
Kurseinführung und 2-faktorielle Varianzanalyse (Teil 1)
DS3 - Vom experimentellen Design zur
explorativen Datenanalyse & Data Mining
Universität Hamburg, IMF
Wintersemester 2023/2024
Durchführung wissenschaftlicher Studien
Von den Primärdaten (experimentelles Design) zu den Sekundärdaten (Data Mining)


‘LEARNING’ vs. ‘Confirming Experiments’
Lernende (explorative) Experimente
- Hat das Medikament toxische Nebenwirkungen (in welcher Dosis, über welchen Zeitraum, in welchem Gewebe)?
- Das Ziel ist etwas Neues zu lernen.
- Hypothese ist allgemeiner und ein statistischer Test ist weniger wichtig
- Typisches Beispiel in der Biologie: ‘High-throughput screening’ in den Omics Wissenschaften.


Emutlu et al. (2012): 18O-assisted dynamic metabolomics
for individualized diagnostics and treatment of human
diseases, Croat Med J 53(6): 529–534
Statistik in Zeiten der Computer-Ära

Klassische Inferenzstatistik
- Frequentistische Inferenz
- Bayes’sche Inferenz
- Fisher’sche Inferenz und die Maximum-Likelihood-Schätzung
- Parametrische Modelle (Regression, ANOVA, ANCOVA)
Frühe Methoden des Computerzeitalters
- Empirische Bayes Methode
- James-Stein-Schätzung und Ridge-Regression
- Generalisierte Lineare und Additive Modelle (GLM, GAM)
- Entscheidungsbäume CART (Classification und Regression Trees)
- Überlebensanalyse (survival analysis) und Erwartungs-Maximierungs-Algorithmus
- Jackknife und Bootstrap Methoden
- Markov Chain Monte Carlo
- ARIMA Modelle
Methoden des 21. Jahrhunderts
- Großskalige Hypothesentests und Falscherkennungsraten
- Sparse Modeling und Lasso Regression
- Random Forests und Boosting
- Neuronale Netzwerke und Deep Learning
- Support-Vector Machines und Kernel Methoden
- Empirische Bayes Schätzstrategien
Aus Efron & Hastie (2016)
Computer Age Statistical
Inference: Algorithms,
Evidence, and Data Science
Link zum Buch: hier
Zur Erinnerung…

Klassischer Weg in der
inferenziellen
Statistik

Schritt 1 | Wahl der Statistik
Beispiel einer Forschungshypothese
Die intraspezifische Streuung des Zugverhaltens ist bei Buchfinken kleiner als bei der Mönchsgrasmücke.


Zu vergleichender Parameter bzw. Kennwert
Die Varianz \(\sigma^2\) bzw. \(s^2\)
Bildquellen: Wikipedia (Buchfink unter CC BY-SA 2.5 Lizenz) und Mönchsgrasmücke unter CC0 Lizenz)
Schritt 2 | Formulierung der Hypothesen
Beispiel Zugverhalten
Die intraspezifische Streuung des Zugverhaltens ist bei Buchfinken kleiner als bei der Mönchsgrasmücke.
Hypothesen (einseitig)
- \(H_A: \sigma_{Buchfink}^2 < \sigma_{Mönchsgrasmücke}^2\)
- \(H_0: \sigma_{Buchfink}^2 \geq \sigma_{Mönchsgrasmücke}^2\)
Bildquellen: Wikipedia (Buchfink unter CC BY-SA 2.5 Lizenz) und Mönchsgrasmücke unter CC0 Lizenz)
Schritt 3 | Datenerhebung und -exploration
Beispiel Zugverhalten
| Kenngröße | Buchfink | Mönchsgrasmücke |
|---|---|---|
| Mittelwert x̅ | 1800 km | 3000 km |
| Standardabweichung s | ±900 km | ±1000 km |
| Stichprobengröße n | 20 | 30 |
Wahl des statistischen Test | Schritt 4
Folgende grundlegende Fragen müssen beantwortet werden:
- Welches Skalenniveau liegt vor (nominal, ordinal, metrisch)?
- Wie viele Stichproben sollen verglichen werden (1, 2, ≥2)?
- Was soll getestet werden (Abweichungen von einer Verteilung, einer erwarteten Häufigkeitsverteilung, einem Erwartungswert)?
- Ermöglicht die Stichprobenverteilung die Anwendung parametrischer Verfahren, d.h. sind die Daten normal verteilt (und Varianzhomogen) (Schritt 3)?

