11-Grundlagen des experimentellen Designs (Teil 1)
Data Science 2
Universität Hamburg, IMF & IZS
Sommersemester 2026
Lernziele
![]()
Am Ende dieser VL- und Übungseinheit werden Sie
- einige der wichtigsten Kriterien kennen, die in die Versuchsplanung mit einfließen.
- wissen, was die Power, Teststärke oder Trennschärfe eines Tests ist und welche Faktoren eine Rolle spielen.
- anhand der Poweranalyse die Teststärke, den optimalen Stichprobenumfang sowie den minimalen nachweisbaren Effekt beim Zwei- oder Mehr-Stichprobentest in R durchführen können.
- einen Überblick über nützliche R Funktionen und Pakete für weitere statistische Verfahren haben.
Wichtige Kriterien der Versuchsplanung

Einige Kriterien im einzelnen

Repräsentativität der Stichprobe
![]()
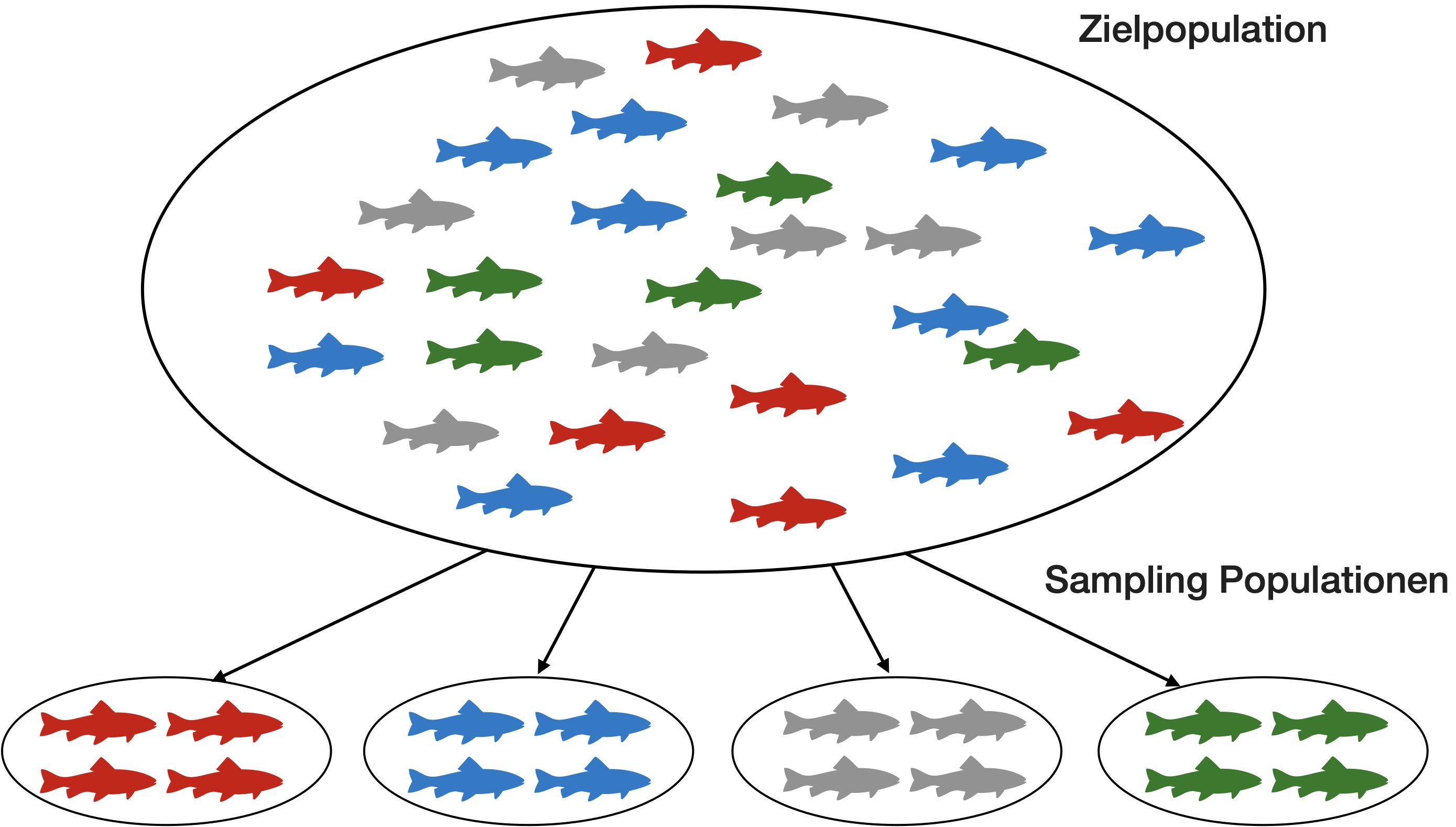
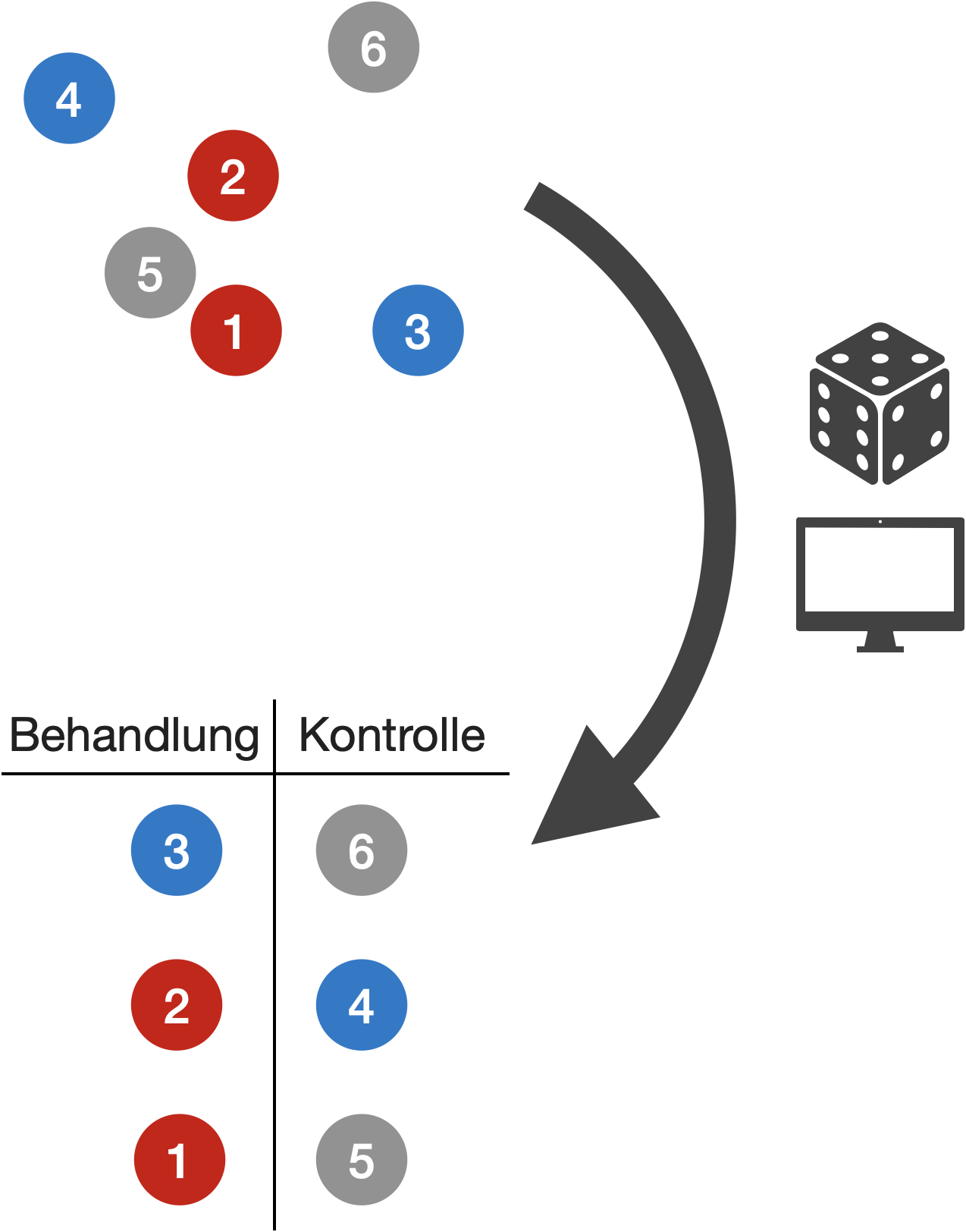
Randomisierung - der goldene Standard
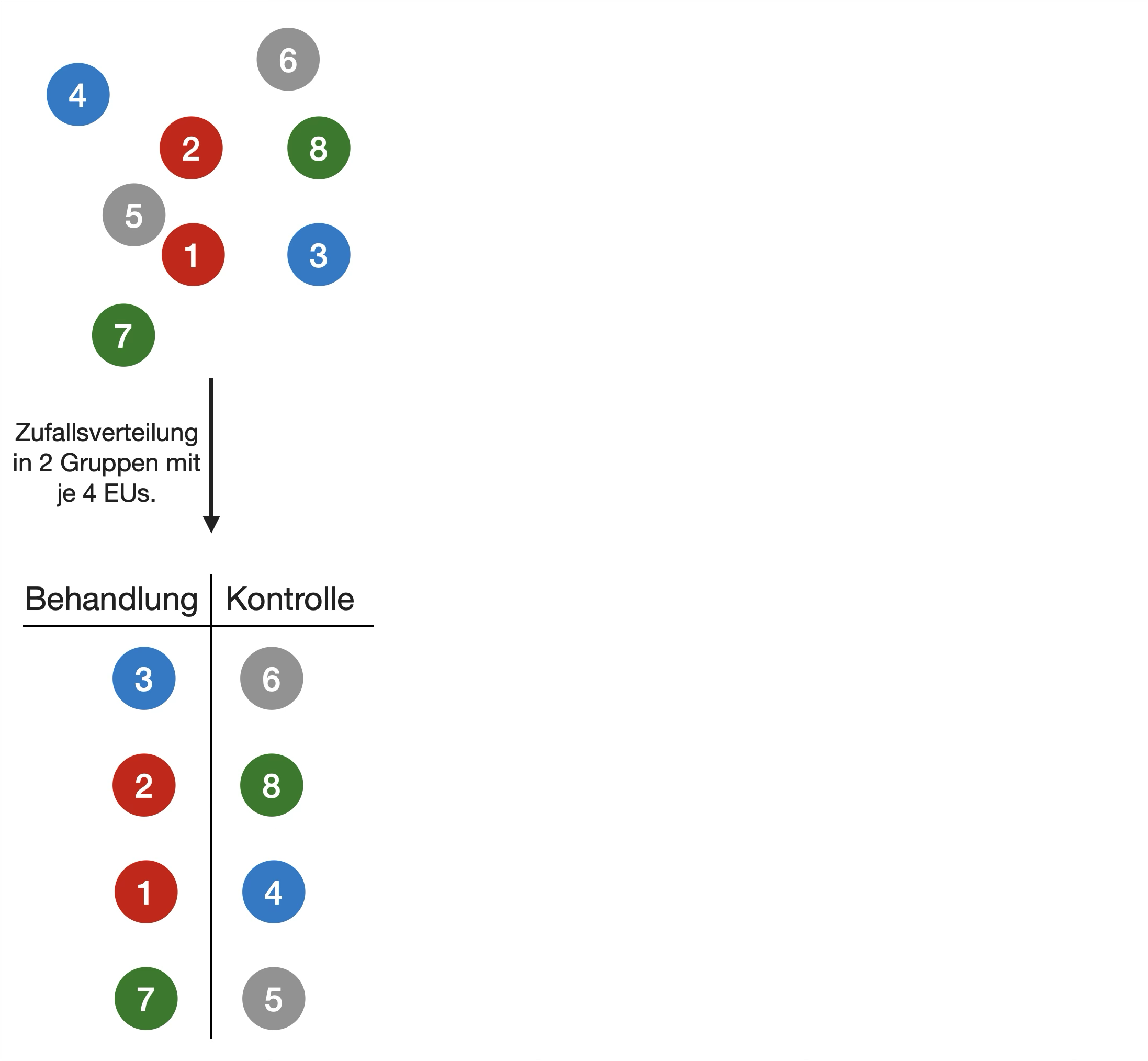
