'data.frame': 80 obs. of 4 variables:
$ Treatment: int 100 100 100 100 100 100 100 100 100 100 ...
$ Patch : int 1 1 1 1 1 2 2 2 2 2 ...
$ Quadrat : int 1 2 3 4 5 1 2 3 4 5 ...
$ Algae : int 0 0 0 6 2 0 0 0 0 0 ...2-faktorielle Varianzanalyse: verschachteltes Design
DS3 - Explorative Datenanalyse & Data Mining
Universität Hamburg, IMF
Wintersemester 2023/2024
Lernziele
![]()
Am Ende dieser VL- und Übungseinheit werden Sie
- wissen, wie pseudoreplizierte Daten und Daten von verschachtelten bzw. hierarchischen Designs mithilfe einer Varianzanalyse analysiert werden können.
- eine alternative, bessere Variante zur Analyse der Fallstudiedaten (aus DS2) durchführen können..
- wissen, wie feste und zufällige Faktoren in die Berechnung der F-Werte einfließen
- 3 Varianten zur Berechnung einer mehrfaktoriellen, verschachtelten ANOVA kennen.
2-faktorielle Varianzanalyse mit verschachtelten Faktoren
-Theorie

Verschachtelte (hierarchische) Designs
![]()
- In der Ökologie wird Pseudoreplikation oft verursacht durch fehlende Replikation auf der richtigen Ebene des experimentellen Designs.
- Subsampling kann hier hilfreich sein.
- Häufig: ‘nested ANOVA’ mit zwei Faktoren
- Faktor A mit p Gruppen oder Stufen → fest oder zufällig, aber normalerweise fest
- Faktor B mit q Gruppen oder Ebenen innerhalb jeder Ebene von A (die Unterprobe) → in der Regel zufällig
Einfluss der Seeigelbeweidung im Korallenriff
![]()
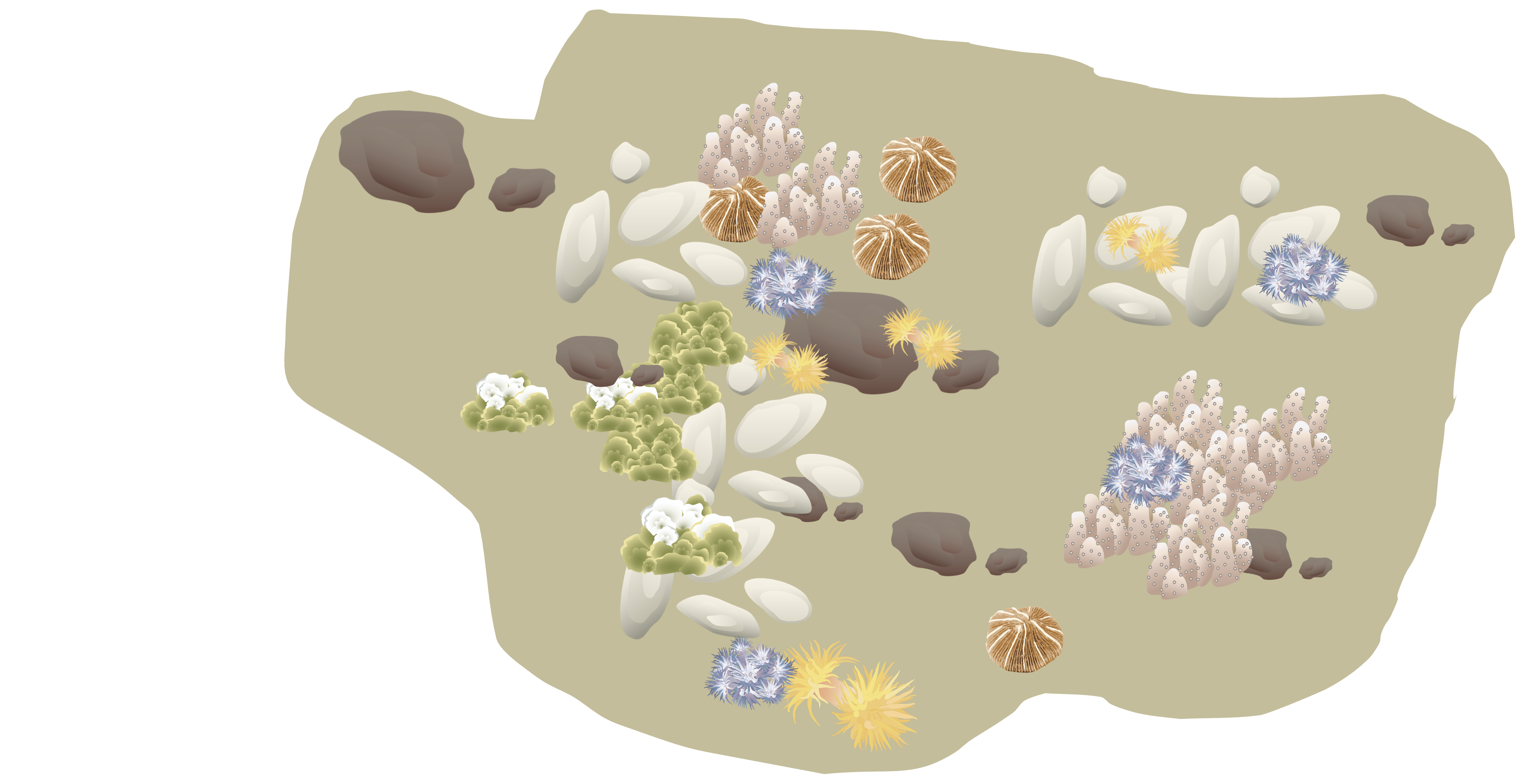
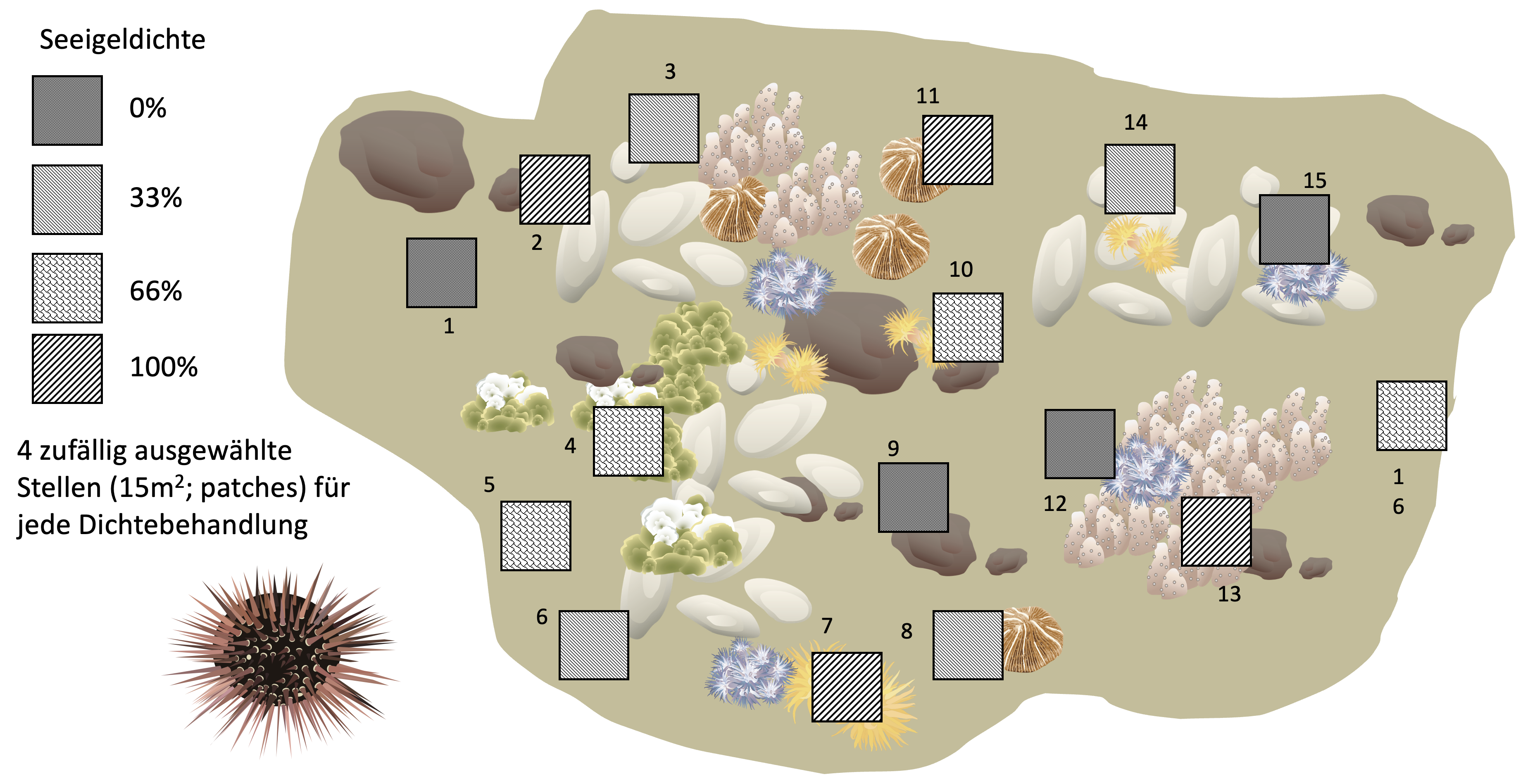
Beispiel ist aus Kapitel 9.1 in Quinn & Keough (2002): Experimental Design and Data Analysis for Biologists
