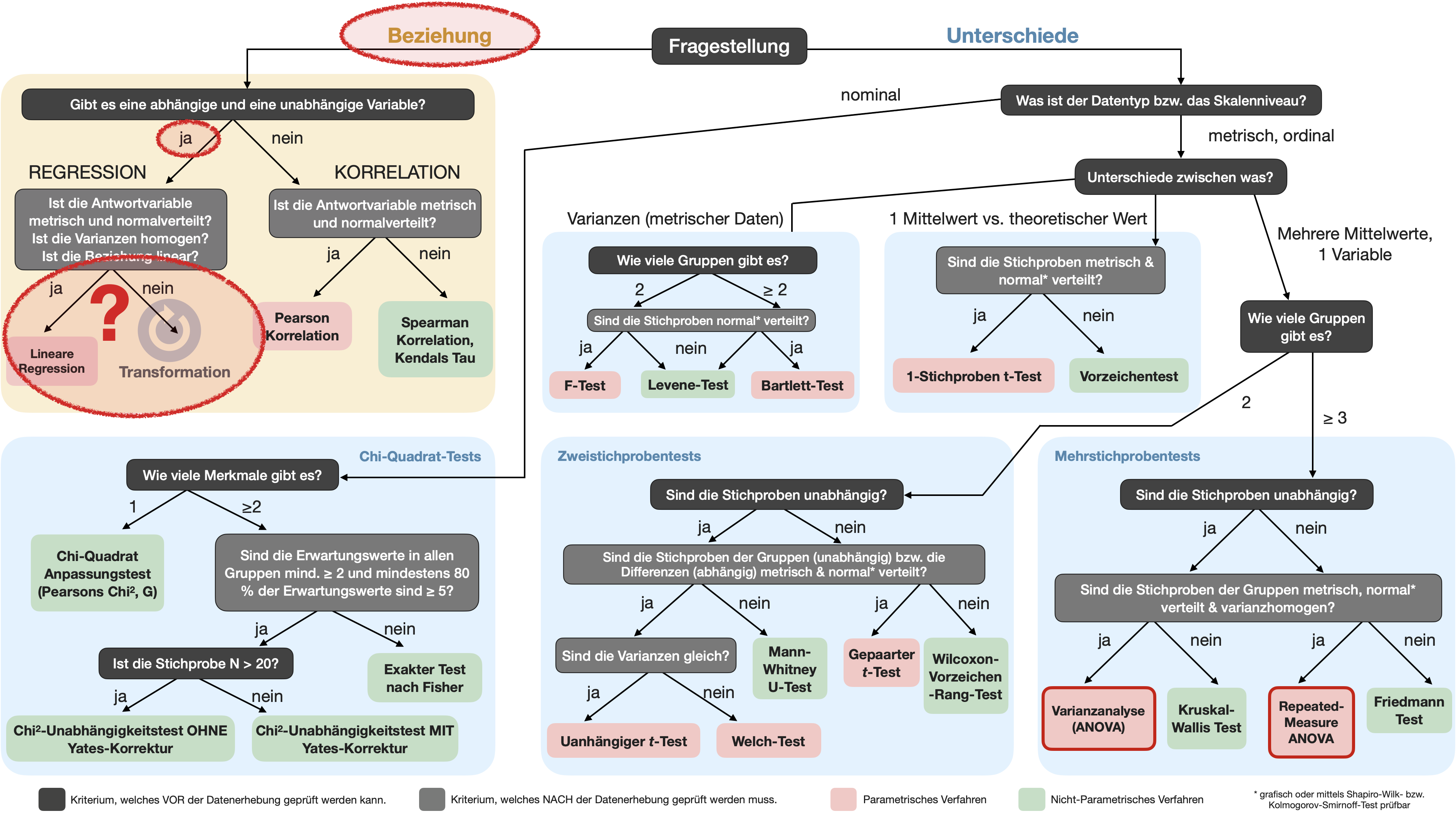
[1] 86 22 10 82
Chi-squared test for given probabilities
data: observed
X-squared = 0.96299, df = 3, p-value = 0.8102Data Science 2
Universität Hamburg, IMF & IZS
Sommersemester 2026
Angenommen, wir haben eine Stichprobe von Personen und möchten untersuchen, ob die Verteilung der Blutgruppen in dieser Stichprobe mit der bekannten Verteilung in der allgemeinen Bevölkerung übereinstimmt. Die bekannten prozentualen Verteilungen der Blutgruppen in der allgemeinen Bevölkerung in Deutschland sind:
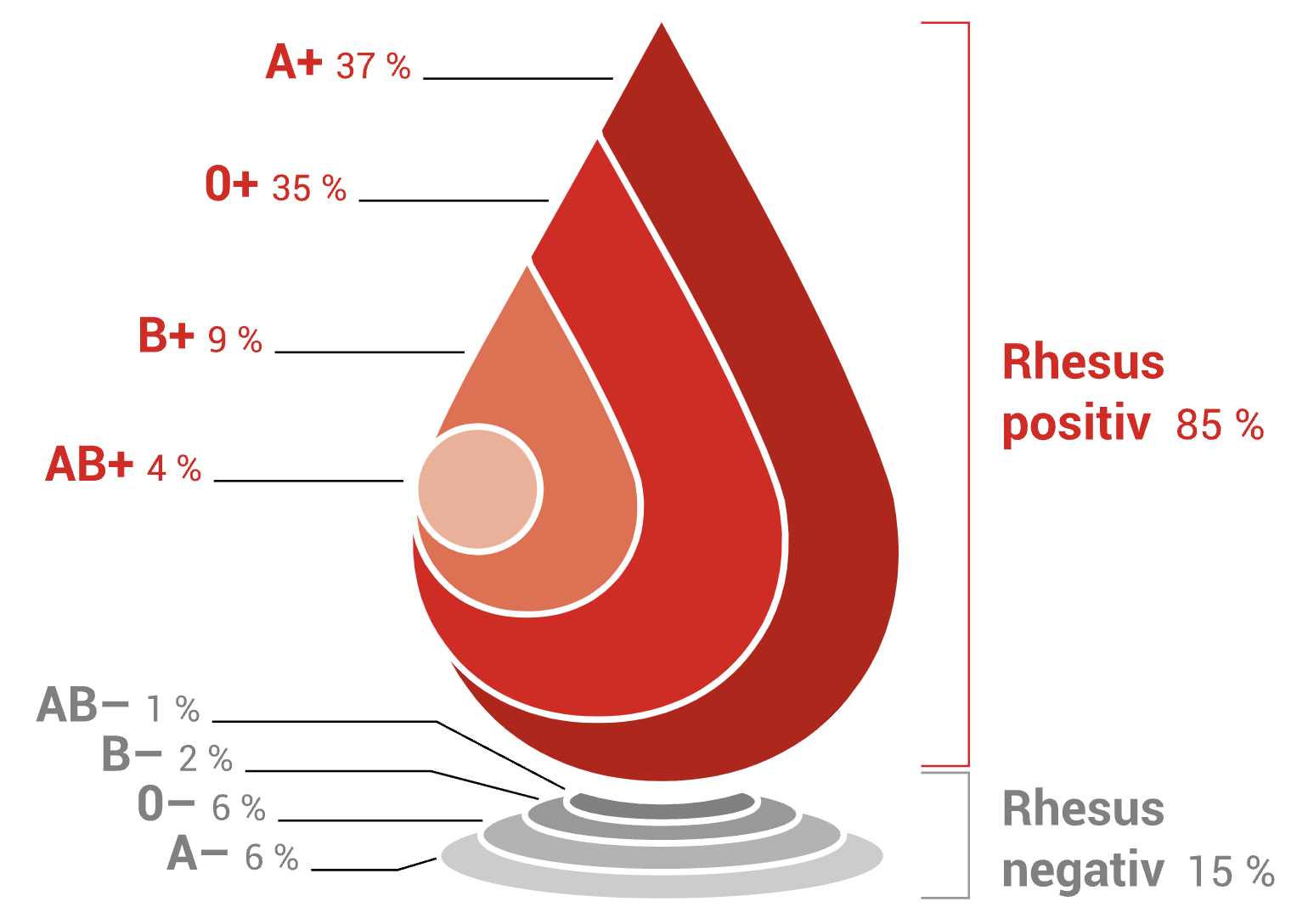
Bildquelle: DRK
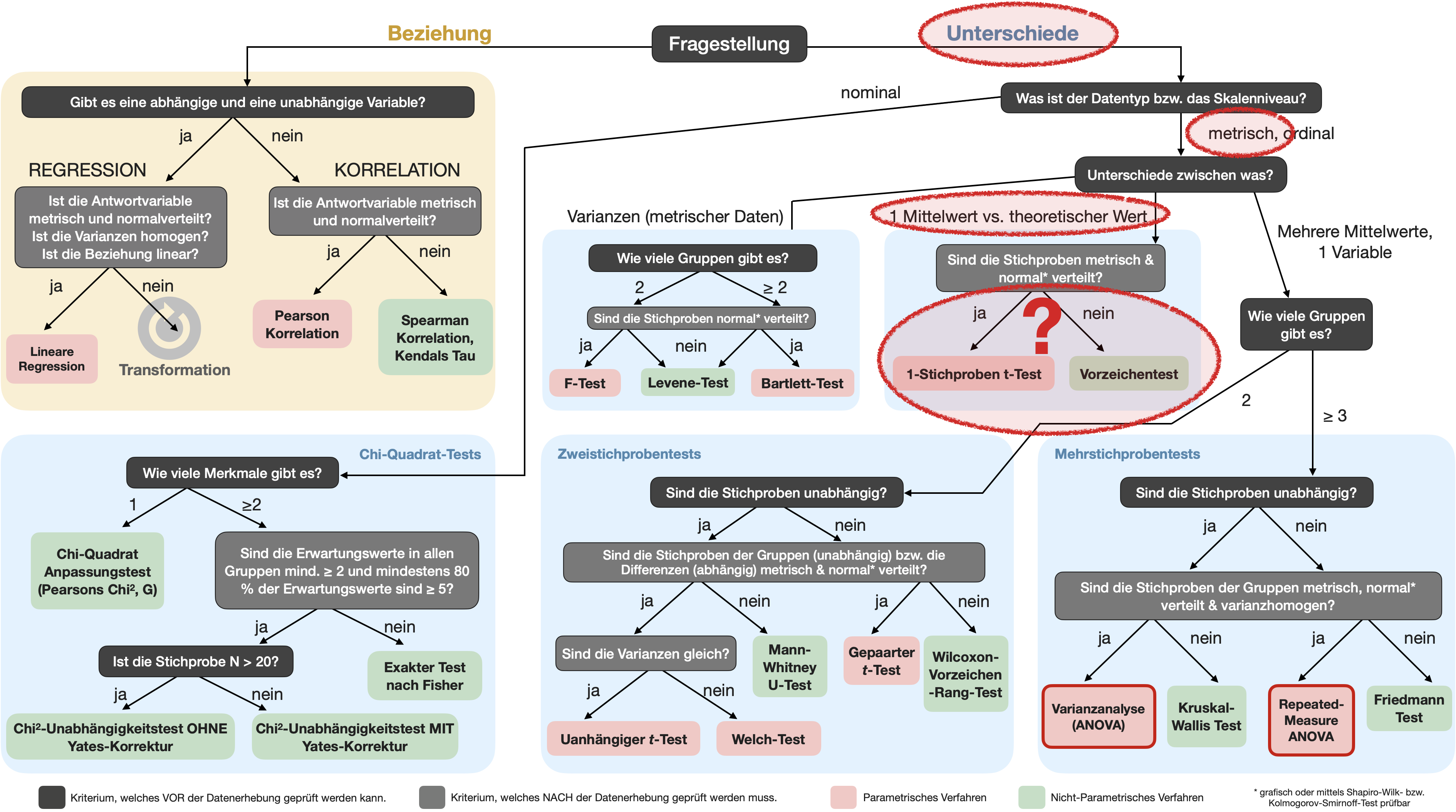