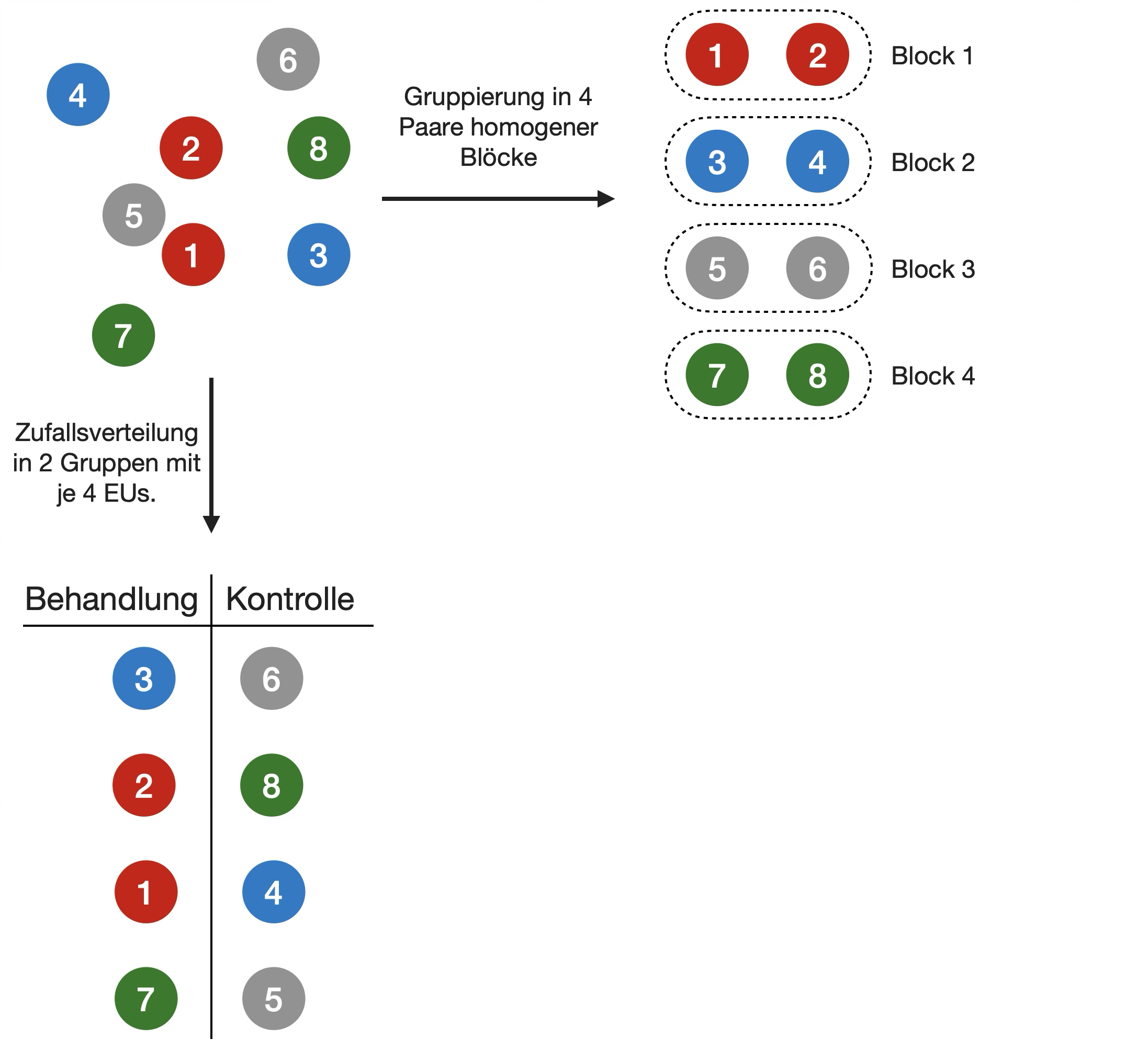
Blocking
- Wenn Variation zwischen den EUs (Experimental Units) groß ist → Behandlungsfehler schwer zu erkennen
- Ursachen für Variabilität:
- EUs sind heterogen
- EU bilden erkennbare Untergruppen (z. B. Männchen und Weibchen)
- EUs werden in Chargen gruppiert, um das Experimentverfahren zu vereinfachen → diese technischen Artefakte beeinflussen das Ergebnis
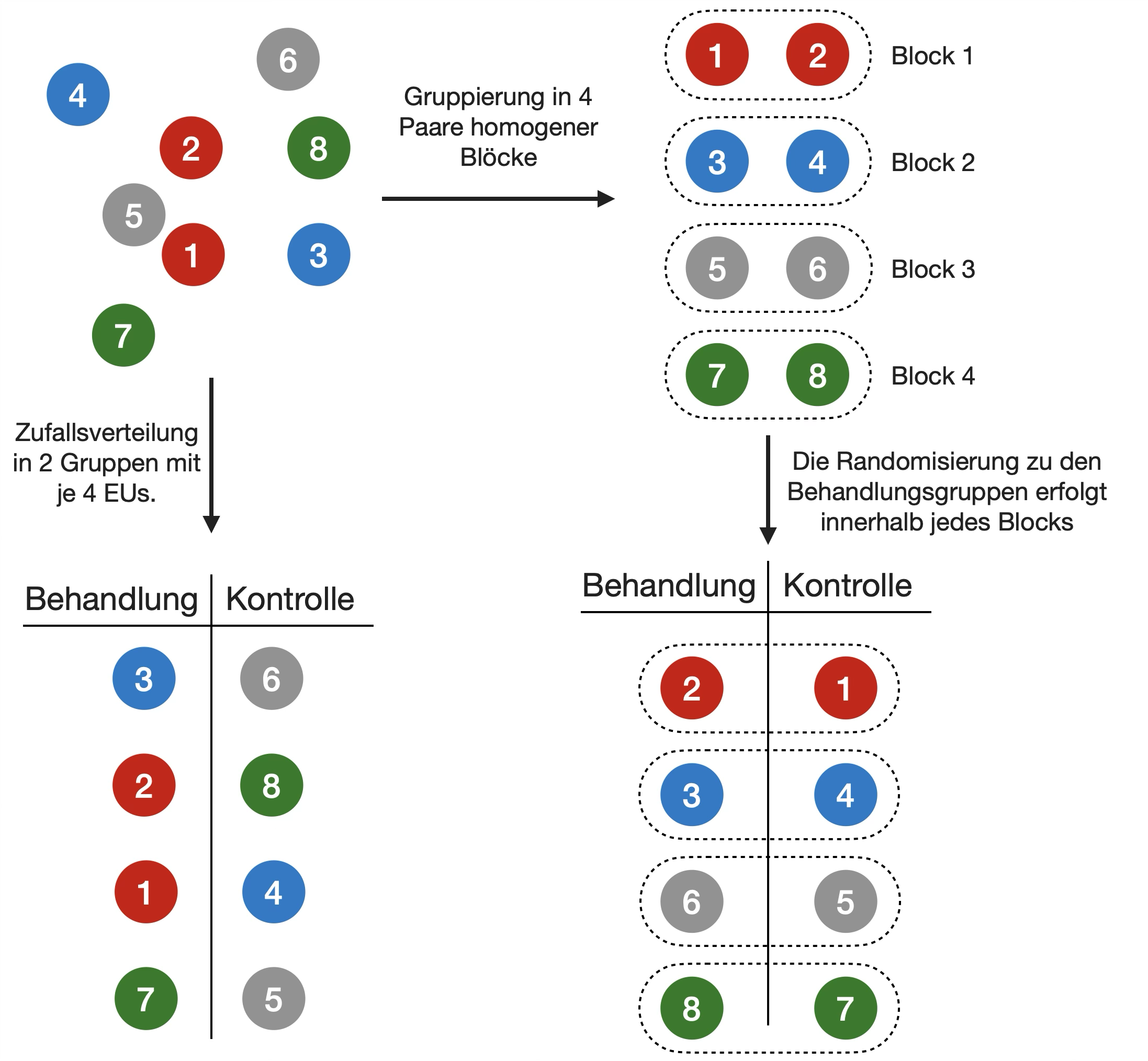
Übernommen aus:
Lazic (2016) Experimental Design for Laboratory Biologists
Kontrollen
Negative Kontrollen
- 2 Typen:
- Verfahrenskontrolle (‘Placebo’): Ähnliches Verfahren außer für die eigentliche Behandlung, z.B. Injektion von Kochsalzlösung anstelle von Medikamenten,.
- Naive Kontrolle: nützlich, wenn die Handhabung der Behandlung (z.B. die Injektion selbst) eine Wirkung hat.
- Wenn kein Unterschied zwischen beiden Kontrollen besteht, können sie zusammengelegt werden, um die Probengröße zu erhöhen.