- Andrew & Underwood (1993) manipulierten die Dichte von Seeigeln in der flachen subtidalen Region eines Standorts in der Nähe von Sydney, um die Auswirkungen auf den prozentualen Bewuchs mit Fadenalgen zu testen.
- Es gab vier Seeigelbehandlungen: keine Seeigel, 33% der ursprünglichen Dichte, 66% der ursprünglichen Dichte und 100% der ursprünglichen Dichte.
- Die Behandlungen wurden an vier verschiedenen Stellen (3-4 m^2 Flächen) pro Behandlung wiederholt, und der prozentuale Bewuchs mit Fadenalgen (Antwortvariable) wurde in fünf zufälligen Quadraten pro Stelle gemessen.
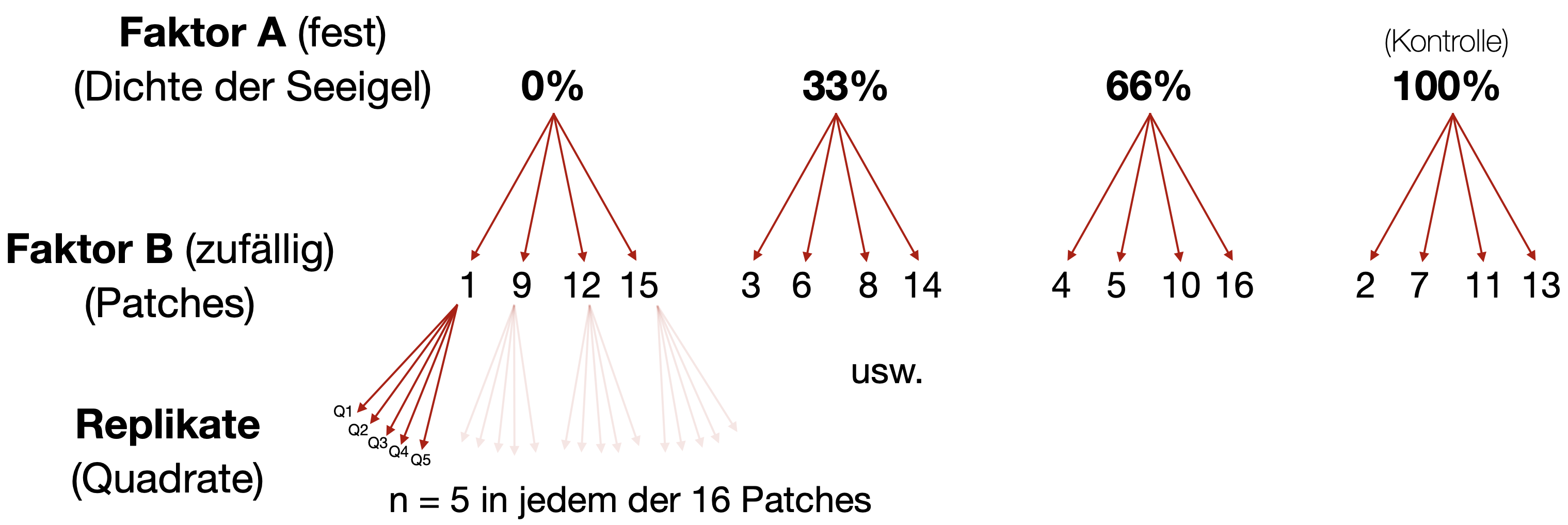
- Es handelt sich somit um ein verschachteltes Design mit Behandlung (fester Faktor), Stellen (im Engl. ‘patches’) innerhalb der Behandlung (zufälliger Faktor) und Quadraten als Replikate.
