Df Sum Sq Mean Sq F value Pr(>F)
dosis_fac 1 6834 6834 167.1 9.38e-12 ***
Residuals 22 900 41
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1Moduleinführung: was ist EDA, DM, ML und SL?
DS3 - Vom experimentellen Design zur
explorativen Datenanalyse & Data Mining
Universität Hamburg, IMF
Wintersemester 2025/2026
Modulübersicht
![]()
Lernziele des Moduls
![]()
Am Ende des Semesters werden Sie …
- grundlegende Kenntnisse zu verschiedenen Methoden des Lernens aus Daten erworben haben,
- ein Verständnis für statistische Modelle entwickelt haben und Methoden wie die Kovarianzanalyse, multiple Regression, lineare gemischte Modelle sowie Resampling-Techniken auf Daten anwenden können,
- die Prinzipien des überwachten und unüberwachten Lernens kennen und bei letzterem zwei grundlegende Methoden der multivariaten Analyse anwenden und interpretieren können.
- die Grundlagen von Open Science und die Anwendung von R Markdown bzw. Quarto zur Dokumentation und Kommunikation wissenschaftlicher Arbeiten beherrschen,
- in der Lage sein, die erlernten Modellierungsverfahren und Analysetechniken auf die Fallstudie aus dem vorherigen Data Science Modul 2 anzuwenden.
Materialien & Tools
- VL-Folien im HTML-Format
- Handbuch
- Allgemeine Modulinformationen
- Aufgabenstellung Übungen
- R Studio-Projektordner → ZIP-Datei zum Download
- R Notebooks
- Daten
- Moodle:
- VL: PDF-Folien, Aufzeichnungen
- Quizze begleitend zu den Übungen mit Lösungen
- Klausur, Klausurvorbereitendes Quiz
- Kommunikationsplattform
- RStudio Server (Link s. Moodle)



EDA Demonstration













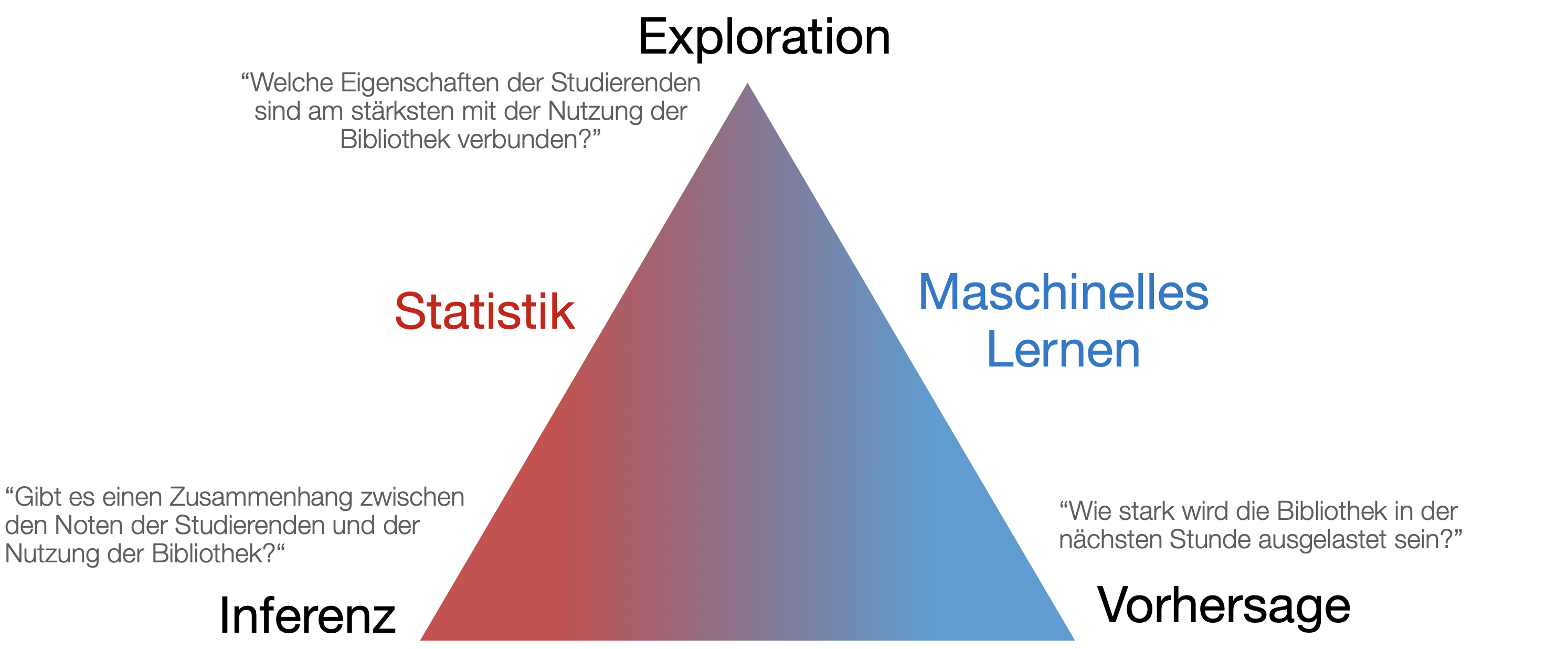
Lernen aus den Daten
→ Die Wissenschaft des Lernens spielt eine Schlüsselrolle in den Bereichen Statistik, Data Mining und künstliche Intelligenz und überschneidet sich mit Bereichen der Ingenieurwissenschaften und anderen Disziplinen.