Positive Kontrollen
- Zusätzliche Behandlung, von der bekannt ist, dass sie eine Wirkung hat → Baseline
- Nützlich, um zu prüfen, ob die EU überhaupt reagiert → Test ob Versuchsaufbau geeignet ist.
- Bei großer Wirkungsstärke der Behandlung keine Positivkontrolle erforderlich.
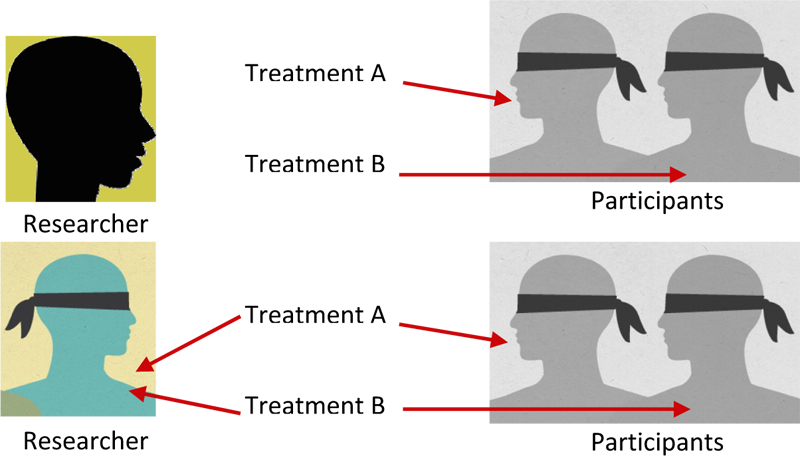
Blindproben
Blindproben und Doppel-Blindproben
Front- (FA) vs. end-alignment (EA)
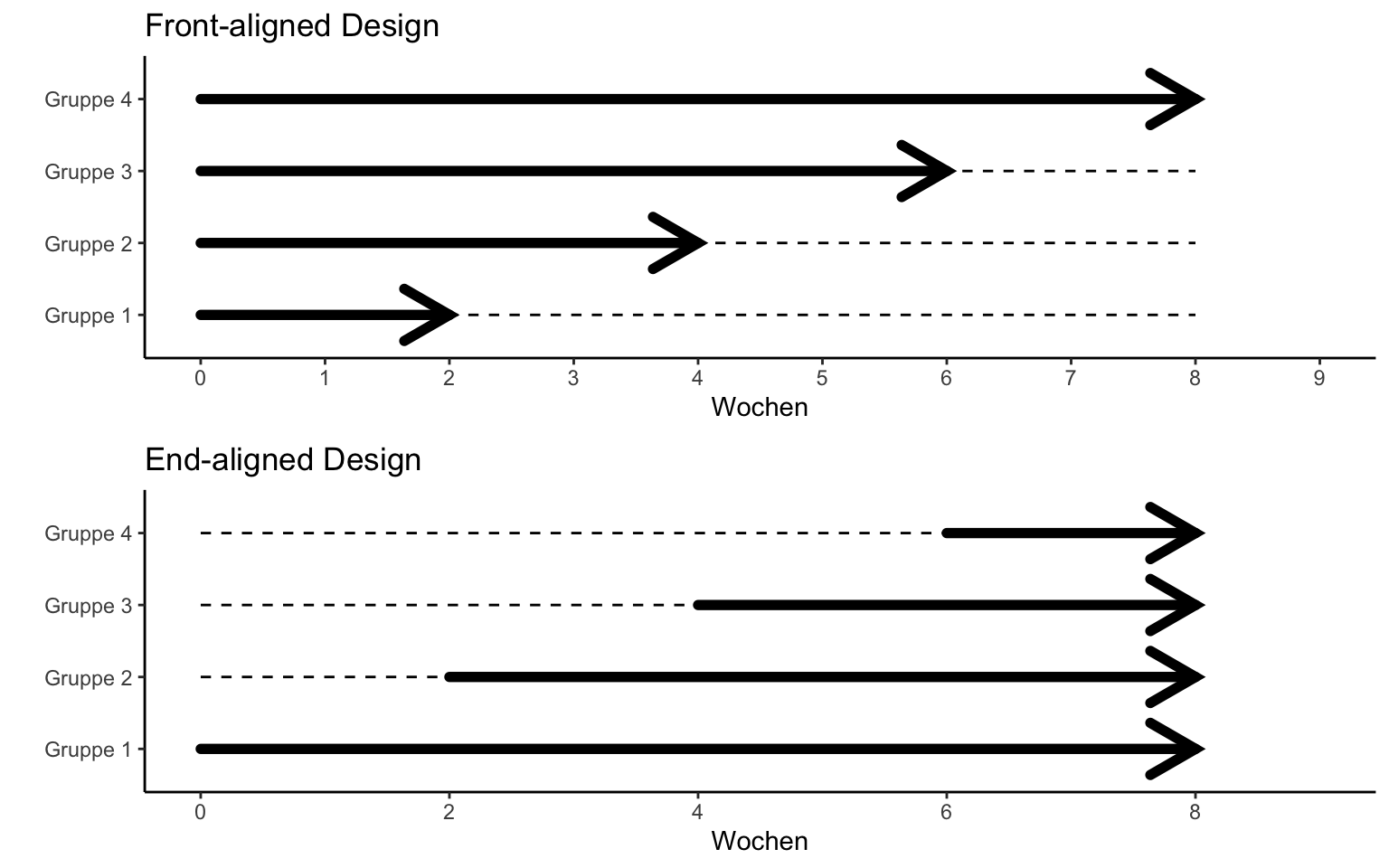
→ Je länger die Dauer, desto besser ein EA-Design!