Seeigelbeweidung im Korallenriff
Das Design
![]()
Lineares ANOVA Model
![]()
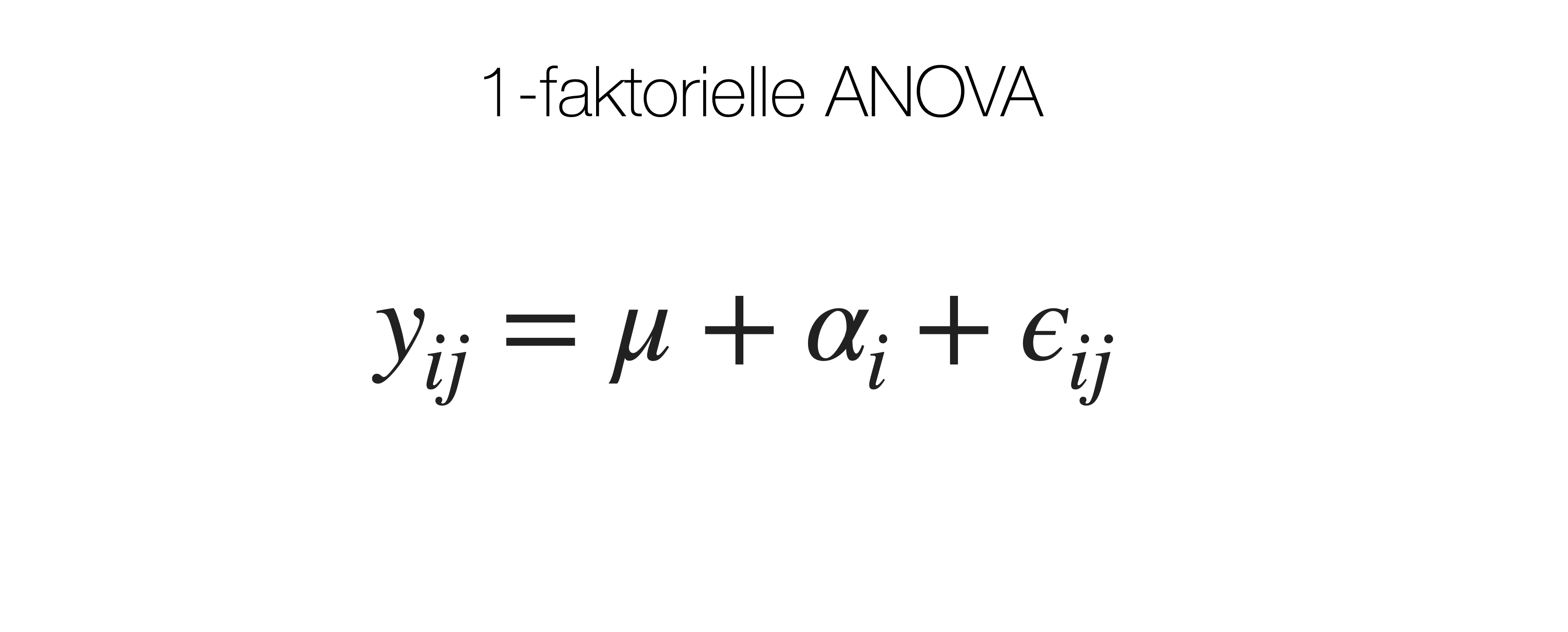
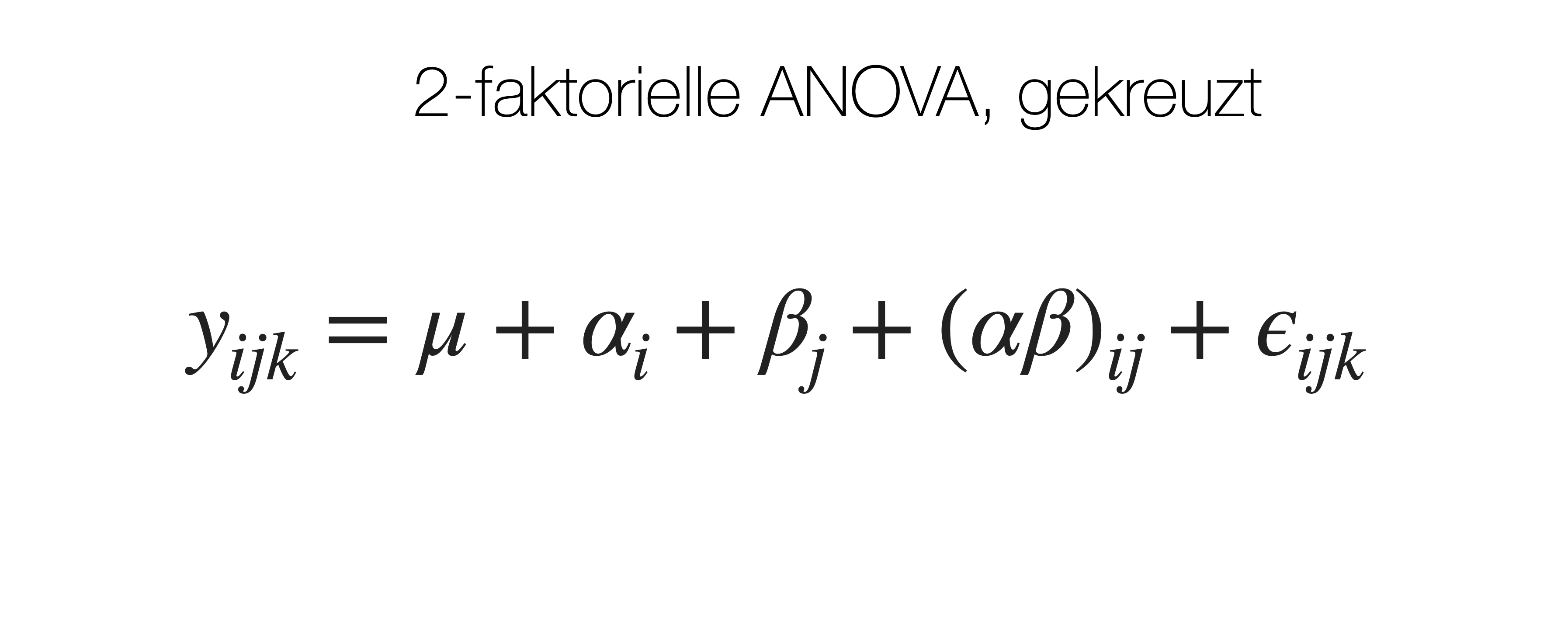


Varianzzerlegung


ANOVA Tabelle

Berechnung der F-Werte

Interpretation der Ergebnisse
![]()

\Rightarrow Die H0_A kann nicht abgelehnt werden: es gibt keine signifikanten Unterschiede in der Menge der Fadenalgen zwischen den verschiedenen Dichtestufen.
\Rightarrow Die H0_B kann abgelehnt werden: es gibt sign. Unterschiede zwischen den Patches innerhalb jeder Dichtestufe.
2-faktorielle Varianzanalyse mit verschachtelten Faktoren
-Durchführung in R
Datentyp
![]()
![]()
Beide Faktoren müssen in R auch als Faktor definiert sein.
Codierung
![]()
![]()
Der verschachtelte Faktor (hier ‘Patch’) muss für jede Stufe eine einzigartige ID haben!