Wahl des statistischen Test | Übersicht
Klassische Tests

Completely Randomised Design (CRD)
Alle experimentellen Einheiten sind unabhängig und können zufällig allen Kombinationen von Behandlungsstufen zugeteilt werden.
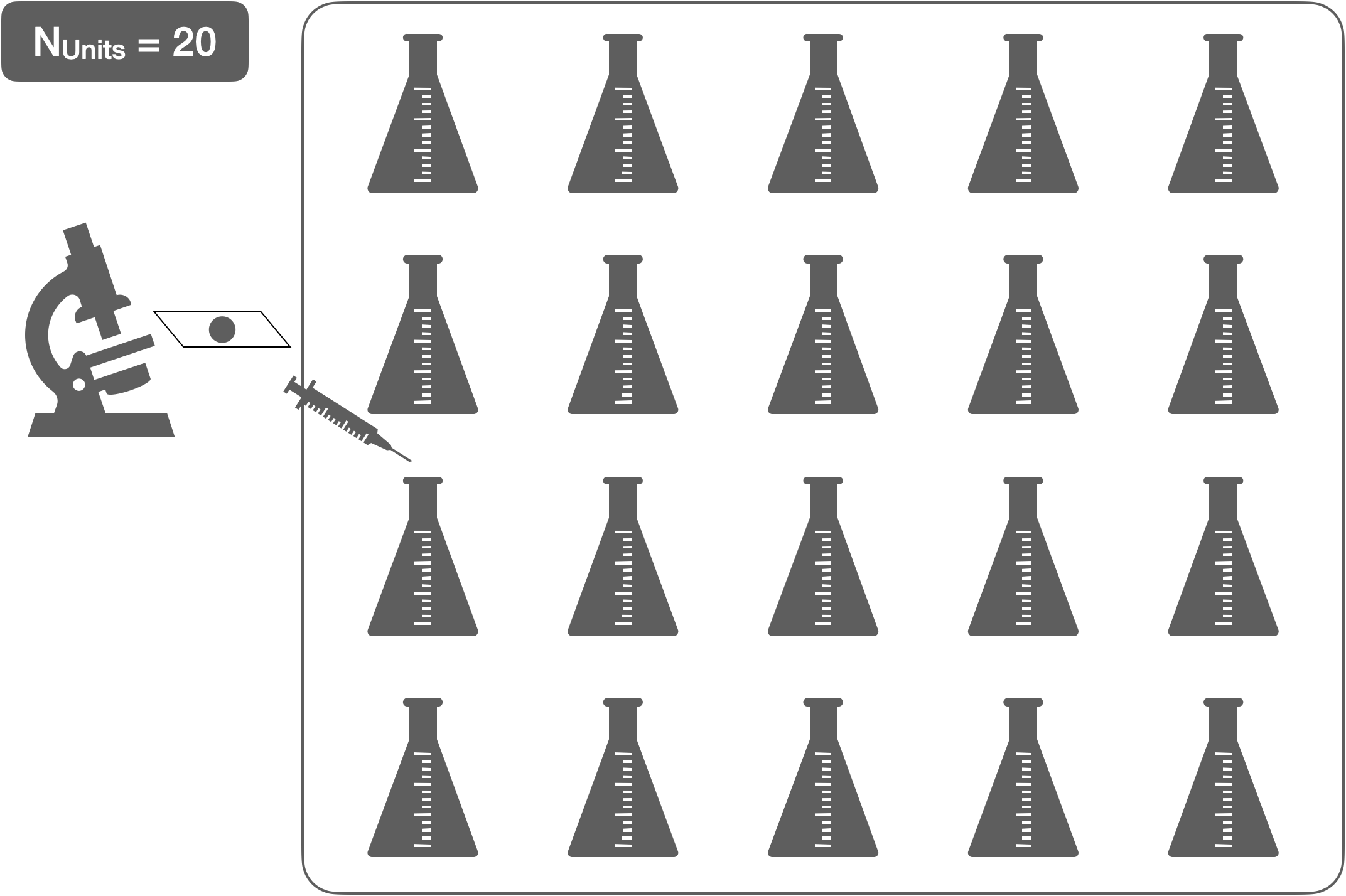
CRD - 1 Faktor (2 Gruppen)
Design
- N: 20 (Exp. Units: Erlenmeyerkolben)
- n: 10 (EK pro Dosis)
- Ergebnis: Zellzahl
- Behandlungseffekt: Dosis (fest) = {0, 100}
- Analyse: t-Test (oder 1-way ANOVA)
- Freiheitsgrade:
\[\begin{align*} \text{Ergebnis} &= \text{Dosis} + \text{Fehler}\\ \text{(N - 1)} &= \text{(p - 1)} + \text{(N - p)}\\ \text{(19)} &= \text{(1)} + \text{(18)} \end{align*}\]
CRD - 1 Faktor (4 Gruppen)
Design
- N: 20 (Exp. Units: Erlenmeyerkolben)
- n: 5 (EK pro Dosis)
- Ergebnis: Zellzahl
- Behandlungseffekt: Dosis (fest) = {0,50,100,150}
- Analyse: 1-way ANOVA (oder Regression)
- Freiheitsgrade:
Dosis ist kategorial (ANOVA): \[\begin{align*} \text{Ergebnis} &= \text{Dosis} + \text{Fehler}\\ \text{(N - 1)} &= \text{(p - 1)} + (\text{N - p})\\ \text{(19)} &= \text{(3)} + (\text{16}) \end{align*}\]
Dosis ist kontinuierlich (Regression): \[\begin{align*} \text{Ergebnis} &= \text{Dosis} + \text{Fehler}\\ \text{(19)} &= \text{(1)} + (\text{18}) \end{align*}\]

CRD - 1 Faktor (4 Gruppen) | ANOVA Tabelle
Typische Tabelle einer 1-faktoriellen Varianzanalyse

CRD - 1 Faktor (4 Gruppen) | 1-way ANOVA
Df Sum Sq Mean Sq F value Pr(>F)
dosis_fac 3 9713 3238 7.424 0.00247 **
Residuals 16 6978 436
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
![]()
![]()
CRD - 2 gekreuzte Faktoren (je 2 Gruppen)
Gekreuztes Design
- N: 20 (Erlenmeyerkolben)
- n: 5 (EK pro Dosis/Typ)
- Ergebnis: Zellzahl
- Behandlungseffekte:
- Dosis (fest) = {0, 100}
- Typ (fest) = {1, 2}
- Dosis (fest) = {0, 100}
- Analyse: 2-way crossed/factorial ANOVA