Störeffekte | 1
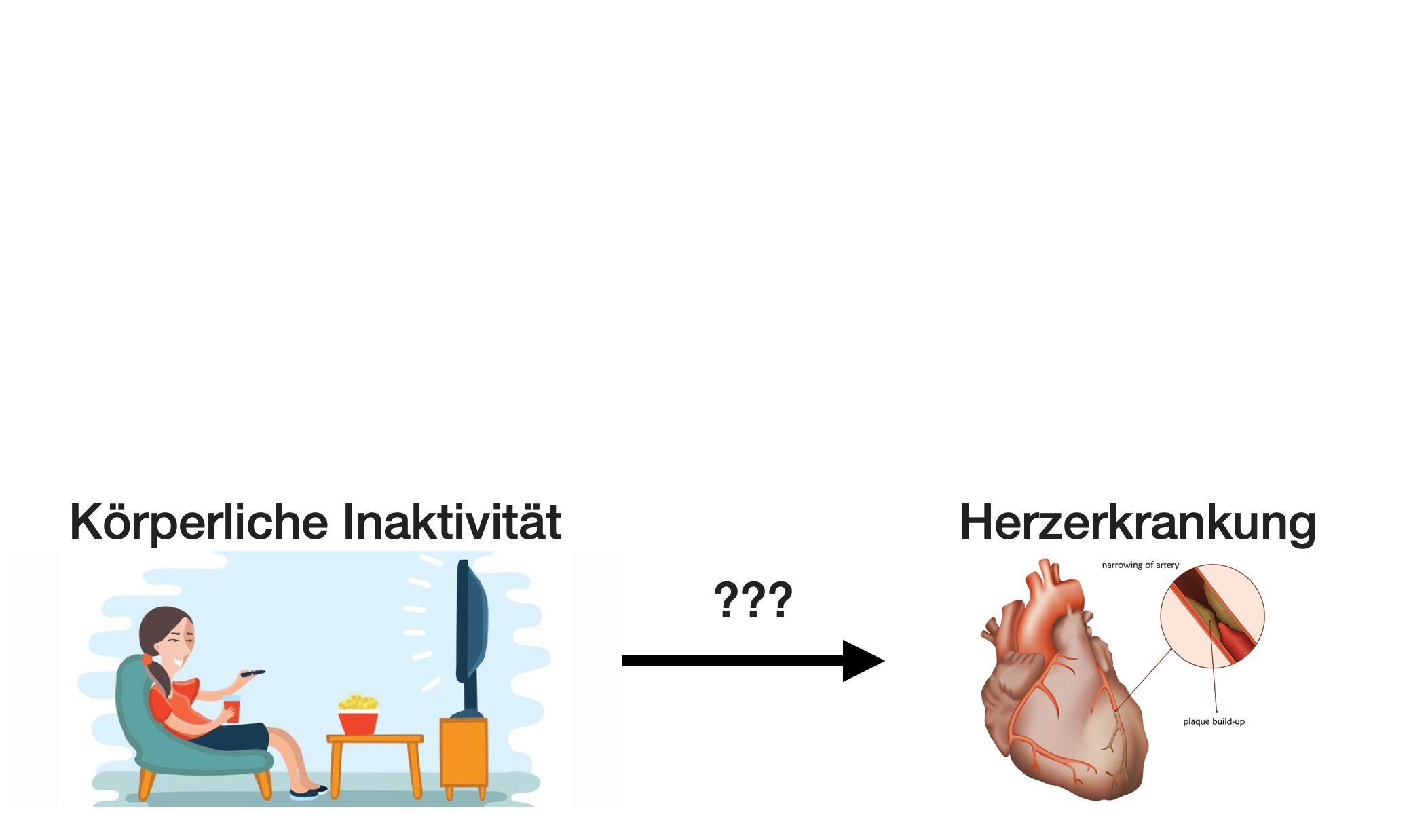
Störeffekte | 2
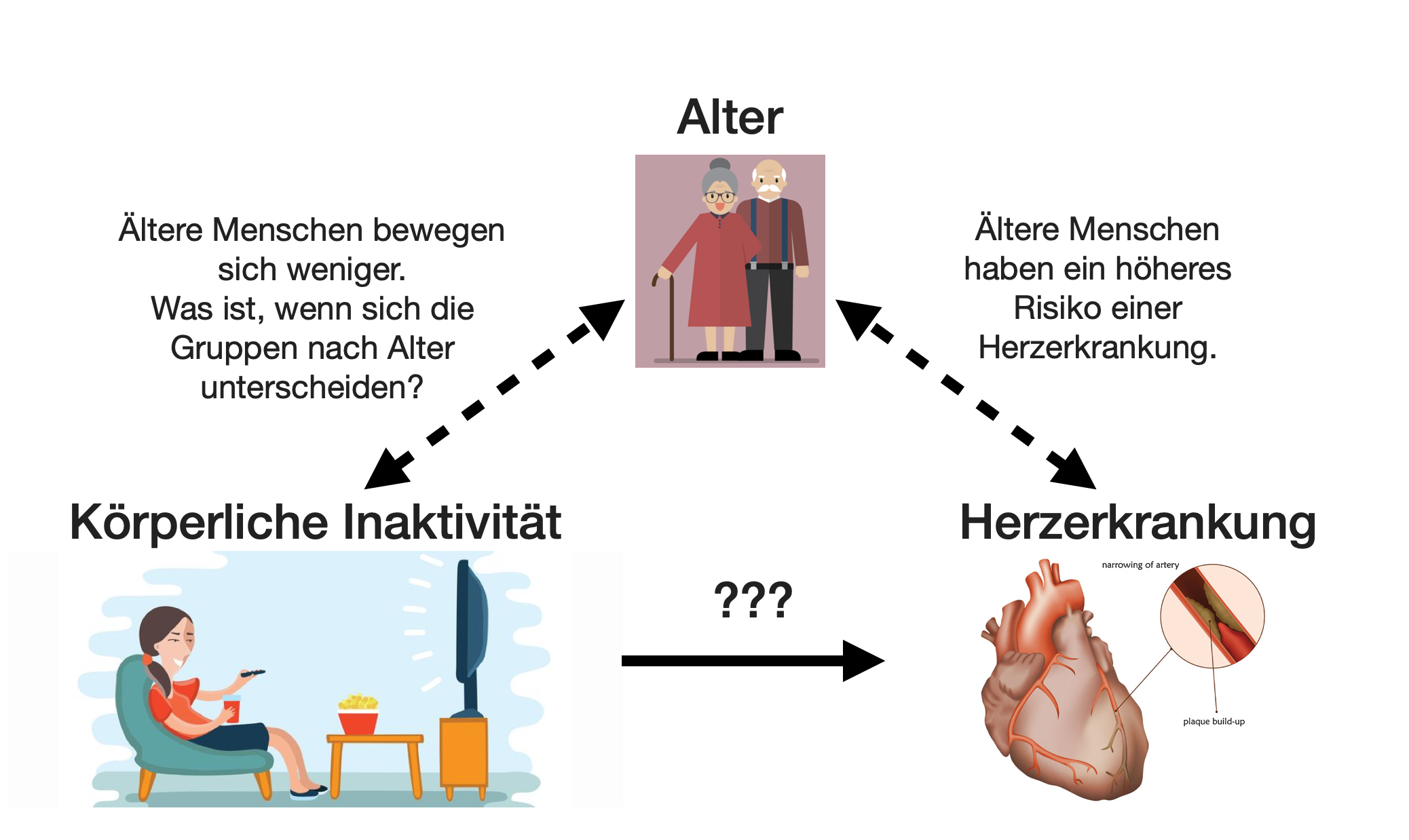
Störeffekte | 3
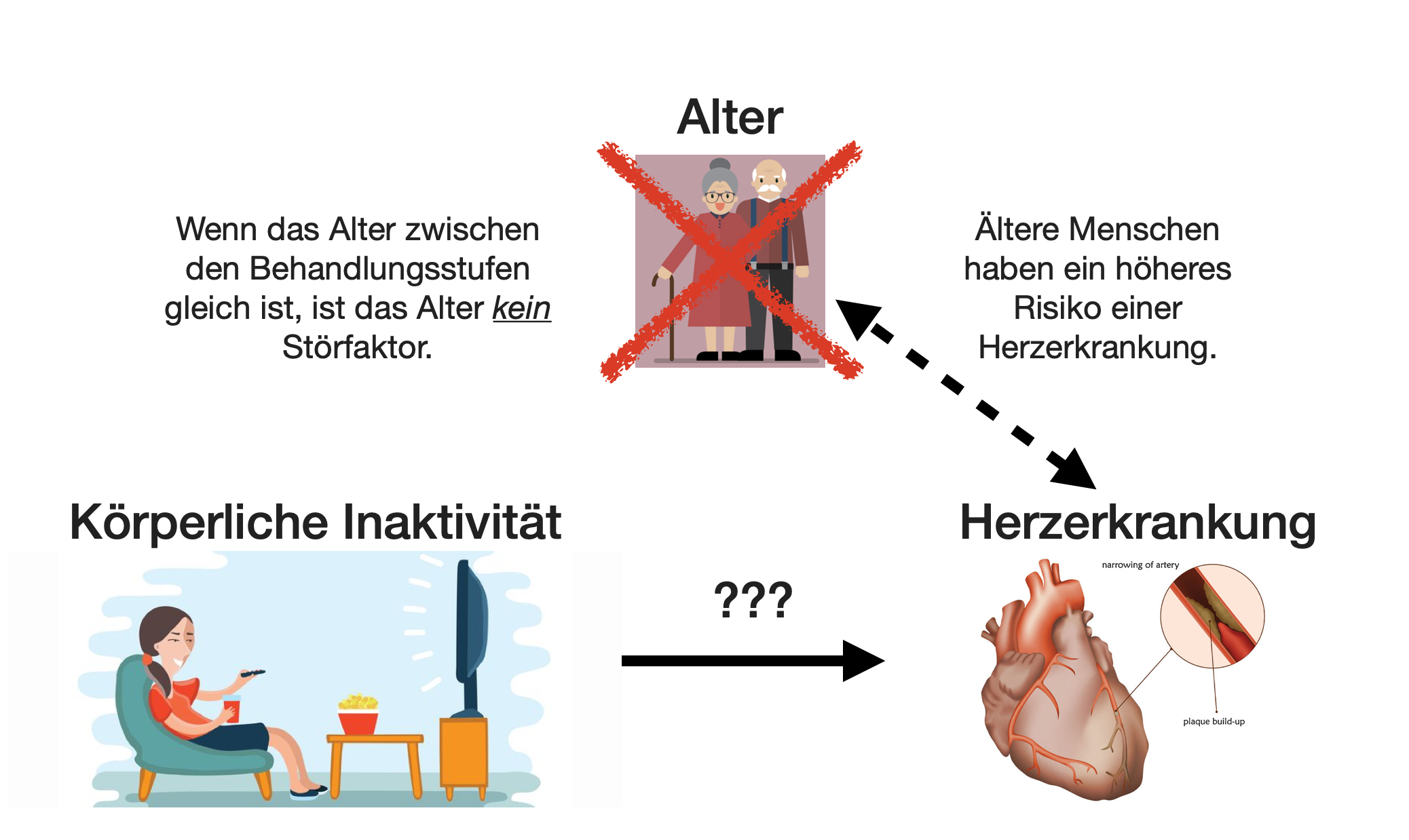