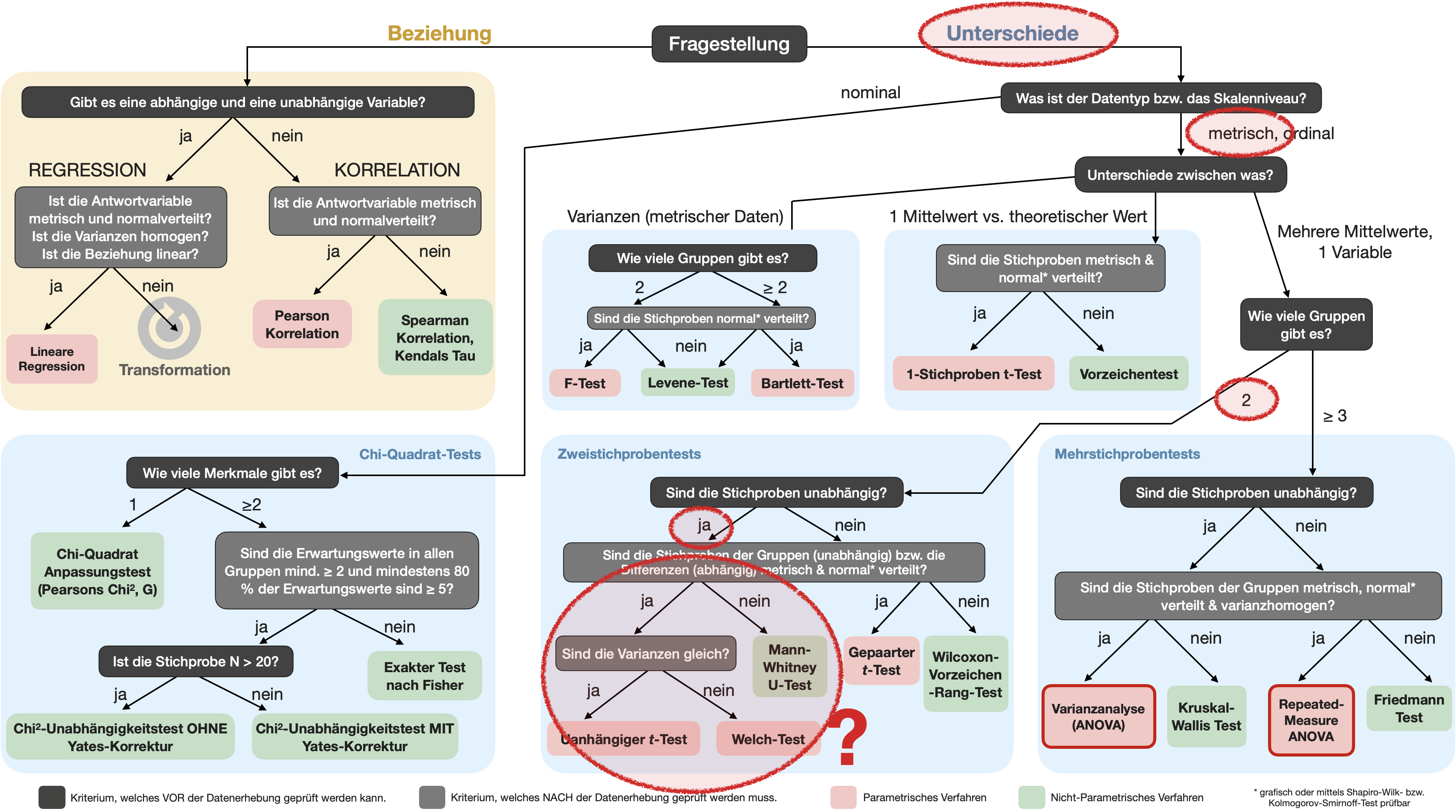
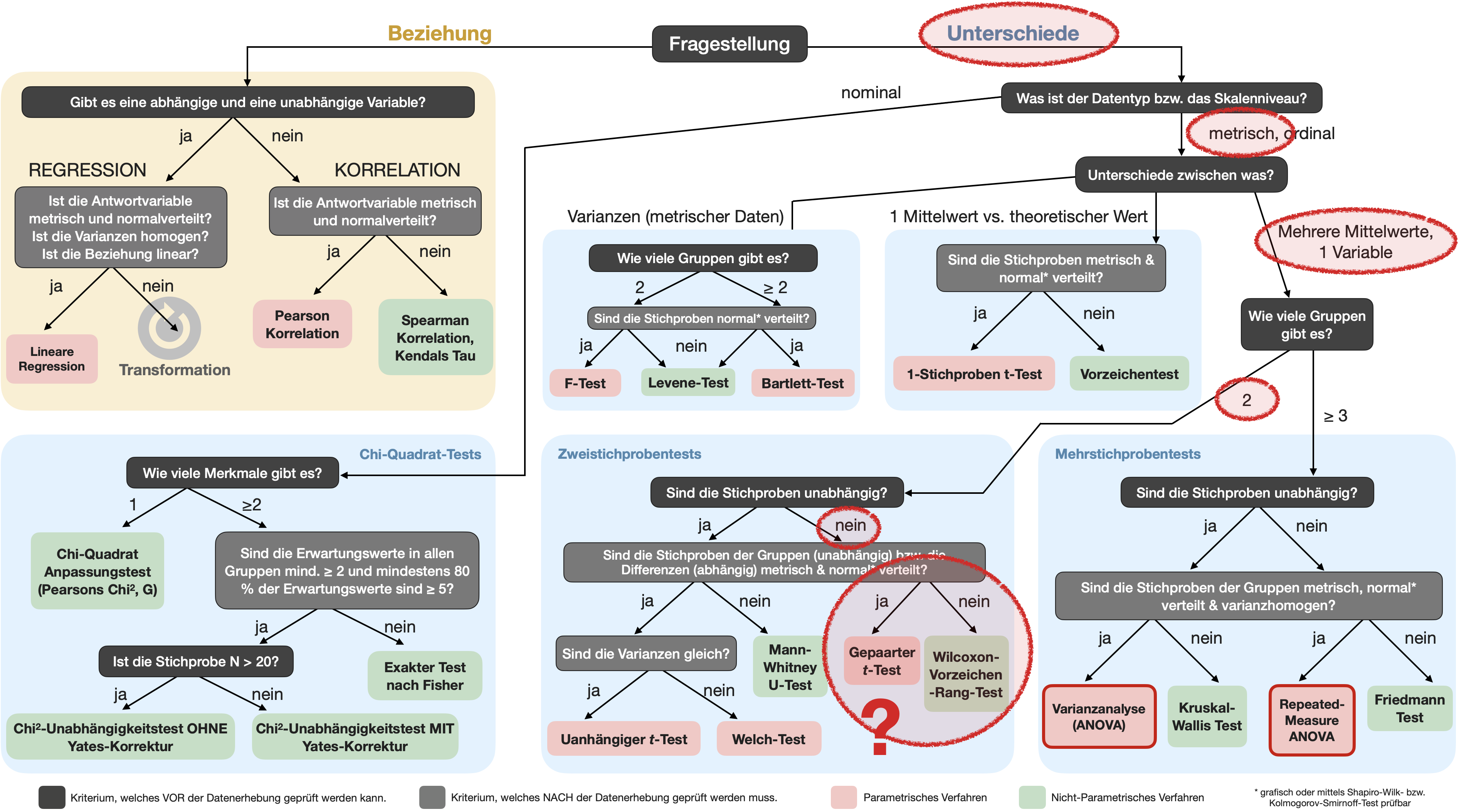
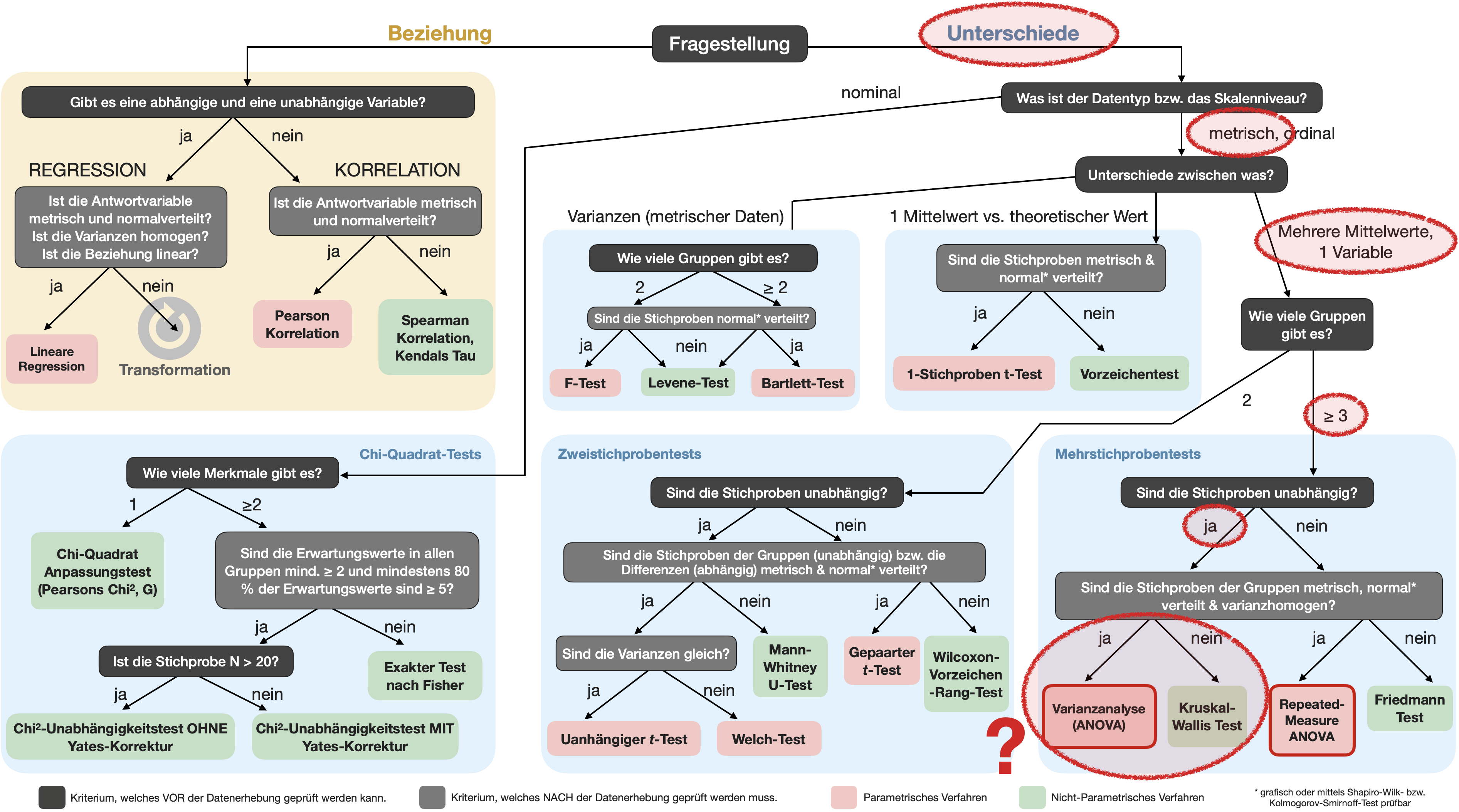
Unterscheidet sich die Verteilung der Blutgruppen in unserer Stichprobe signifikant von der bekannten Verteilung in der allgemeinen Bevölkerung?
![]()
[1] 86 22 10 82
Chi-squared test for given probabilities
data: observed
X-squared = 0.96299, df = 3, p-value = 0.8102![]()
Shapiro-Wilk normality test
data: cholesterin
W = 0.97575, p-value = 0.9322
One Sample t-test
data: cholesterin
t = -3.0578, df = 14, p-value = 0.004258
alternative hypothesis: true mean is less than 200
95 percent confidence interval:
-Inf 196.6928
sample estimates:
mean of x