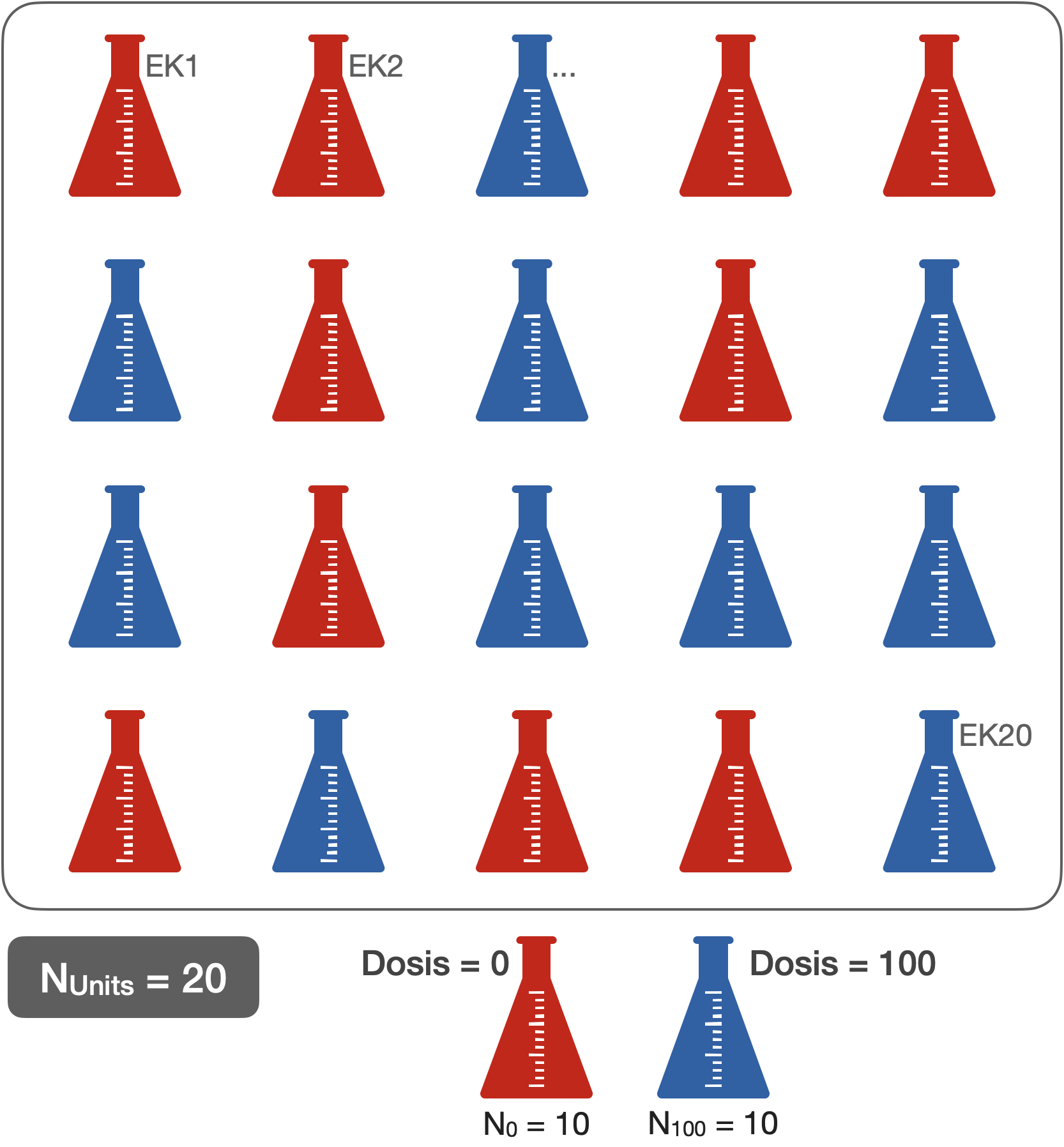
CRD - 1 Faktor (2 Gruppen) mit Unterprobe
Verschachteltes Design
- N: 8 (Exp. Units: Erlenmeyerkolben)
- n: 3 (Objektträger als Unterproben pro EK)
- Ergebnis: Zellzahl
- Effekte:
- Behandlungseff.: Dosis (fest) = {0, 100}
- Technischer Eff.: EK (zufällig) = {1,2,3,..,8}
- Analyse: 2-way nested ANOVA (oder ‘summary measure’ analysis)
- Freiheitsgrade:
\[\begin{align*} \text{Ergebnis} &= \text{Dosis} + \text{Fehler}\\ \text{(N - 1)} &= \text{(p - 1)} + \text{(N - p)}\\ \text{(7)} &= \text{(1)} + \text{(6)} \end{align*}\]

