = c(2,3))
# Standardplots
plot(mod_no_interaction, which = c(1,2,4))
# Residuen und gefittete Werte extrahieren
res <- residuals(mod_no_interaction)
fit <- fitted(mod_no_interaction)
# Residuen vs. Location
boxplot(res ~ ChinookArg$loc)
# Gefittete vs. beobachtete Y
plot(x = fit, y = ChinookArg$w_ln)
abline(a = 0, b = 1)
Finales Modell | ANOVA Komponente 1
![]()
Achtung, die Reihenfolge in der Formel zählt!
Analysis of Variance Table
Response: w_ln
Df Sum Sq Mean Sq F value Pr(>F)
tl_ln 1 92.083 92.083 906.994 < 2.2e-16 ***
loc 2 2.634 1.317 12.974 8.917e-06 ***
Residuals 108 10.965 0.102
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1Analysis of Variance Table
Response: w_ln
Df Sum Sq Mean Sq F value Pr(>F)
loc 2 60.542 30.271 298.16 < 2.2e-16 ***
tl_ln 1 34.175 34.175 336.61 < 2.2e-16 ***
Residuals 108 10.965 0.102
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1- In R wirkt sich die Reihenfolge, in der die Variablen in die Formel eingeben werden, auf die ANOVA-Ergebnistabelle aus (einschließlich p-Werte), wenn das Design unausgewogen ist.
aov()undanova()erzeugen “sequentielle” Quadratsummen (“Typ-I-Quadratsummen”), während sie gleichzeitig die Hierarchie beachten.- Hierarchie bedeutet, dass der Achsenabschnitt zuerst vor allen anderen Termen angepasst wird, die Haupteffekte als nächstes und die Wechselwirkungen immer als letztes.