192.2 ![]()
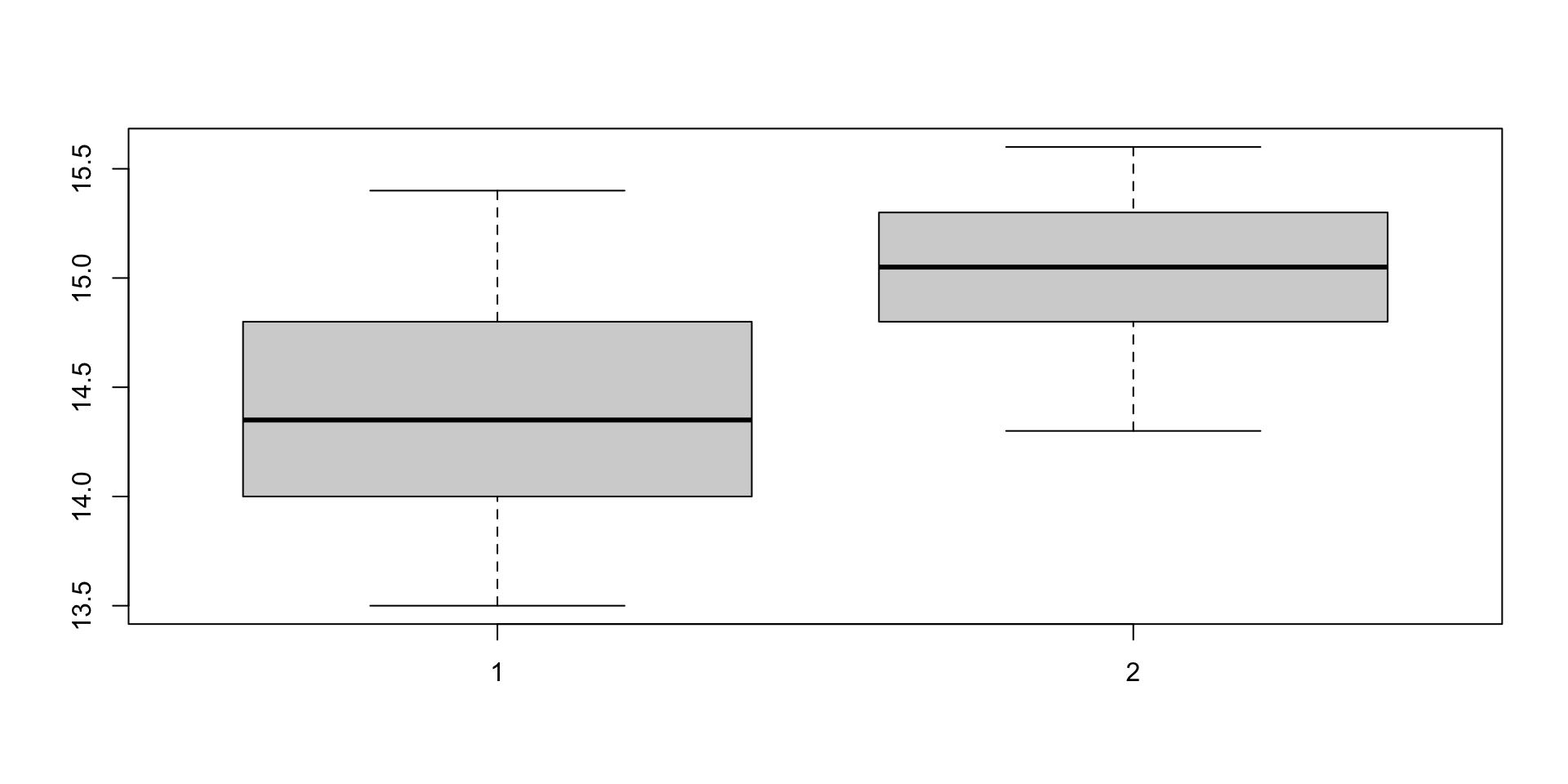
Shapiro-Wilk normality test
data: wachstum_A
W = 0.98385, p-value = 0.9824
Shapiro-Wilk normality test
data: wachstum_B
W = 0.98146, p-value = 0.9725
F test to compare two variances
data: wachstum_A and wachstum_B
F = 2.1767, num df = 9, denom df = 9, p-value = 0.2621
alternative hypothesis: true ratio of variances is not equal to 1
95 percent confidence interval:
0.5406581 8.7633260
sample estimates:
ratio of variances
2.176686
Two Sample t-test
data: wachstum_A and wachstum_B
t = -2.8712, df = 18, p-value = 0.01016
alternative hypothesis: true difference in means is not equal to 0