CRD - Komplexe verschachtelte Designs
Beispiel: Räumliche Variabilität von Blattlausdichten
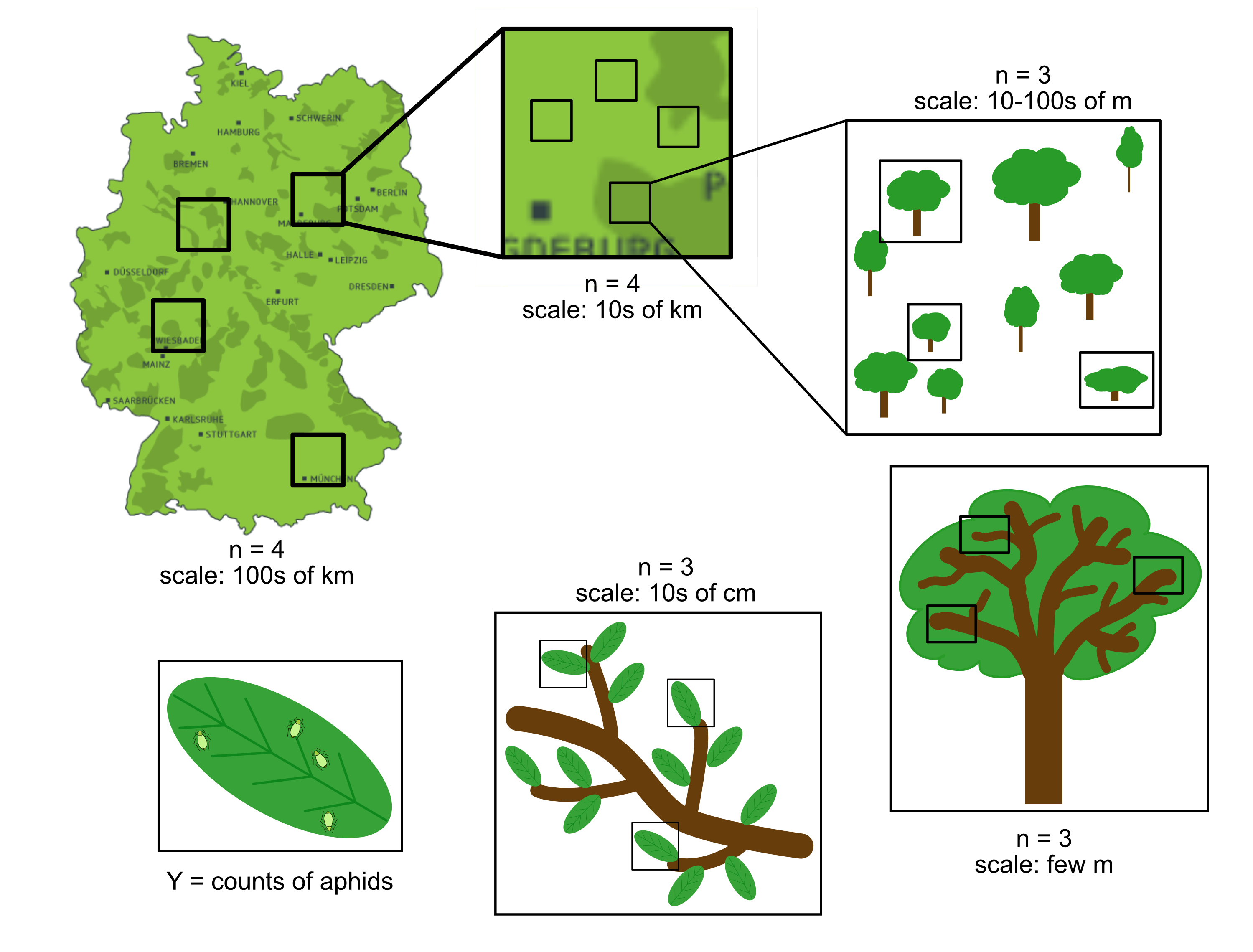
- Gerade bei räumlichen und zeitlichen Feldstudien ist das Beprobungsdesign oft stark verschachtelt.
- → Der größte Beprobungsaufwand sollte auf der Skala mit der höchsten Varianz erfolgen (viele Wiederholungen)!
Vergleich beider Designs
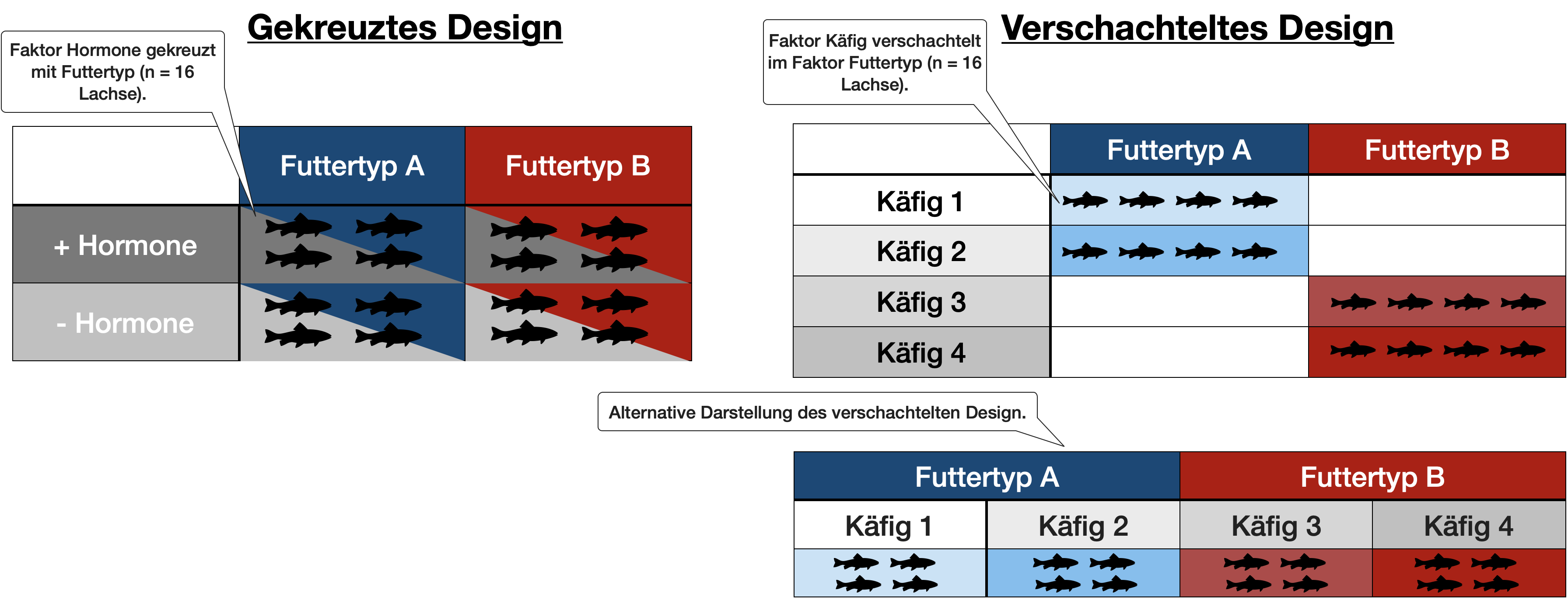
Falsche Anwendung

2-faktorielle Varianzanalyse mit gekreuzten Faktoren

Napfschnecken Versuch
![]()
Qinn (1988) untersuchte die Auswirkungen der Jahreszeit und der Dichte der adulten Tiere auf die Fruchtbarkeit von Napfschnecken (Siphonaria diemenensis).