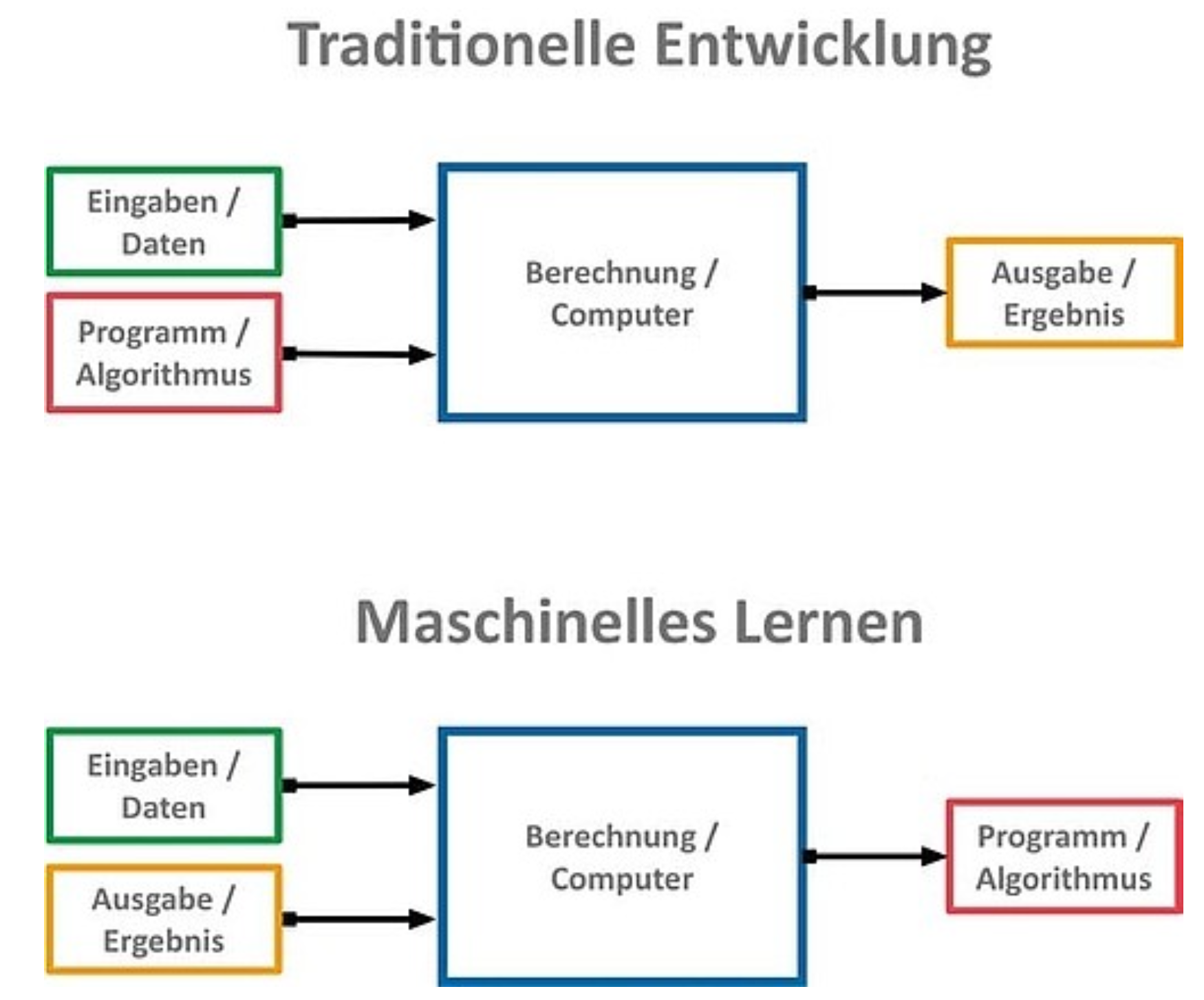
Was macht ML aus?
ML | Typisches Anwendungsbeispiel
Bilderkennung

Was ist statistisches Lernen?