- Die meisten anderen Statistikpakete verwenden stattdessen die marginale Anpassung von Termen (“Typ III Summe der Quadrate”). In diesem Fall spielt die Reihenfolge des Auftretens der Terme in der Formel keine Rolle, ebenso wenig wie die Hierarchie.
- Die erste Anordnung ergibt die Summenquadrate für loc “ohne” tl_ln und für tl_ln “nach” loc.
- Die zweite ergibt die Summenquadrate für tl_ln “ohne” loc und für loc “nach” tl_ln.
Finales Modell | ANOVA Komponente 2
- Lösung 1: Den Faktor ans Ende der Formel stellen (wenn es nur einen gibt) → wie in
mod_no_interaction - Lösung 2: Den p-Wert aus der
drop1(model, test = "F")Funktion entnehmen:
Single term deletions
Model:
w_ln ~ tl_ln + loc
Df Sum of Sq RSS AIC F value Pr(>F)
<none> 10.965 -252.267
tl_ln 1 34.175 45.140 -95.779 336.615 < 2.2e-16 ***
loc 2 2.634 13.599 -232.151 12.974 8.917e-06 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1Finales Modell | Regressionsgleichung 1
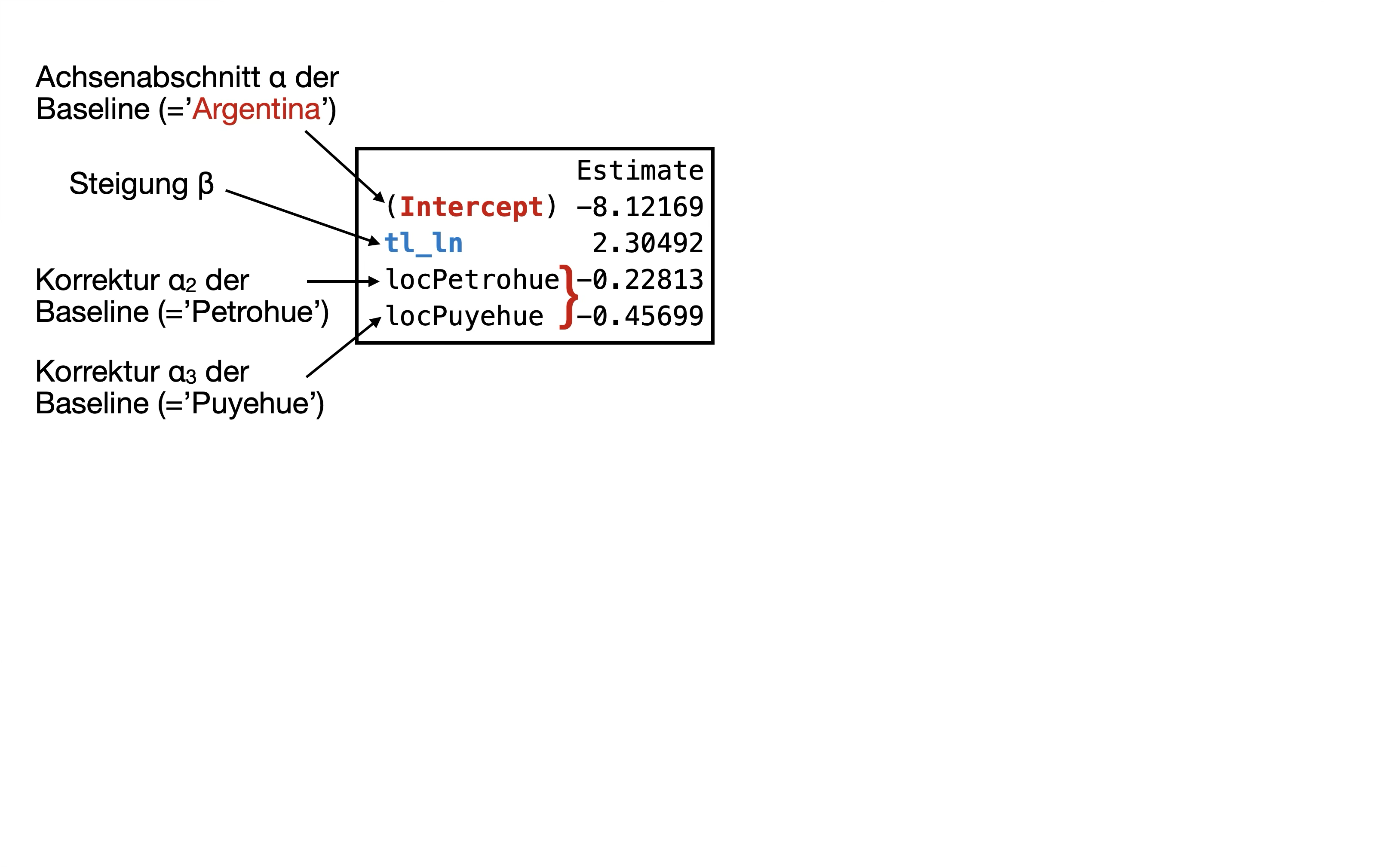
→ Wir haben ein 4-Parameter-Modell: 3 Achsenabschnitte, 1 Steigung
y_{ij}=\alpha_i+\beta*x_j + \epsilon_{ij}
Was sind… ?