Beispiel ist aus Kapitel 9.2 in Quinn & Keough (2002): Experimental Design and Data Analysis for Biologists
- Die Napfschnecken (ca. 10 mm Schalenlänge) waren in 225 cm2 großen Edelstahlnetzen eingeschlossen, die an der felsigen Plattform befestigt waren. Es gab acht Behandlungskombinationen (vier Dichten zu jeder der beiden Jahreszeiten) und drei Wiederholungen pro Behandlungskombination.
- Gekreuztes Design da alle vier Dichten in beiden Jahreszeiten verwendet wurden.
- Eine der wichtigsten Fragen, die bei diesem Versuch gestellt wurden, war, ob die Auswirkung der Dichte auf die Anzahl der Eimassen pro Napfschnecke von der Jahreszeit abhängt. Quinn (1988) sagte voraus, dass die Auswirkung der Dichte im Sommer/Herbst, wenn die Algennahrung knapp ist, größer sein würde als im Winter/Frühling, wenn die Algennahrung reichhaltiger ist.
Lineares ANOVA Model
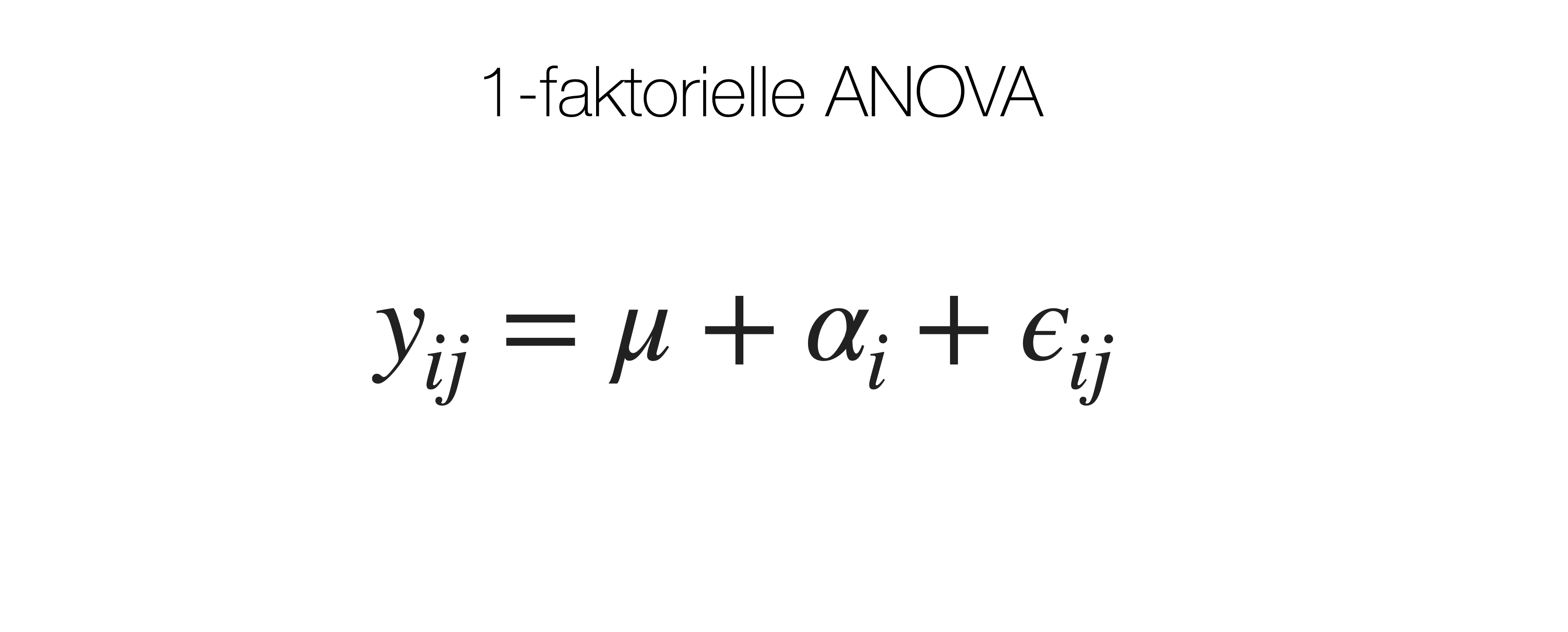
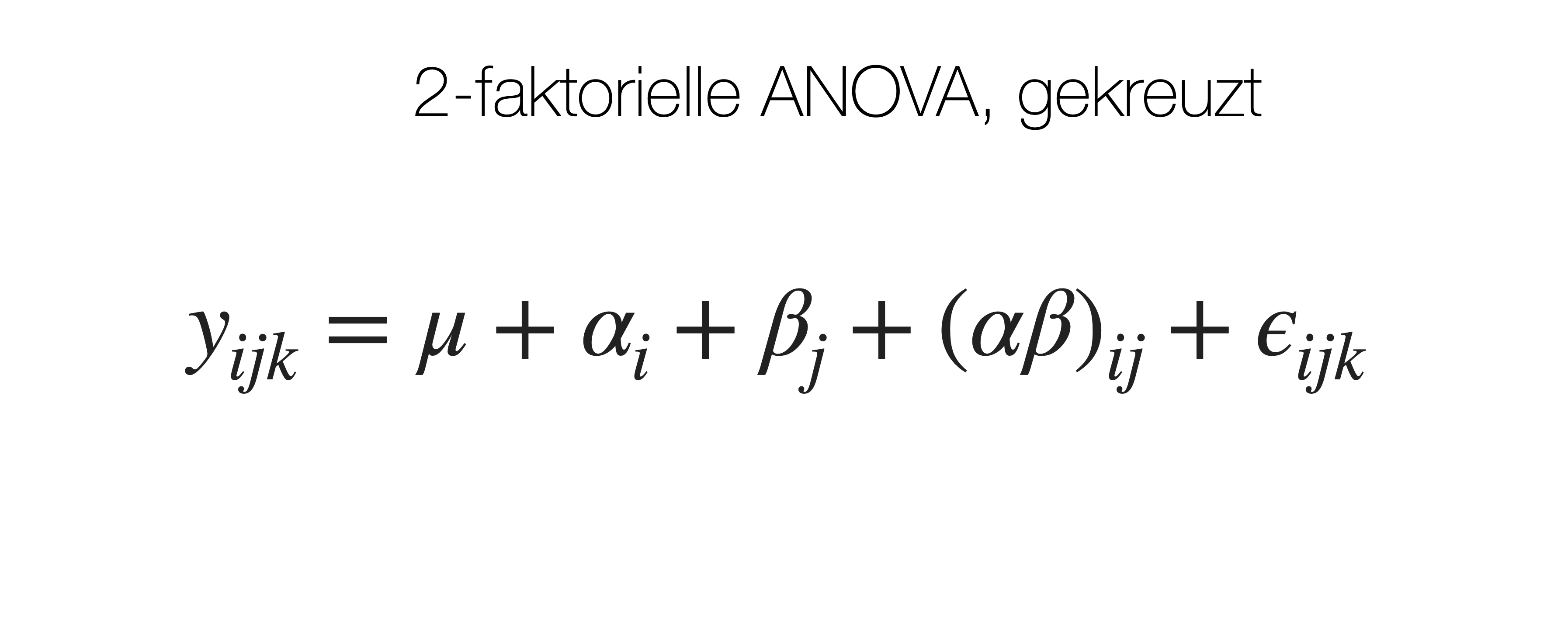