![]()
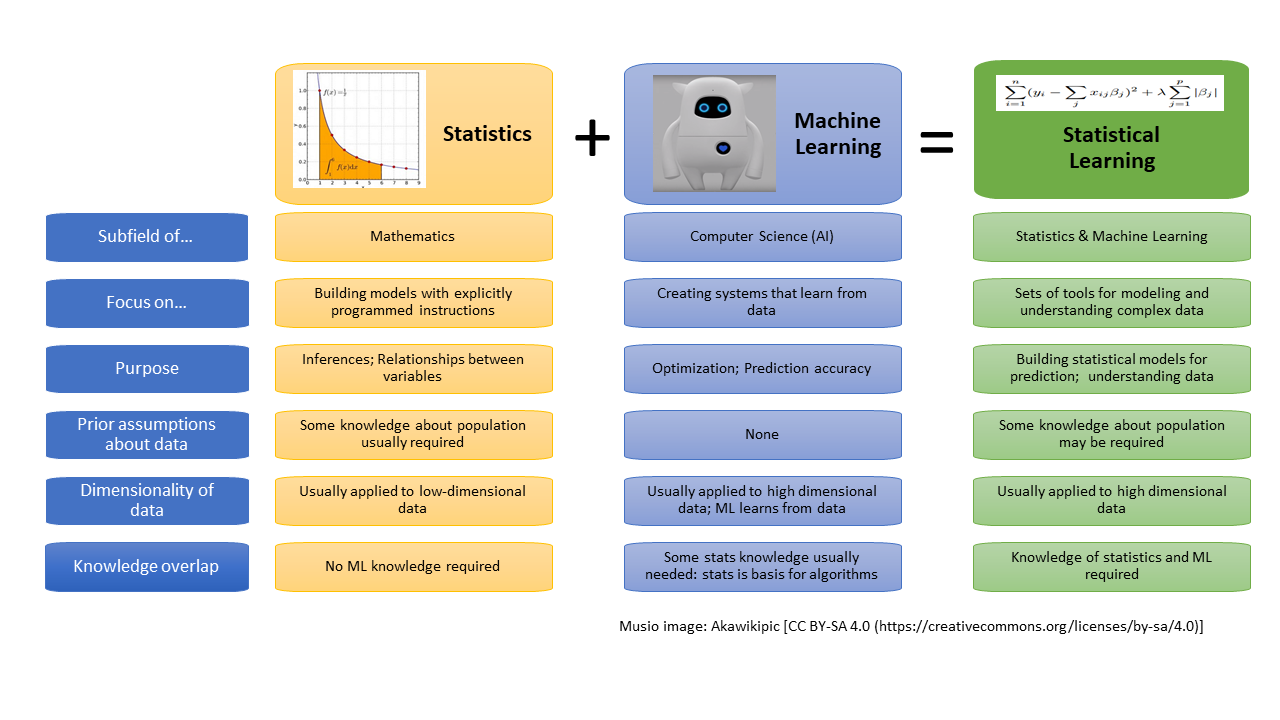
- Maschinelles Lernen ist ein Teilgebiet der Künstlichen Intelligenz.
- Statistisches Lernen entstand als Teilgebiet der Statistik.
- Es gibt viele Überschneidungen - beide Bereiche konzentrieren sich auf überwachte und nicht überwachte Probleme:
- Beim ML liegt der Schwerpunkt stärker auf groß angelegten Anwendungen und der Vorhersagegenauigkeit.
- Beim SL liegt der Schwerpunkt auf Modellen und deren Interpretierbarkeit sowie auf Präzision und Unsicherheit.
- Unterscheidung verschwimmt immer mehr.
‘Supervised’ vs. ‘Unsupervised’ Learning
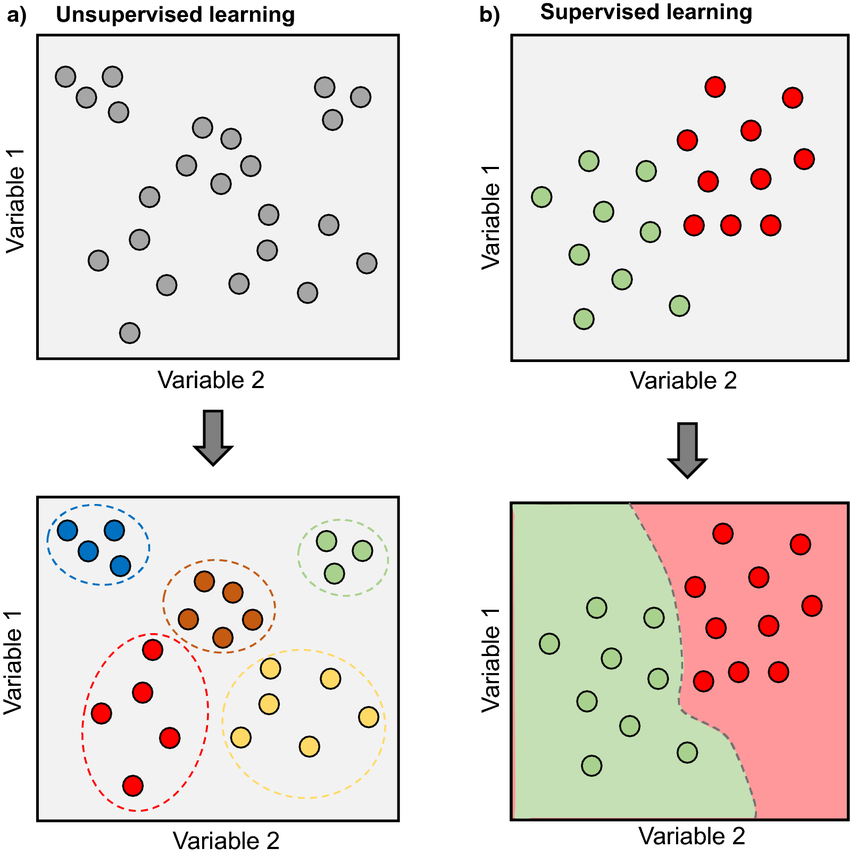
Bildquelle: Morimoto & Ponton (2021): Virtual reality in biology: could we become virtual naturalists?