- \alpha_{Argentina}, \alpha_{Petrohue}, \alpha_{Puyehue}
- und \beta
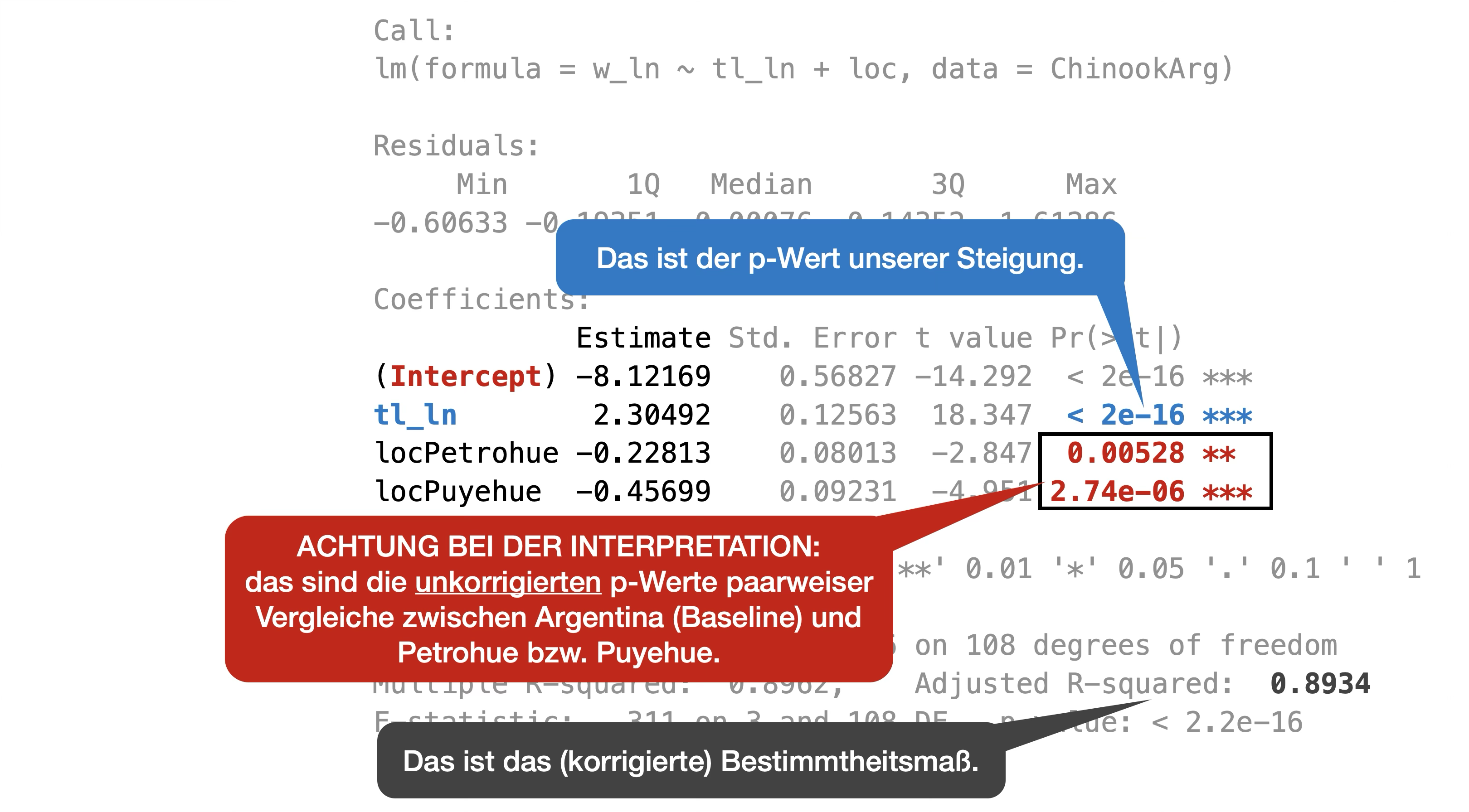
Finales Modell | Summary Output 1
Call:
lm(formula = w_ln ~ tl_ln + loc, data = ChinookArg)
Residuals:
Min 1Q Median 3Q Max
-0.60633 -0.19351 -0.00076 0.14352 1.61286
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) -8.12169 0.56827 -14.292 < 2e-16 ***
tl_ln 2.30492 0.12563 18.347 < 2e-16 ***