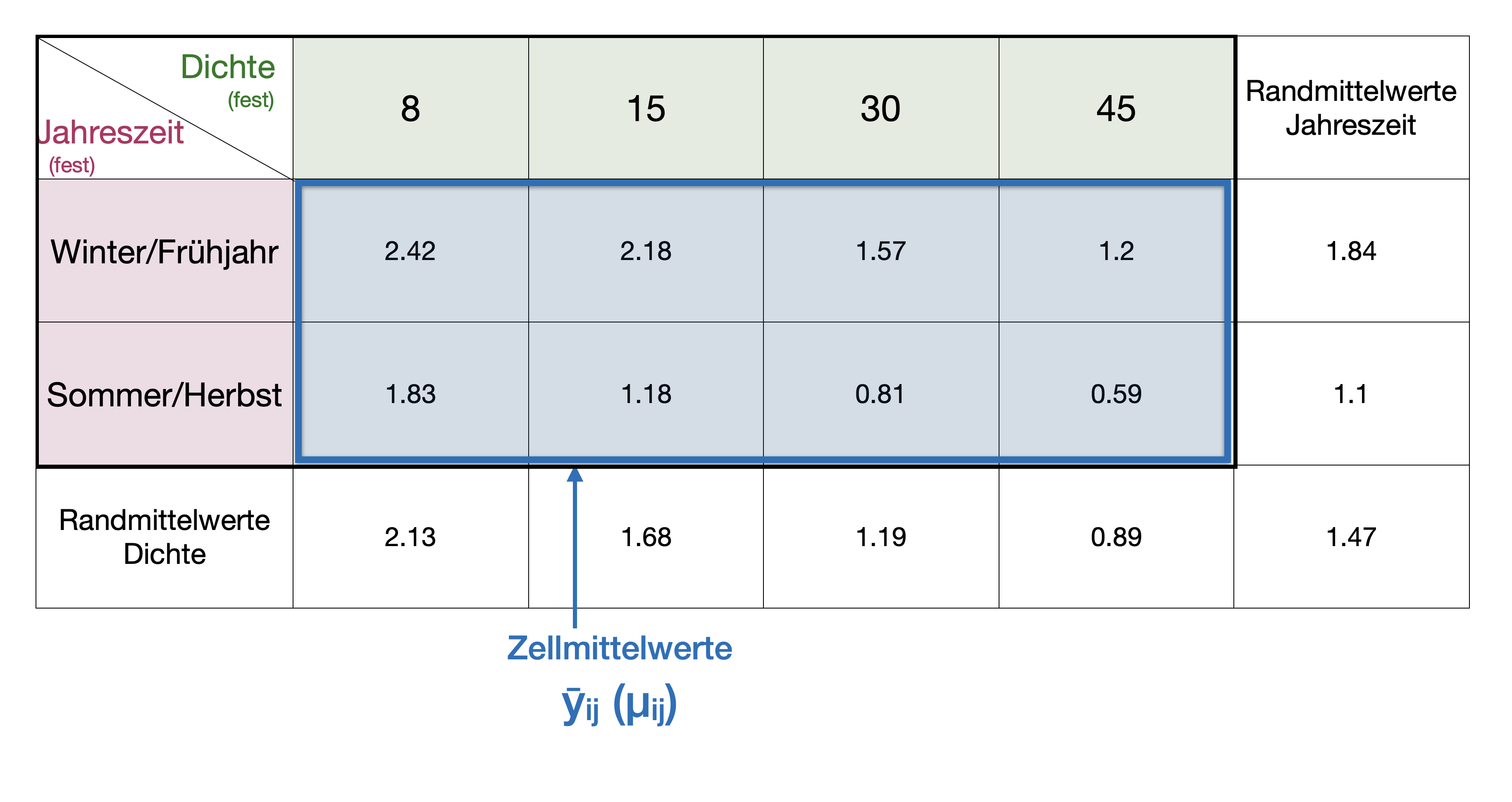
Napfschnecken Versuch | Zellmittelwerte
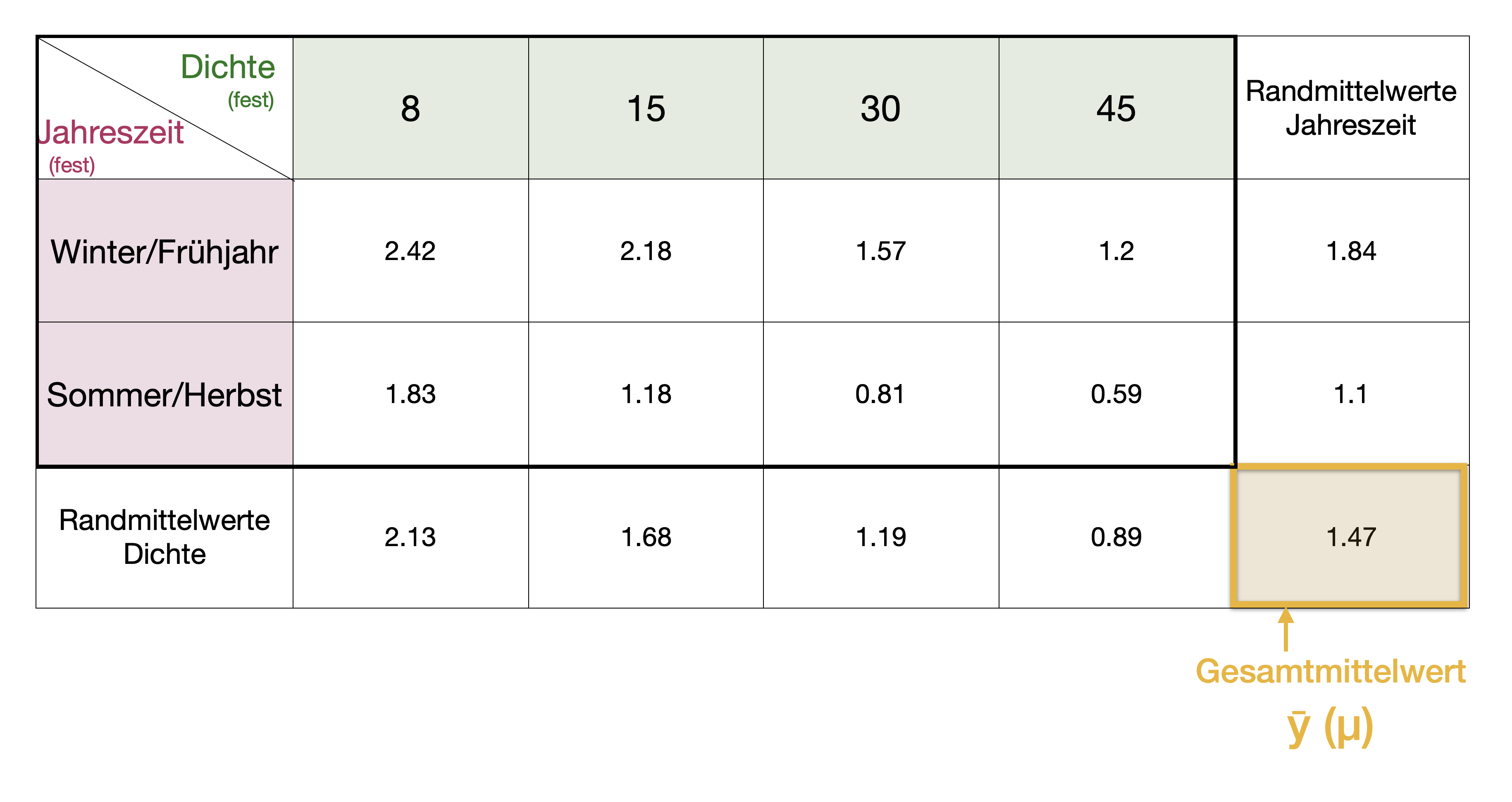