Flexibilität vs. Interpretierbarkeit
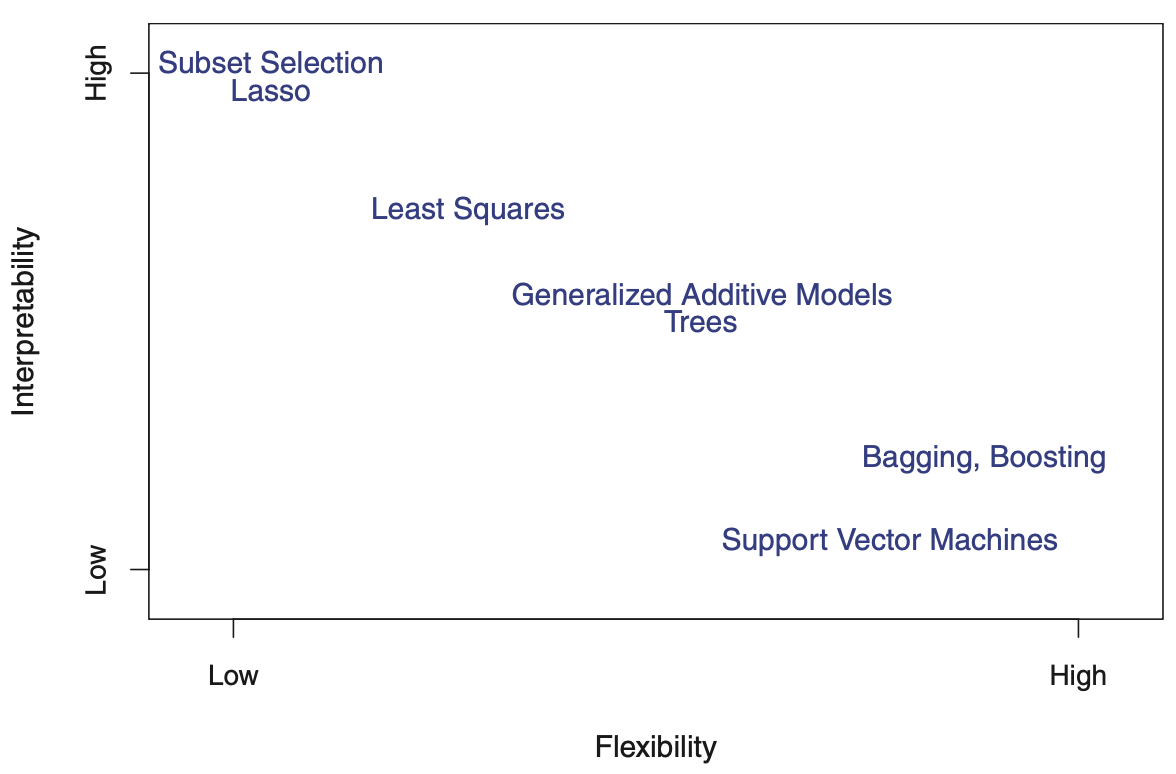
Bildquelle: James et al. (2013): Introduction to Statistical Learning
Performance von Trainings- vs. Testdaten
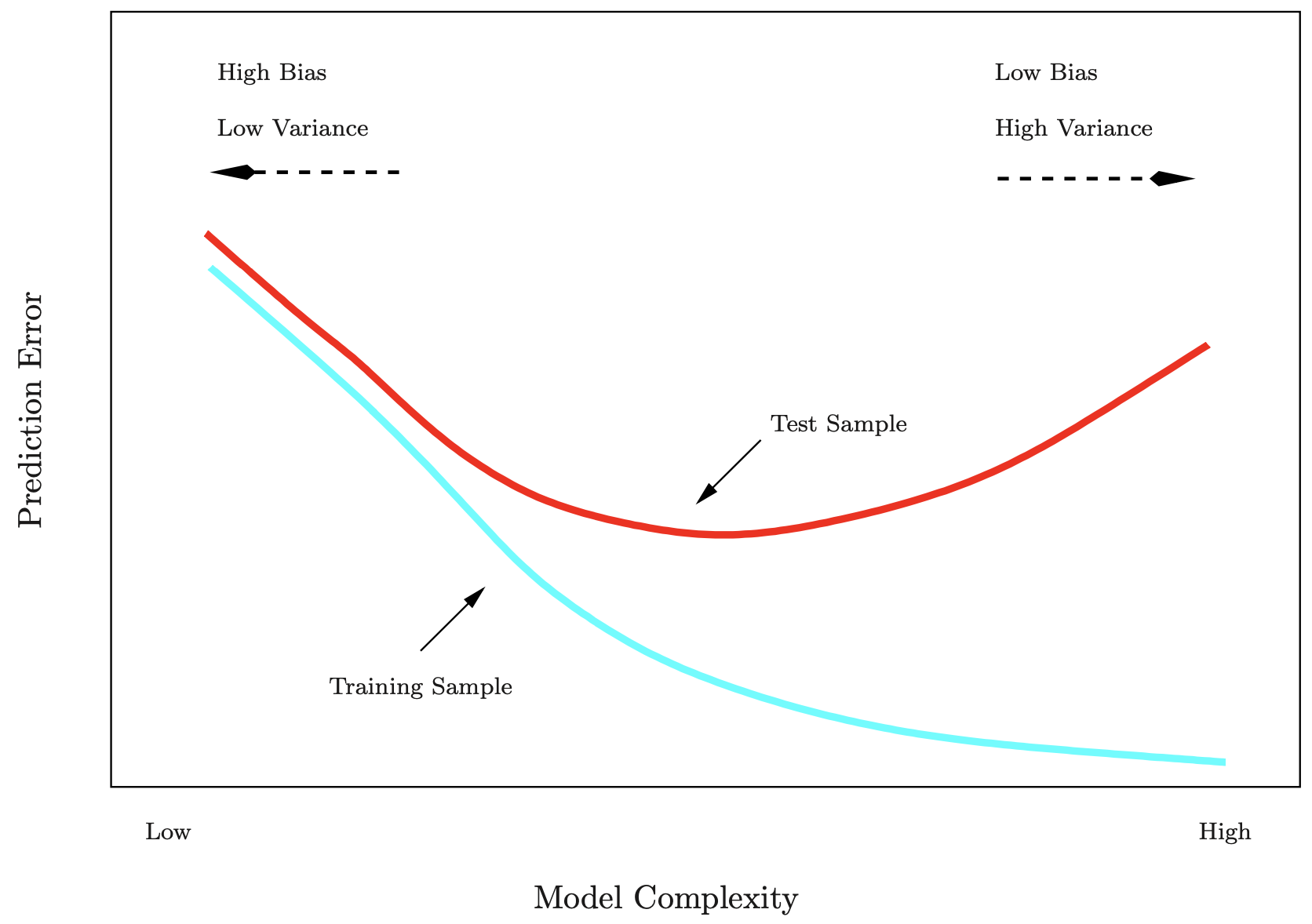
Die Trainingsfehlerrate (MSE_{train}) unterscheidet sich oft erheblich von der Testfehlerrate (MSE_{test}). Insbesondere