locPetrohue -0.22813 0.08013 -2.847 0.00528 **
locPuyehue -0.45699 0.09231 -4.951 2.74e-06 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 0.3186 on 108 degrees of freedom
Multiple R-squared: 0.8962, Adjusted R-squared: 0.8934
F-statistic: 311 on 3 and 108 DF, p-value: < 2.2e-16![]()
Finales Modell | Summary Output 2
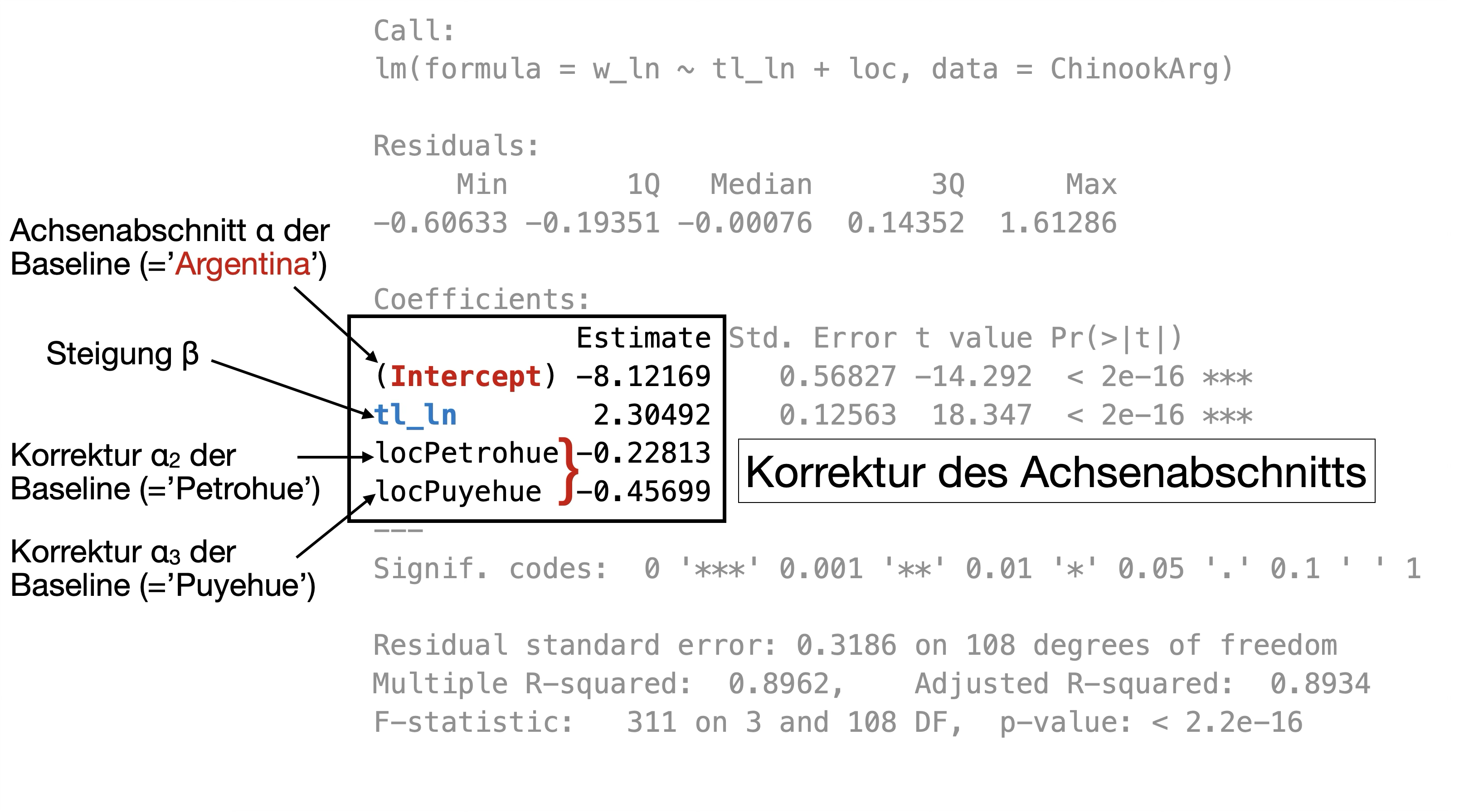
Finales Modell | Regressionsgleichung 2
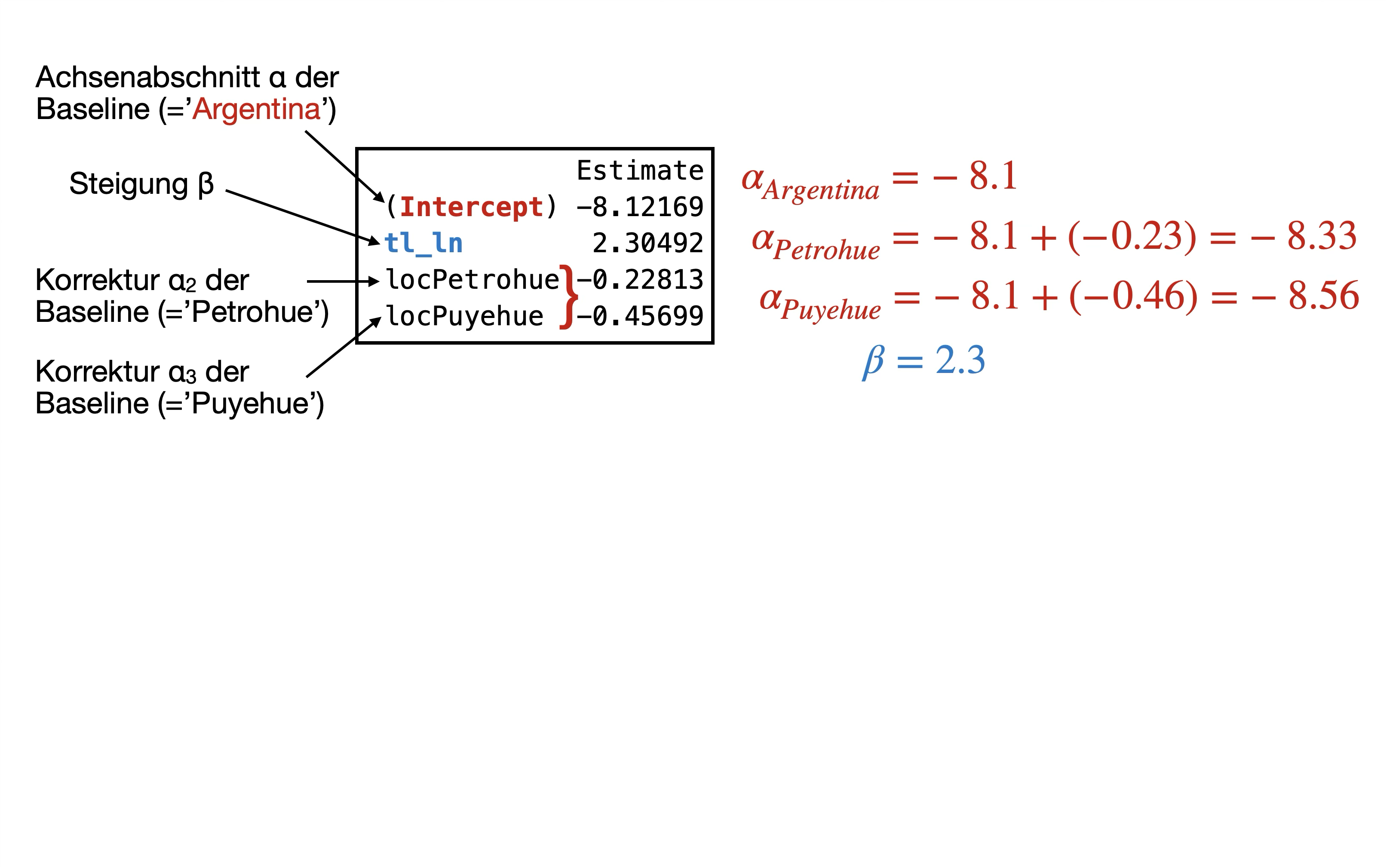