Napfschnecken Versuch | Gesamtmittelwert
Napfschnecken Versuch | Randmittelwerte
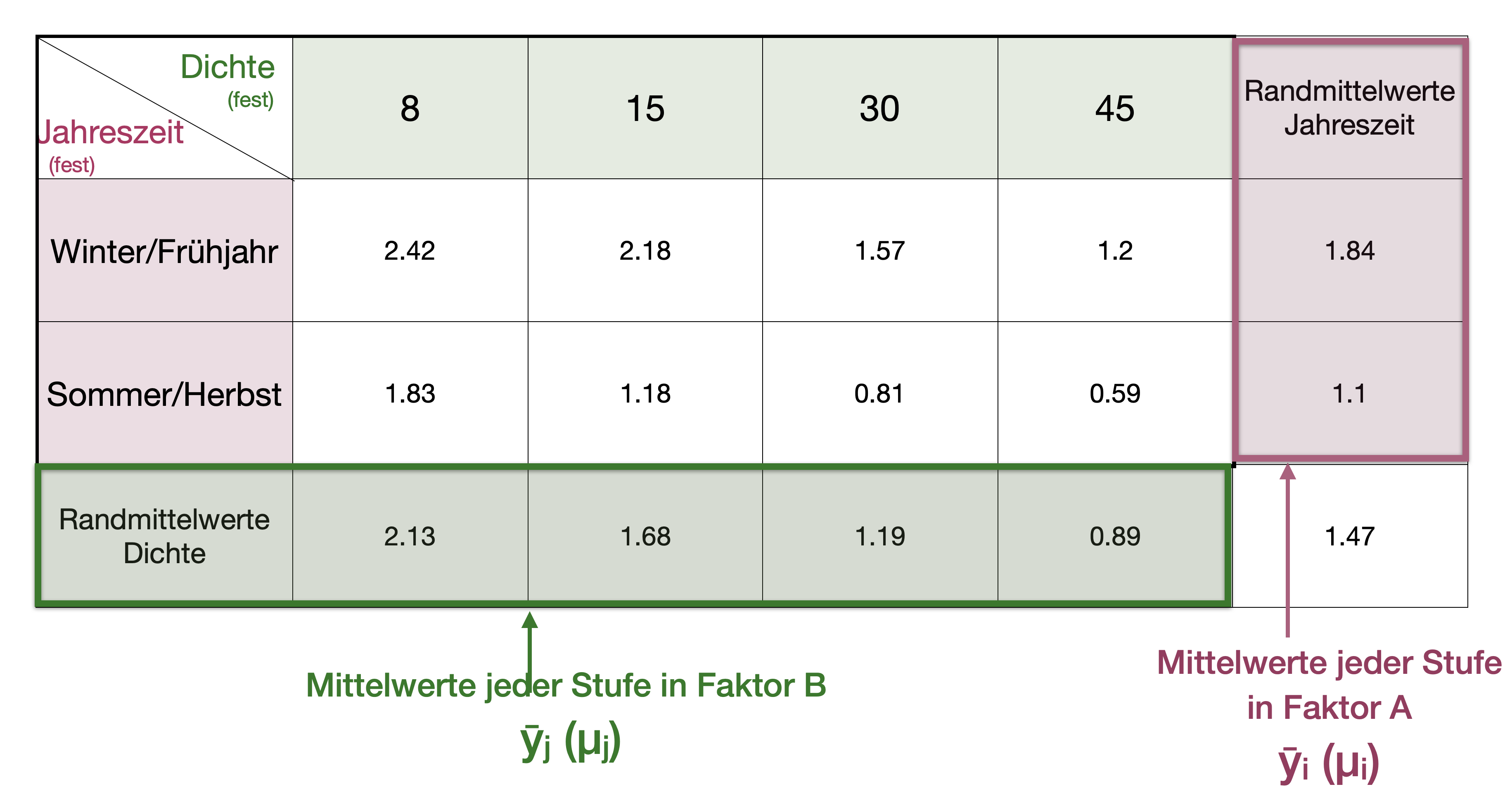
Hypothesen der beiden Haupteffekte