bei sehr flexiblen Modellen kann die Trainingsfehlerrate die Testfehlerrate drastisch unterschätzen.
Bildquelle: James et al. (2013): Introduction to Statistical Learning
Supervised Learning | Beliebte Methoden
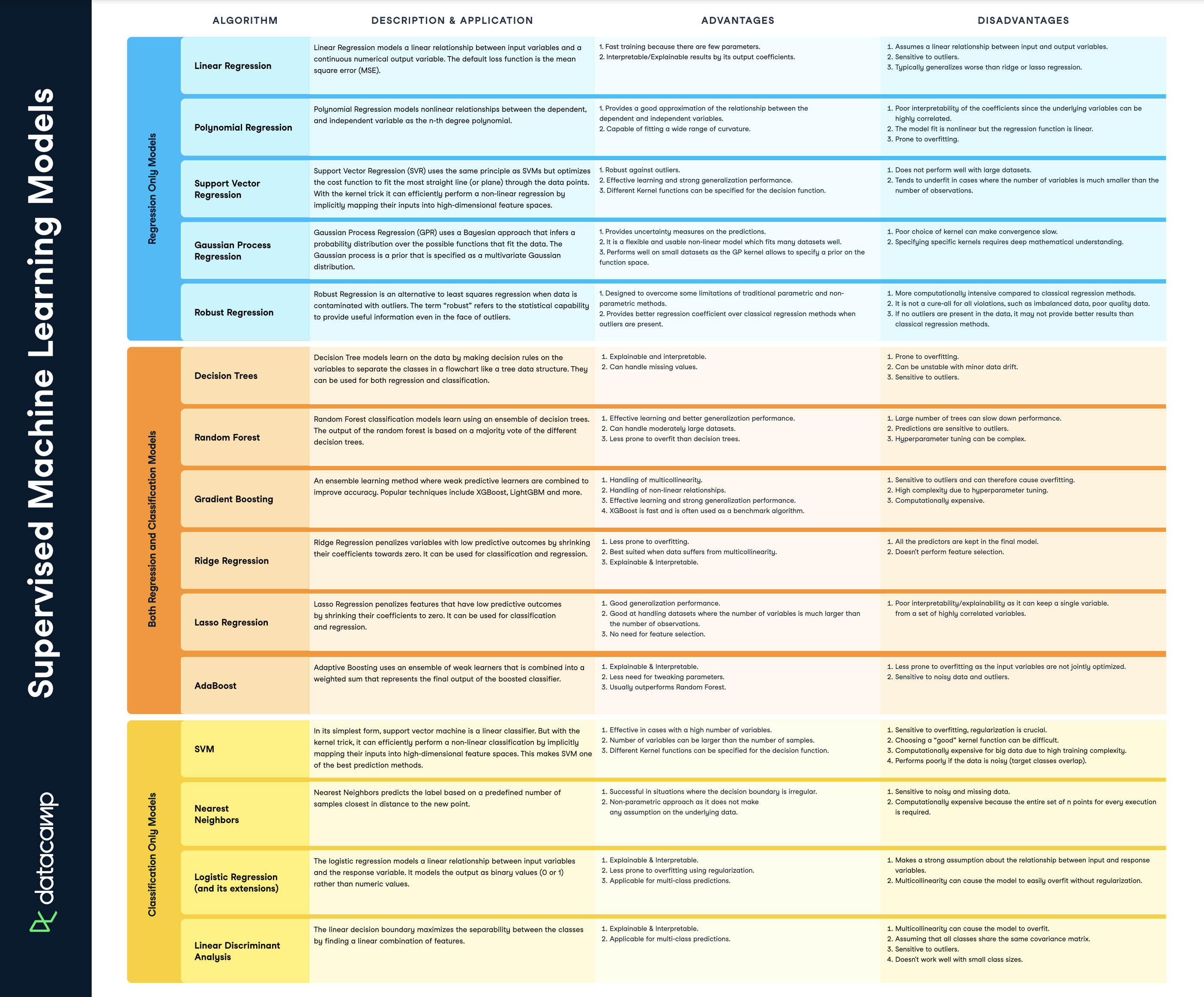
Download-link dieses Cheatsheets: [datacamp.com](https://www.datacamp.com/cheat-sheet/)