# A tibble: 16 × 3
# Groups: Treatment, Patch [16]
Treatment Patch n
<fct> <fct> <int>
1 0 1 5
2 0 2 5
3 0 3 5
4 0 4 5
5 33 1 5
6 33 2 5
7 33 3 5
8 33 4 5
9 66 1 5
10 66 2 5
11 66 3 5
12 66 4 5
13 100 1 5
14 100 2 5
15 100 3 5
16 100 4 5# A tibble: 16 × 3
# Groups: Treatment, Patch_newIDs [16]
Treatment Patch_newIDs n
<fct> <fct> <int>
1 0 0:1 5
2 0 0:2 5
3 0 0:3 5
4 0 0:4 5
5 33 33:1 5
6 33 33:2 5
7 33 33:3 5
8 33 33:4 5
9 66 66:1 5
10 66 66:2 5
11 66 66:3 5
12 66 66:4 5
13 100 100:1 5
14 100 100:2 5
15 100 100:3 5
16 100 100:4 5Exploration
![]()
![]()

Durchführung der ANOVA in R
![]()
Verschiedene Möglichkeiten
Variante 1
aov() Funktion mit Angabe des verschachtelten (festen) Faktors in der Formel:
aov(y ~ A/B/C)
wobei A/B/C das gleiche ist wie
A + B %in% A + C %in% B %in% A- Antwortvariable y
- Fester Faktor A
- Der zweite Faktor B ist eingebettet (‘nested’) in A → für R fest
- Der dritte Faktor C ist eingebettet (‘nested’) in Faktor B, eingebettet in A → für R fest
Variante 2
aov() Funktion mit Angabe des zufälligen (verschachtelten) Faktors in der Formel:
aov(y ~ A + Error(B))
- fester Faktor A
- Faktor B wird hier als zufälliger Faktor definiert → bei eindeutigen IDs erkennt R die Verschachtelung automatisch.
Variante 3
Als lineares gemischtes Effektmodell (LME) mit dem R Paket ‘nlme’ (oder ‘lme4’):
nlme:lme(fixed = y ~ a, random = ~1 | b)
fixed:
- Hier werden die festen, unverschachtelten Faktoren als feste Komponente des Modells definiert. Die Formelschreibweise ist hier wie bekannt.
random:
- Hier werden die zufälligen, verschachtelten Faktoren definiert.
- Der Name der Antwortvariable wird in der Zufallskomponente vor dem Tildezeichen weggelassen.
- Nach dem Achsenabschnitt folgt der vertikale Balken |, der als “bei folgender räumlicher Anordnung der Zufallsvariablen” zu lesen ist.
- In diesem Beispiel ist Faktor C eingebettet in Faktor B und dieser wiederum in A.
Variante 1
![]()
![]()
Df Sum Sq Mean Sq F value Pr(>F)
Treatment 3 14429 4810 16.108 6.58e-08 ***
Treatment:Patch_newIDs 12 21242 1770 5.928 8.32e-07 ***
Residuals 64 19110 299
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1Vor- und Nachteile
- Wir erhalten die vollständige Tabelle bei einem 2-faktoriellen, verschachtelte Design.
- Aber: da der verschachtelte Faktor als fester Faktor in R interpretiert wird, ist die Berechnung des F-Werts inkorrekt (anstelle der MS_{B(A)} sind im Nenner die MS_{Residuen}) und muss manuell berechnet werden.
- Wir können die typischen Diagnostikplots erstellen.
Variante 1 | Korrektur
![]()
![]()
Manuelle Berechnung des F- und p-Werts für Faktor A (Treatment = Seeigeldichte):
Variante 1 | Modelldiagnostik
![]()
![]()

Hinweis
- Es gibt klare Anzeichen, dass die Annahme der Varianzhomogenität nicht gegeben ist.
- Eine Arcus-Sinus- und auch Log-Transformation auf die Prozentdaten haben keine Verbesserung gebracht.
- Zur Vergleichbarkeit mit dem Originalartikel Andrew & Underwood (1993) und dem Buchkapitel 9.1 in Quinn & Keough (2002) wurde die Demonstration hier mit den untransformierten Daten durchgeführt.
Variante 2
![]()
![]()
Error: Patch_newIDs
Df Sum Sq Mean Sq F value Pr(>F)
Treatment 3 14429 4810 2.717 0.0913 .
Residuals 12 21242 1770
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Error: Within
Df Sum Sq Mean Sq F value Pr(>F)
Residuals 64 19110 298.6 Vor- und Nachteile
- F- und p-Wert für
Treatment(Seeigeldichte) sind nun richtig berechnet. - Wir erhalten aber keinen F- und p-Wert für unseren verschachtelten Faktor.
- Wir können keine Modelldiagnostikplots mit
ploterstellen oder Residuen mitresiduals()direkt ausgeben.