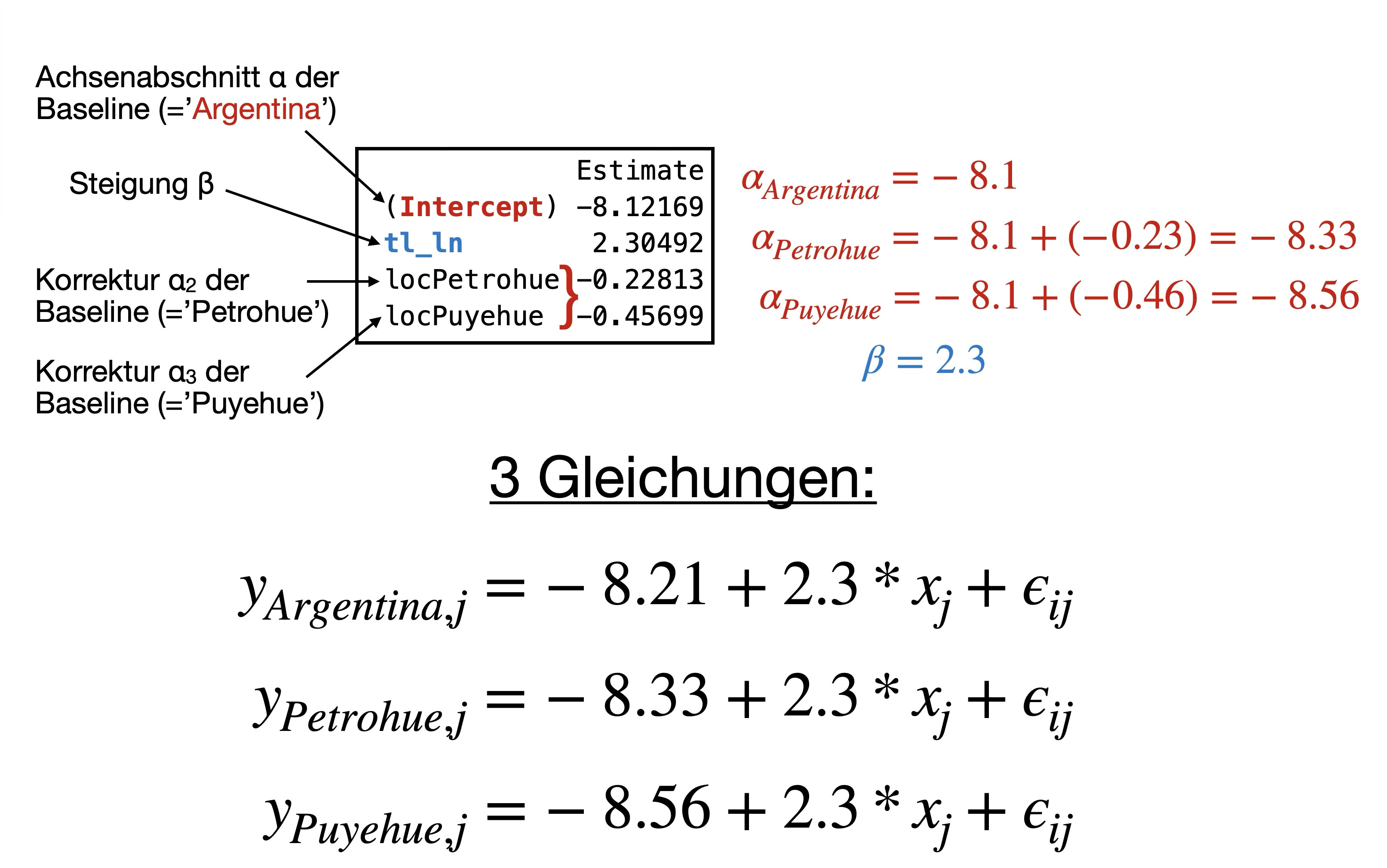
Interpretation des vollen Modells
R erstellt intern eine neue Gleichung mit den Dummy-Variablen:
\begin{align*} w\_nl_{loc,j} = a + a*loc_{Pet} + a*loc_{Puy} + b*length_j + \\ b*loc_{Pet}*length_j + b*loc_{Puy}*tl\_ln_j \end{align*}
- Argentina: -6.67 + -2.4*0 + -2.07*0 + 1.98*tl_ln + 0.48*0*tl_ln + 0.36*0*tl_ln = -6.67 + 1.98*tl_ln
- Petrohue: -6.67 + -2.4*1 + -2.07*0 + 1.98*tl_ln + 0.48*1*tl_ln + 0.36*0*tl_ln = -9.07 + 2.46*tl_ln
- Puyehue: -6.67 + -2.4*0 + -2.07*1 + 1.98*tl_ln + 0.48*0*tl_ln + 0.36*1*tl_ln = -8.74 + 2.34*tl_ln
Interpretation der verschachtelten ANOVA
Zurück zu unserem Seeigel-Experiment
![]()
Effekte des fixed Faktors (Seeigeldichte)
(Intercept) Treatment33 Treatment66 Treatment100
39.20 -20.20 -17.65 -37.90 - → Faktorstufe 0% ist in der intercept versteckt.