Live-Demo in R
![]()
Zurück zu Primärdaten
Aber fangen wir erstmal wieder mit kleineren Datensätzen aus (eigenen) Datenerhebungen an …
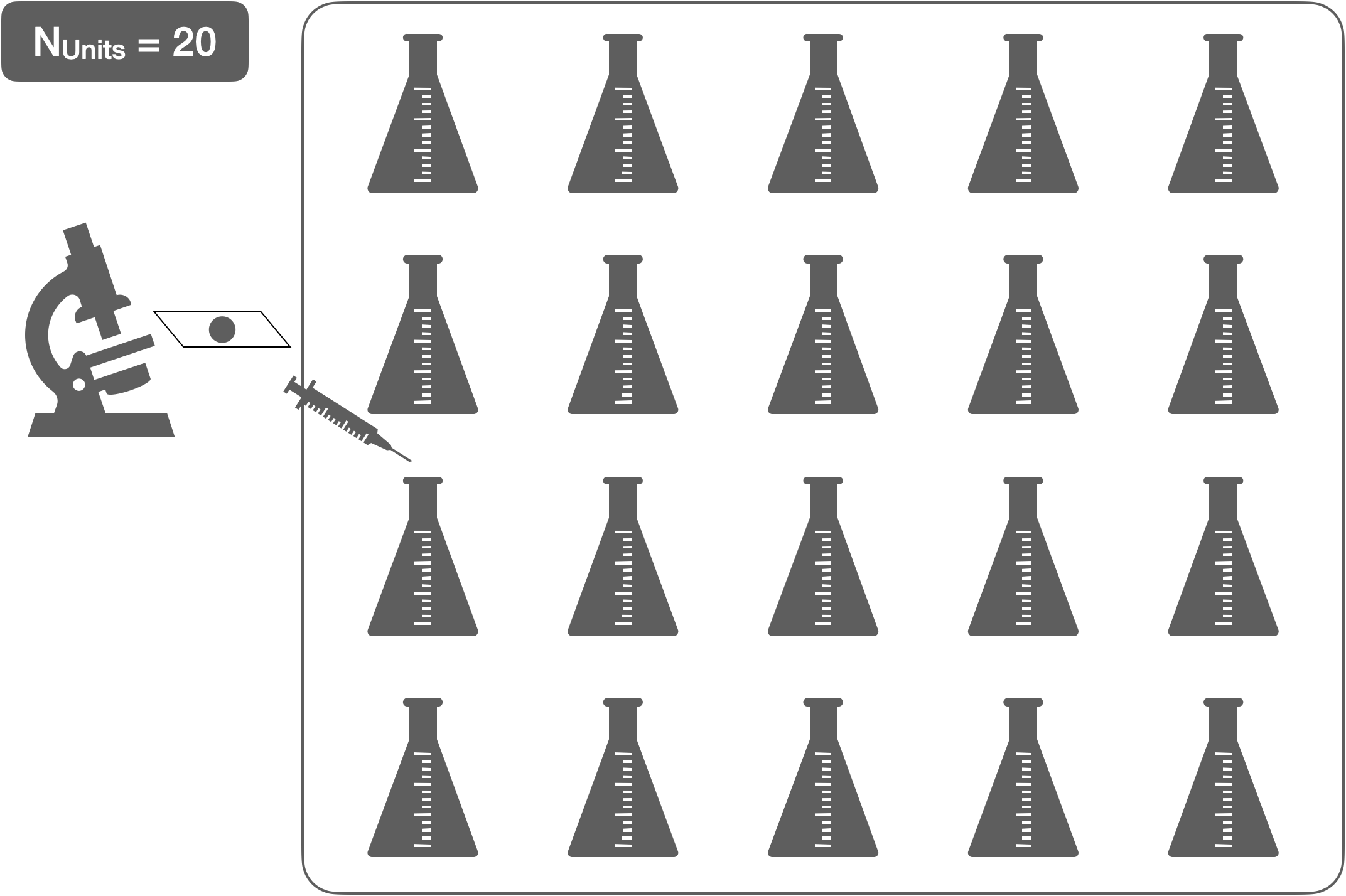
Completely Randomised Design (CRD)
Alle experimentellen Einheiten sind unabhängig und können zufällig allen Kombinationen von Behandlungsstufen zugeteilt werden.