Variante 3 | anova() Output
![]()
![]()
library(nlme)
mod_lme <- lme(fixed = Algae ~ Treatment,
random = ~ 1|Patch_newIDs, data = sea_urchins)
anova(mod_lme) numDF denDF F-value p-value
(Intercept) 1 64 18.555081 0.0001
Treatment 3 12 2.717102 0.0913Vor- und Nachteile
- F- und p-Wert für
Treatment(Seeigeldichte) sind richtig berechnet. - Aber: wir erhalten keine typische ANOVA-Tabelle mit Angabe der Freiheitsgrade und MS sowie der p-Werte der verschachtelten Faktoren.
- Dafür können wir einige andere Informationen extrahieren …
Variante 3 | summary() Output
![]()
![]()
Linear mixed-effects model fit by REML
Data: sea_urchins
AIC BIC logLik
694.1502 708.1346 -341.0751
Random effects:
Formula: ~1 | Patch_newIDs
(Intercept) Residual
StdDev: 17.15554 17.28005
Fixed effects: Algae ~ Treatment
Value Std.Error DF t-value p-value
(Intercept) 39.20 9.407876 64 4.166721 0.0001
Treatment33 -20.20 13.304746 12 -1.518255 0.1548
Treatment66 -17.65 13.304746 12 -1.326594 0.2093
Treatment100 -37.90 13.304746 12 -2.848607 0.0147
Correlation:
(Intr) Trtm33 Trtm66
Treatment33 -0.707
Treatment66 -0.707 0.500
Treatment100 -0.707 0.500 0.500
Standardized Within-Group Residuals:
Min Q1 Med Q3 Max
-1.9807559 -0.3105567 -0.1092864 0.2831185 2.5909912
Number of Observations: 80
Number of Groups: 16 Variante 3 | Anzeige der Effektgrößen
![]()
![]()
(Intercept) Treatment33 Treatment66 Treatment100
39.20 -20.20 -17.65 -37.90 (Intercept)
0:1 -4.1565747
0:2 18.9539808
0:3 -30.7586531
0:4 15.9612470
33:1 -13.6335652
33:2 -15.7949840
33:3 15.4624581
33:4 13.9660911
66:1 5.6945074
66:2 12.6775530
66:3 -17.0835222
66:4 -1.2885382
100:1 0.2493945
100:2 -1.0807094
100:3 -0.2493945
100:4 1.0807094Variante 3 | Varianzkomponenten
![]()
![]()
Berechnung der prozentualen Varianzkomponenten in der zufälligen Komponente:
Patch_newIDs = pdLogChol(1)
Variance StdDev
(Intercept) 294.3125 17.15554
Residual 298.6000 17.28005In der intercept ist der Faktor Patch_newIDs versteckt.
- → Von den zufälligen Effekten entfällt 49.7% der Varianz der Fadenalgenbedeckung auf die unterschiedlichen Patches innerhalb der Dichtestufen.
Variante 3 | Modelldiagnostik
![]()
![]()
![]()



Variante 4 - Die ‘Summary Measure
Analysis’
![]()
![]()
Zum Vergleich
Df Sum Sq Mean Sq F value Pr(>F)
Treatment 3 2886 961.9 2.717 0.0913 .
Residuals 12 4248 354.0
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 12-faktorielle Varianzanalyse mit verschachtelten Faktoren
-Beispiel DS2 Fallstudie
Datenaufbereitung
![]()
'data.frame': 450 obs. of 15 variables:
$ Gruppenname : chr "A-Team" "A-Team" "A-Team" "A-Team" ...
$ Datum : chr "17.4.2023" "17.4.2023" "17.4.2023" "17.4.2023" ...
$ Uhrzeit : chr "14:00" "14:00" "14:00" "14:00" ...
$ Breitengrad : num 53.6 53.6 53.6 53.6 53.6 ...
$ Laengengrad : num 9.97 9.97 9.97 9.97 9.97 ...
$ Standorttyp : chr "sonnig" "sonnig" "sonnig" "sonnig" ...
$ Art : chr "Iris virginica" "Iris virginica" "Iris virginica" "Iris virginica" ...
$ Gattung : chr "Iris" "Iris" "Iris" "Iris" ...
$ Familie : chr "Iridaceae" "Iridaceae" "Iridaceae" "Iridaceae" ...
$ Ordnung : chr "Asparagales" "Asparagales" "Asparagales" "Asparagales" ...
$ Pflanzen_ID : int 1 1 1 1 1 1 1 1 1 1 ...
$ Blueten_ID : int 1 1 1 2 2 2 3 3 3 4 ...