95 percent confidence interval:
-1.090981 -0.169019
sample estimates:
mean of x mean of y
14.41 15.04 ![]()
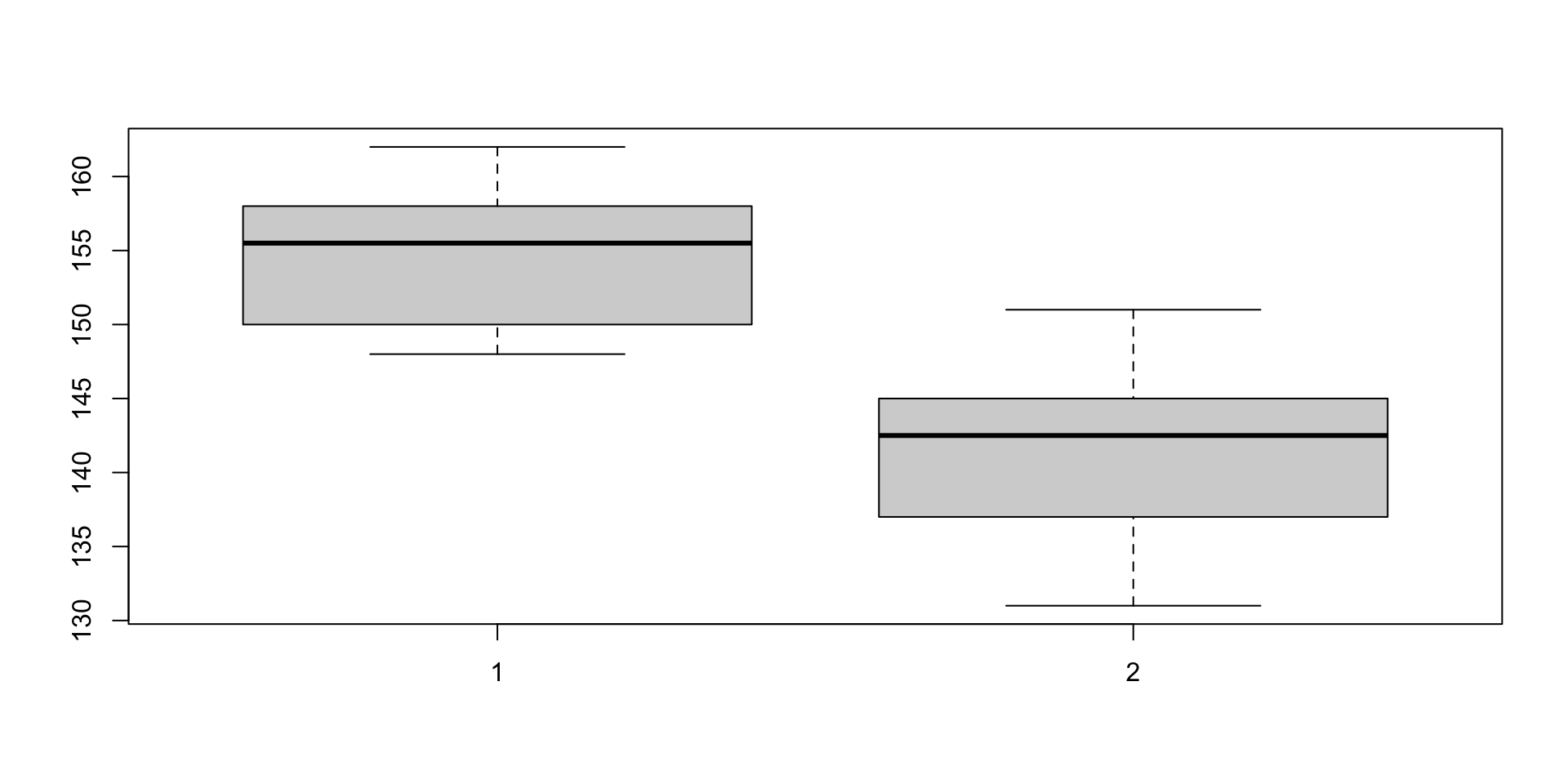
Shapiro-Wilk normality test
data: diff
W = 0.90682, p-value = 0.2598
Paired t-test
data: blutdruck_vor and blutdruck_nach
t = 8.5513, df = 9, p-value = 1.295e-05
alternative hypothesis: true mean difference is not equal to 0
95 percent confidence interval:
9.560992 16.439008
sample estimates:
mean difference
13
One Sample t-test
data: diff
t = 8.5513, df = 9, p-value = 1.295e-05
alternative hypothesis: true mean is not equal to 0
95 percent confidence interval:
9.560992 16.439008
sample estimates:
mean of x