- → Bei z.B. Faktorstufe 33% ist eine durchschnittliche Fadenalgenbedeckung von 39.20-20.20 = 19% zu erwarten.
Zurück zum finalen Modell | Vorhersage
Code
# Gefittete Werte vom finalen und Max.modell speichern
ChinookArg$fit <- fitted(mod_no_interaction)
ChinookArg$fit_max <- fitted(mod_max)
# ggplot
ggplot(ChinookArg, aes(x = tl_ln, y = w_ln, colour = loc)) +
geom_point() +
scale_colour_manual(values =
c("forestgreen", "orange1", "deeppink4")) +
guides(colour = "none") +
geom_line(aes(x = tl_ln, y = fit), linewidth = 1.1) +
geom_line(aes(x = tl_ln, y = fit_max), linetype = 2, linewidth = 1.2, alpha = 0.5) +
geom_smooth(method = "lm", se = FALSE, linetype = 3, linewidth = 1.2, alpha = 0.5) +
labs(x = "ln(Länge)", y = "ln(Gewicht)",
subtitle = "Vergleich modellierte Werte: finales Modell (durchgängige Linie) vs. Max.modell (gestrichelt) vs. geom_smooth (gepunktet)")
- Y Werte lassen sich mit der Funktion
fitted()undpredict()berechnen. - Bei der
geom_smooth(method = "lm")Methode basieren die gefitteten Werte offensichtlich auf einer ANCOVA mit Interaktion → daher also nicht immer passend!
Zusammenfassung
Allgemeine lineare Modelle
![]()
- Regressions- und ANOVA/ANCOVA-Modelle
- Der Begriff “allgemein” bedeutet, dass sowohl kategoriale als auch metrische Prädiktoren (X) zulässig sind.
- Y ist eine metrische Variable.
- Annahmen: Normalverteilung für Y und Fehlerterme, Varianzhomogenität und Unabhängigkeit
- Schätzung der Parameter und Anpassung des Modells: Methode der kleinsten Quadrate (OLS) → entspricht der Maximum Likelihood (ML)-Schätzung, wenn die Annahmen zutreffen.
Überblick Formelschreibweisen

aus Crawley (2007)
Überblick Modelltypen

aus Crawley (2013)
DSB Cheatsheet: Basic Statistics with R

Enthält wichtigste Grundfunktionen zur Statistik und statistischen Modellierung
Ablaufprotokoll
![]()

Die Datei ist auf Moodle verfügbar.
Fragen..??

Total konfus?
Buchkapitel zum Nachlesen
- The R Book von M.J. Crawley:
- Kapitel 9 - Statistical Modelling
- Kapitel 12.1 - Analysis of covariance in R
- Experimental Design and Data Analysis for Biologists von G.P. Quinn & M.J. Keough:
- Kapitel 12 Analysis of covariance
Übungsaufgabe
Übung
![]()
- Zuhause (VOR der Übung): Aufgabe im Übungsskript DS3_05_Uebungen_MultipleRegression_ANCOVA.Rmd:
- Größenmessungen bei erwachsenen Pinguinen auf Nahrungssuche in der Nähe der Palmer Station, Antarktis
- Füllen Sie die Lücken im Code und führen Sie eine Modellselektion durch.
- Beantworten Sie die Fragen im Moodle-Quiz zur Aufgabe
- WÄHREND der Übungsstunde:
- Besprechung der Lösung
- Fragenrunde
R Notebook und Datensatz sind im Moodlekurs (Woche 5) zu finden.
Total gelangweilt?

Dann testen Sie doch Ihr Wissen in folgendem Abschlussquiz…
Abschlussquiz
![]()
Bei weiteren Fragen: saskia.otto(at)uni-hamburg.de

Diese Arbeit is lizenziert unter einer Creative Commons Attribution-ShareAlike 4.0 International License mit Ausnahme der entliehenen und mit Quellenangabe versehenen Abbildungen.