$ Kronblatt_ID: int 1 2 3 4 5 6 7 8 9 10 ...
$ Blattbreite : num 2.15 2.15 2.03 1.77 2 ...
$ Blattlaenge : num 5.6 5.7 5.6 5.4 5.5 5.5 6 5.8 6 5.6 ...# ID-Spalten als Faktor definieren
demo$Pflanzen_ID_f <- factor(demo$Pflanzen_ID)
demo$Blueten_ID_f <- factor(demo$Blueten_ID)
demo$Kronblatt_ID_f <- factor(demo$Kronblatt_ID)
# Gruppenname auch als Faktor abspeichern (fuer Modelle)
demo$Gruppenname_f <- factor(demo$Gruppenname,
levels = c("A-Team", "B Group", "CClub"),
labels = c("A", "B", "C"))
# Erstellen von einzigartigen IDs und Speicherung der Faktoren als Einzelvektoren
gruppe <- demo$Gruppenname_f
pflanze <- demo$Gruppenname_f:demo$Pflanzen_ID_f
bluete <- demo$Gruppenname_f:demo$Pflanzen_ID_f:demo$Blueten_ID_f
# Eine Datenexploration hat gezeigt, dass die Blattlaenge
# log-transformiert werden muss
y <- log(demo$Blattlaenge)Zusammenfassung
![]()
- Bei verschachtelten (hierarchischen) Designs und Pseudoreplikation sind die verschachtelten Faktoren meist zufällige Faktoren.
- Als Denominator beim F-Quotient des Hauptterms (die Behandlungsstufe meist) gehen die MS des verschachtelten Faktors ein, wenn dieser zufällig ist!
- Daher ist es wichtig in R, den verschachtelten Faktor eindeutig als zufällig zu definieren.
- Alle 3 vorgestellten Varianten haben ihre Vor- und Nachteile.
- Variante 1:
- ⨁ Wir erhalten die vollständige Tabelle bei einem 2-faktoriellen, verschachtelte Design und können die typischen Diagnostikplots erstellen.
- ⊖ F- und p-Wert vom Hauptfaktor müssen manuell berechnet werden.
- Variante 2:
- ⨁ F- und p-Wert für den Hauptfaktor werden richtig berechnet.
- ⊖ Wir erhalten keinen F- und p-Wert für unseren verschachtelten Faktor und können keine Modelldiagnostikplots mit
plot()erstellen oder Residuen mitresiduals()direkt ausgeben.
- Variante 3:
- ⨁ F- und p-Wert für den Hauptfaktor werden richtig berechnet und wir können einige Informationen extrahieren wie Effektgrößen und Anteile der Varianzkomponenten.
- ⊖ Aber: wir erhalten keine typische ANOVA-Tabelle mit Angabe der Freiheitsgrade und MS sowie der p-Werte der verschachtelten Faktoren.
Fragen..??

Total konfus?
Buchkapitel zum Nachlesen
- The R Book von M.J. Crawley:
- Kapitel 11.3 Pseudoreplication: Nested designs and split plots
- Kapitel 19.5 Hierarchical sampling and variance components analysis
- Experimental Design and Data Analysis for Biologists von G.P. Quinn & M.J. Keough:
- Kapitel 9.1 Nested (hierarchical) designs
Übungsaufgabe
Übung
![]()
- Zuhause (VOR der Übung):
- Durchführung einer 2-faktoriellen, verschachtelten ANOVA für eine Umweltverträglichkeitsstudie (curdies.csv Datensatz).
- WÄHREND der Übungsstunde:
- Durchführung einer 3-faktoriellen, verschachtelten ANOVA auf die Fallstudiendaten aus DS2 (siehe Frage 2 der Fallstudie).
Das R Notebook und der Datensatz für 1. sind im Moodlekurs (Woche 2) zu finden. Das Skript dieser VL ist auch auf Moodle.
Für Aufgabe 2 die Fallstudiendaten aus DS2 mitbringen!
Total gelangweilt?

Dann testen Sie doch Ihr Wissen in folgendem Abschlussquiz…
Abschlussquiz
![]()
Bei weiteren Fragen: saskia.otto(at)uni-hamburg.de

Diese Arbeit is lizenziert unter einer Creative Commons Attribution-ShareAlike 4.0 International License mit Ausnahme der entliehenen und mit Quellenangabe versehenen Abbildungen.