13 ![]()
# Genexpressionsdaten und Behandlungsmethoden
behandlung <- factor(rep(c("1", "2", "3"), each = 5))
genexpression <- c(500, 510, 480, 495, 505,
530, 540, 520, 535, 525,
490, 495, 485, 500, 505)
daten <- data.frame(behandlung, genexpression)
# Datenexploration
boxplot(genexpression ~ behandlung, data = daten)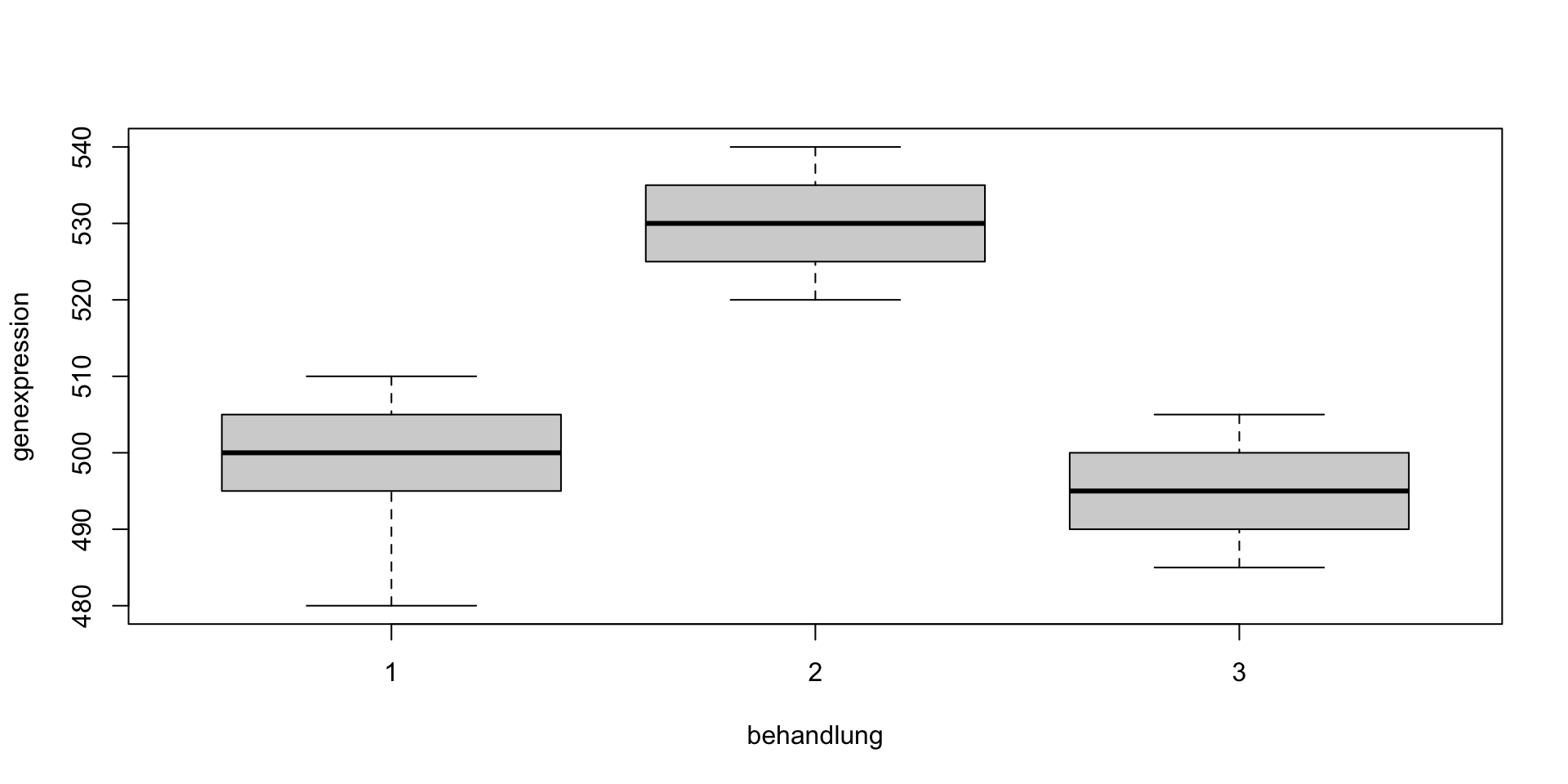
Levene's Test for Homogeneity of Variance (center = median)
Df F value Pr(>F)
group 2 0.2162 0.8086
12 
Df Sum Sq Mean Sq F value Pr(>F)
behandlung 2 3763 1881.7 21.92 9.84e-05 ***
Residuals 12 1030 85.8
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1 Tukey multiple comparisons of means
95% family-wise confidence level
Fit: aov(formula = genexpression ~ behandlung, data = daten)
$behandlung
diff lwr upr p adj
2-1 32 16.36775 47.63225 0.0003940
3-1 -3 -18.63225 12.63225 0.8669957
3-2 -35 -50.63225 -19.36775 0.0001771![]()
Es gibt einen hoch signifikanten Unterschied der Genexpression zwischen den 3 Behandlungsstufen (1-faktorielle ANOVA, F = 21.9, FG_{Behandlung} = 2, FG_{Residuen} = 12, p < 0.001).
Die Genexpression ist unter Behandlung 2 mit einer Differenz von 32 bzw. 35 signifikant höher als unter Gruppe 1 bzw. 2 (Tukey HSD, p jeweils < 0.001). Es gibt allerdings keine signifikanten Unterschiede zwischen Gruppe 1 und 3.