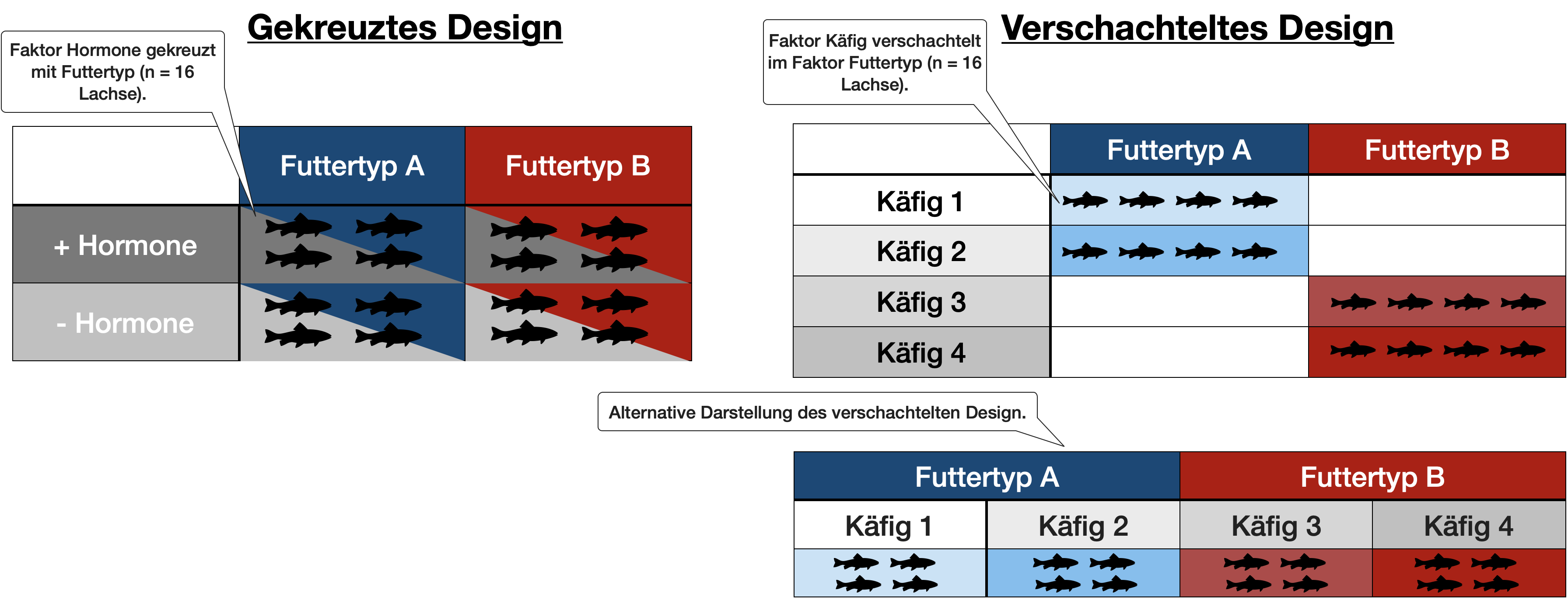
CRD - 2 gekreuzte Faktoren (je 2 Gruppen)
Gekreuztes Design
- N: 20 (Erlenmeyerkolben)
- n: 5 (EK pro Dosis/Typ)
- Ergebnis: Zellzahl
- Behandlungseffekte:
- Dosis (fest) = {0, 100}
- Typ (fest) = {1, 2}
- Dosis (fest) = {0, 100}
- Analyse: 2-way crossed/factorial ANOVA

CRD - 1 Faktor (2 Gruppen) mit Unterprobe
Verschachteltes Design
- N: 8 (Exp. Units: Erlenmeyerkolben)
- n: 3 (Objektträger als Unterproben pro EK)
- Ergebnis: Zellzahl
- Effekte:
- Behandlungseff.: Dosis (fest) = {0, 100}
- Technischer Eff.: EK (zufällig) = {1,2,3,..,8}
- Analyse: 2-way nested ANOVA (oder ‘summary measure’ analysis)
- Freiheitsgrade:
\begin{align*} \text{Ergebnis} &= \text{Dosis} + \text{Fehler}\\ \text{(N - 1)} &= \text{(p - 1)} + \text{(N - p)}\\ \text{(7)} &= \text{(1)} + \text{(6)} \end{align*}

Vergleich beider Designs
CRD - 1 Faktor mit Unterprobe | Ansätze
- Falscher Ansatz:
- 1-faktorielle ANOVA, ohne Berücksichtigung der Pseudoreplikation
- Richtige Ansätze:
- 1-faktorielle ANOVA mit gemittelten Unterprobewerte (‘summary measure’ analysis).