Interaktionen | Mögliche Effekte

Interaktionen | Grafisch explorieren
![]()
Hier ein Beispiel mit einfachen Boxplots:

ANOVA Tabelle bei 2 gekreuzten Faktoren

Berechnung der F-Werte

Interpretation der Ergebnisse
![]()
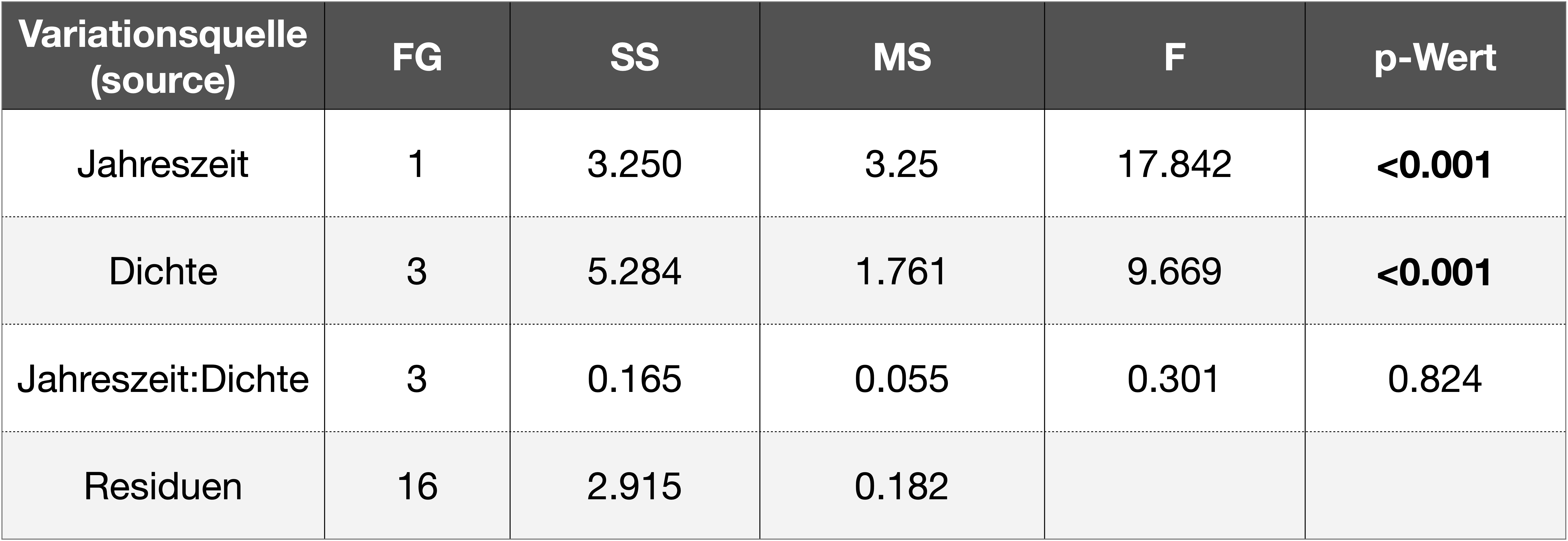
\(\Rightarrow\) Es gibt keine signifikante Interaktion.
\(\Rightarrow\) Es gibt einen sign. Effekt der Jahreszeit und der Dichte auf die Fruchtbarkeit von Napfschnecken (Siphonaria diemenensis).
Durchführung in R | 1
![]()
![]()
ANOVA mit Interaktion
Df Sum Sq Mean Sq F value Pr(>F)
season 1 3.250 3.250 17.842 0.000645 ***
density 3 5.284 1.761 9.669 0.000704 ***
season:density 3 0.165 0.055 0.301 0.823955
Residuals 16 2.915 0.182
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1Durchführung in R | 2
![]()
![]()
Modelldiagnostik
![]()
![]()

Interaktion visualisieren
![]()
![]()

Effektgröße | numerisch
![]()
![]()
Effektgröße | grafisch
![]()
![]()


,_male.jpg){kind=link}
{kind=link}
Fragen..??

Total konfus?
Hilfreiche Buchkapitel zum Nachlesen
- Kapitel 11.2 - Factorial experiments in The R Book von M.J. Crawley.
- Kapitel 9.2 - Factorial designs in Experimental Design and Data Analysis for Biologists von G.P. Quinn & M.J. Keough
Übungsaufgabe
Übung
![]()
- Durchführung einer 2-faktoriellen ANOVA zu einem Fütterungsexperiment.
- Das R Notebook und der Datensatz sind im Moodlekurs (Woche 1) zu finden.
Total gelangweilt?

Dann testen Sie doch Ihr Wissen in folgendem Abschlussquiz…
Abschlussquiz
![]()
Bei weiteren Fragen: saskia.otto(at)uni-hamburg.de

Diese Arbeit is lizenziert unter einer Creative Commons Attribution-ShareAlike 4.0 International License mit Ausnahme der entliehenen und mit Quellenangabe versehenen Abbildungen.