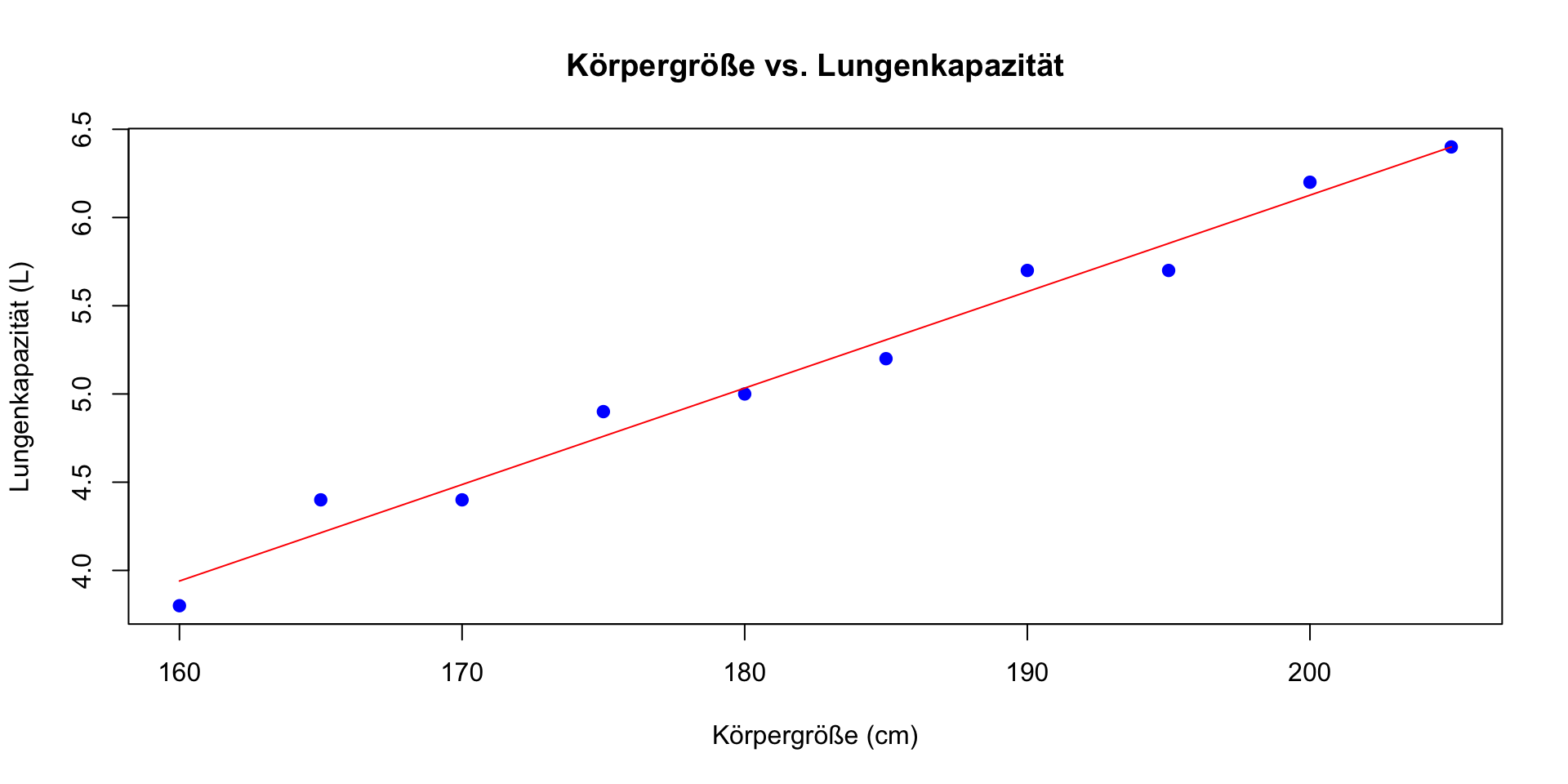
| Person | Körpergröße (cm) | Lungenkapazität (L) |
|---|---|---|
| 1 | 160 | 3.8 |
| 2 | 165 | 4.4 |
| 3 | 170 | 4.4 |
| 4 | 175 | 4.9 |
| 5 | 180 | 5.0 |
| 6 | 185 | 5.2 |
| 7 | 190 | 5.7 |
| 8 | 195 | 5.7 |
| 9 | 200 | 6.2 |
| 10 | 205 | 6.4 |
![]()
# Körpergrößen- und Lungenkapazitätsdaten
koerpergroesse <- c(160, 165, 170, 175, 180, 185, 190, 195, 200, 205)
lungenkapazitaet <- c(3.8, 4.4, 4.4, 4.9, 5.0, 5.2, 5.7, 5.7, 6.2, 6.4)
daten <- data.frame(koerpergroesse, lungenkapazitaet)
# Datenexploration --> Linearität vorab prüfen
# weitere Annahmen werden anhand der Residuen geprüft
plot(koerpergroesse, lungenkapazitaet)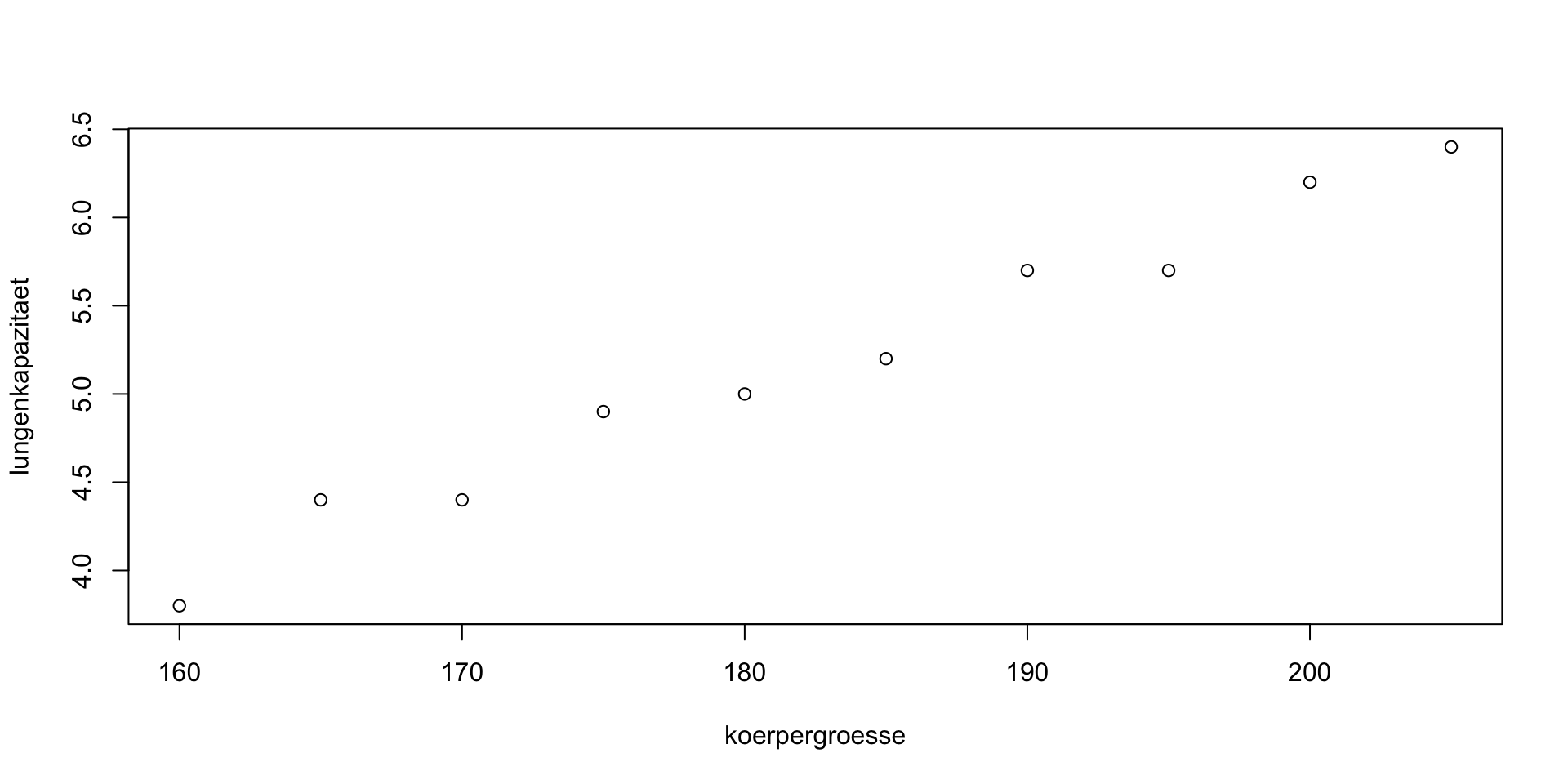
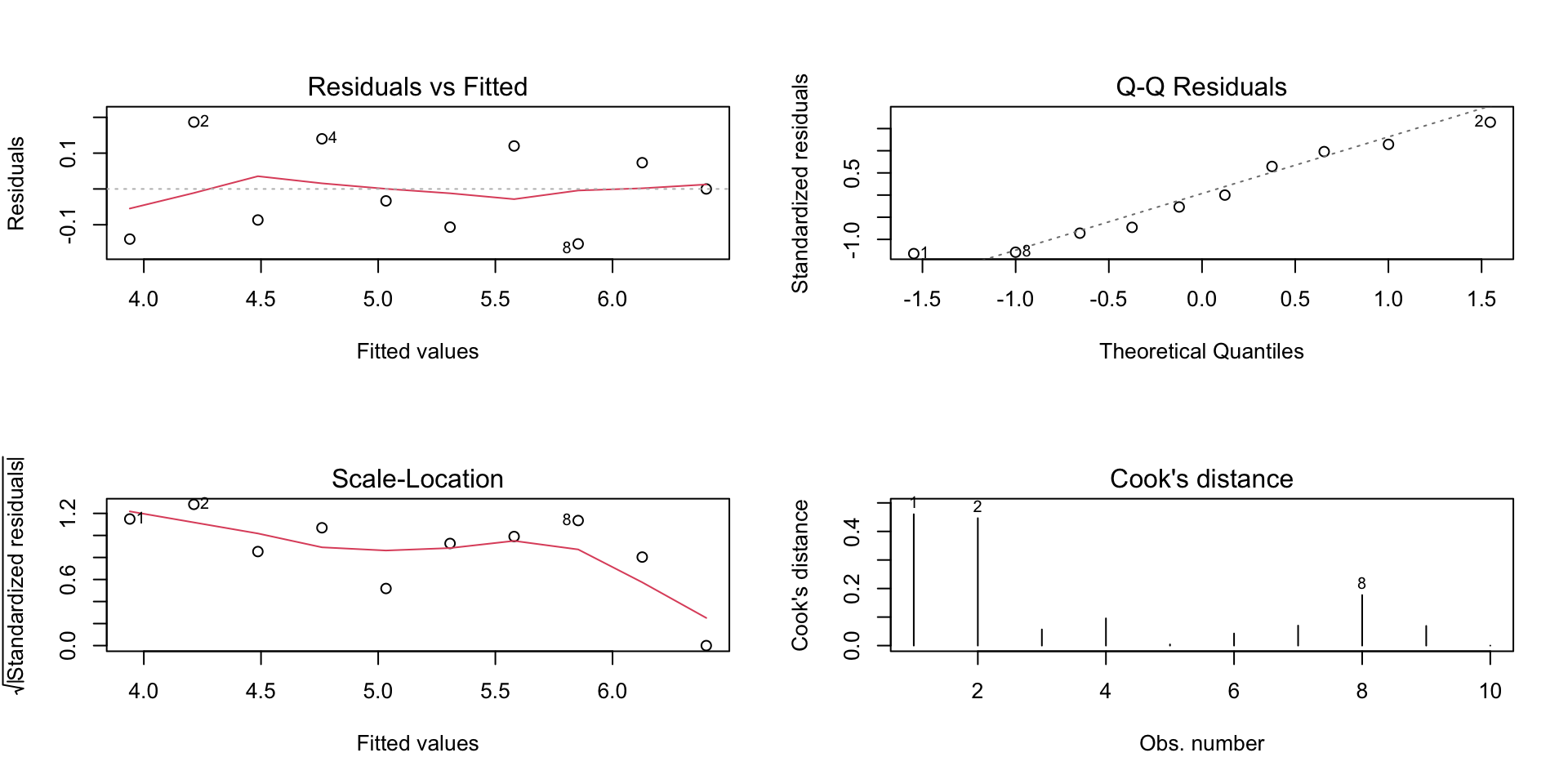
Call:
lm(formula = lungenkapazitaet ~ koerpergroesse, data = daten)
Residuals:
Min 1Q Median 3Q Max
-0.15333 -0.10167 -0.01667 0.10833 0.18667
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) -4.806667 0.528140 -9.101 1.71e-05 ***
koerpergroesse 0.054667 0.002885 18.949 6.23e-08 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 0.131 on 8 degrees of freedom
Multiple R-squared: 0.9782, Adjusted R-squared: 0.9755
F-statistic: 359 on 1 and 8 DF, p-value: 6.225e-08![]()
Die Ausgabe des summary(regression_model) Befehls gibt Ihnen mehrere wichtige Informationen:
Multiple R-squared): Gibt an, wie viel der Variabilität in der Lungenkapazität durch die Körpergröße erklärt wird. Ein Wert nahe 1 bedeutet ein starker Erklärungsgehalt.Die Körpergröße hat einen hoch signifikanten, positiven Einfluss auf die Lungenkapazität (p < 0.001). Mit jedem Zentimeter Körpergröße steigt die Lungenkapazität um 0.05 Liter an. Das Modell zeigt mit einem Bestimmtheitsmaß von 0.98 eine sehr hohe Güte. Die Beziehung kann folgendermaßen zusammengefasst werden:
\text{Lungenkapazität}_i = -4.8 + 0.05 * \text{Körpergröße}_i + \epsilon_i
Bei weiteren Fragen: saskia.otto(at)uni-hamburg.de

Diese Arbeit is lizenziert unter einer Creative Commons Attribution-ShareAlike 4.0 International License mit Ausnahme der entliehenen und mit Quellenangabe versehenen Abbildungen.