- Lineares Gemischtes Modell (LME) mit dem R Paket nlme (oder lme4).
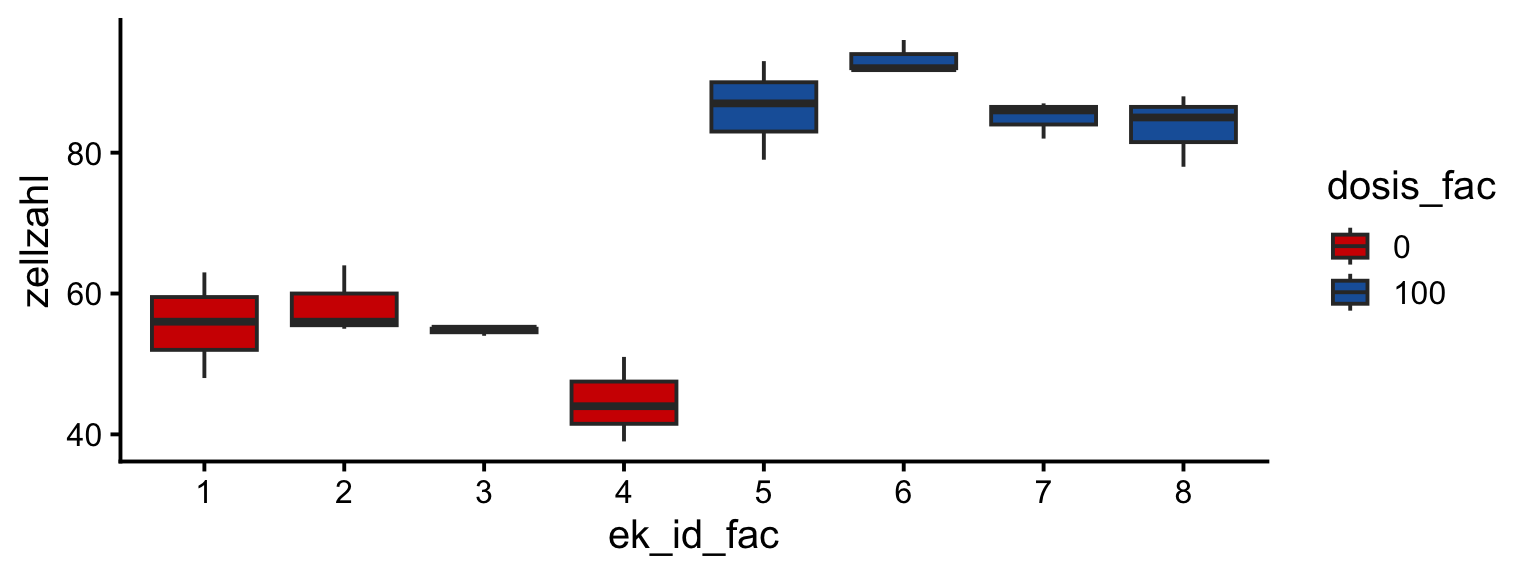
CRD - 1 Faktor mit Unterprobe | Falscher Ansatz
![]()
- Die Freiheitsgerade der Residuen betragen hier 22!
- Die FG zur Berechnung des F- und p-Werts der Behandlungsvariable (Dosis) dürfen nicht höher sein als die experimentellen Einheiten selbst (hier 8).
- Dadurch ist der F-Wert viel höher und der p-Wert viel niedriger als korrekt wäre.
CRD - 1 Faktor mit Unterprobe | Ansatz 1
![]()
1-faktorielle ANOVA mit gemittelten Unterprobewerten
Df Sum Sq Mean Sq F value Pr(>F)
dosis_fac 1 2278 2278.1 83.87 9.54e-05 ***
Residuals 6 163 27.2
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1- Hier wird das Problem der Pseudoreplikation durch die Mittelwertbildung gelöst.
Übungen
Übungswoche 1
![]()
Summary Measure Analysis’ der DS2 Fallstudie
Vorbereitung @home (s. Handbuch)
- Auffrischungsquiz (siehe Moodle)
- Fallstudiendaten zu Aufgabe 2.2 (Mehrstichprobentest) vorbereiten:
- Neues Skript bzw. Notebook erstellen.
- Benötigte Daten in R laden und aufbereiten.
- Mittelwertbildung der Kronblattbreite für jede Pflanze.
Fragen..??

Total gelangweilt?

Dann testen Sie doch Ihr Wissen in folgendem Abschlussquiz…
Abschlussquiz
![]()
Bei weiteren Fragen: saskia.otto(at)uni-hamburg.de

Diese Arbeit is lizenziert unter einer Creative Commons Attribution-ShareAlike 4.0 International License mit Ausnahme der entliehenen und mit Quellenangabe versehenen Abbildungen.