Störeffekte | 4
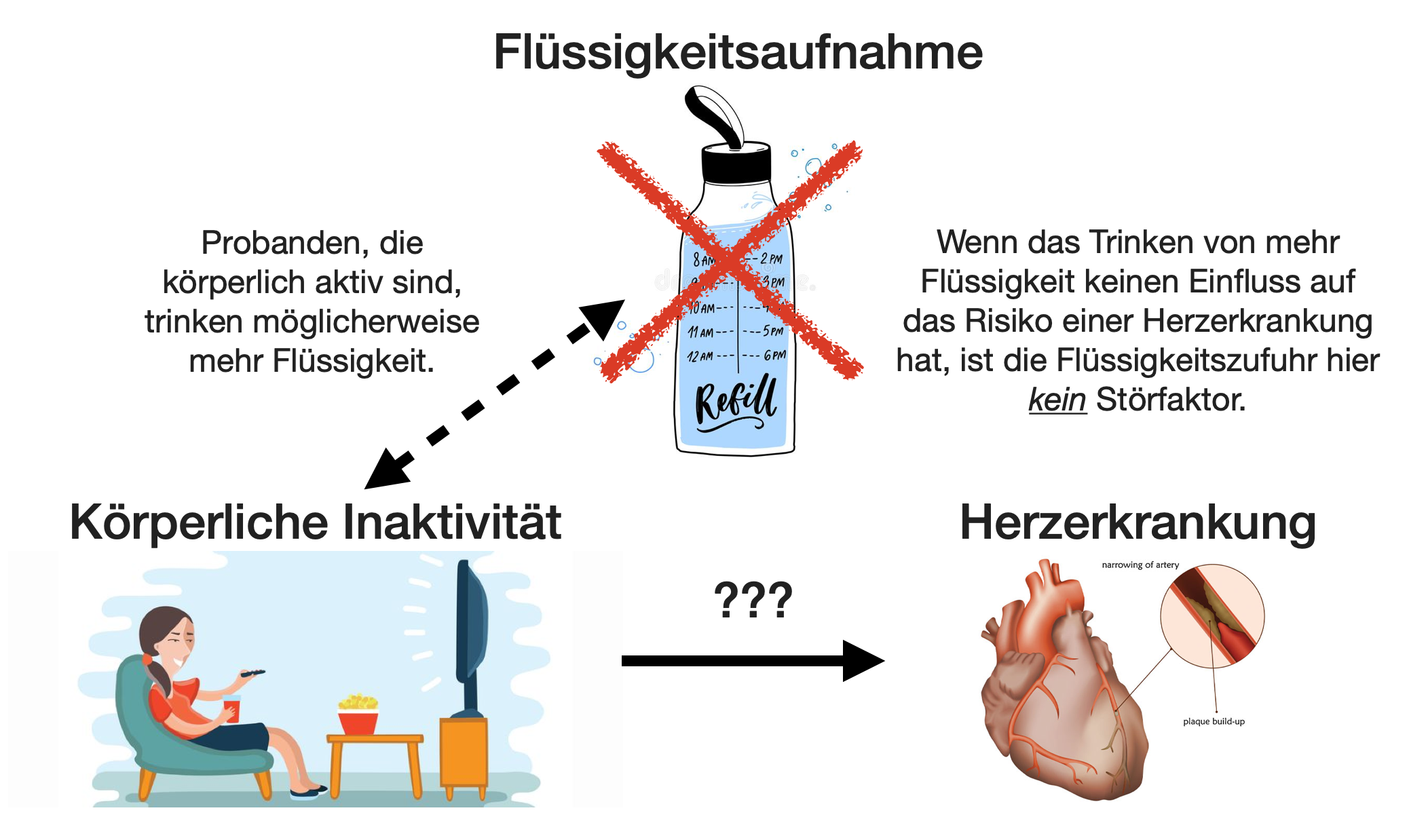
Pseudoeplikation
- Statistisch abhängige Replikate
- Oft durch zeitliche oder räumliche Abhängigkeiten (Zeitserien, geografische Daten)

Quelle: Hurlbert (1984) Pseudoreplication and the Design of Ecological Field Experiments
Planungsoptimierung - Accuracy und Precision
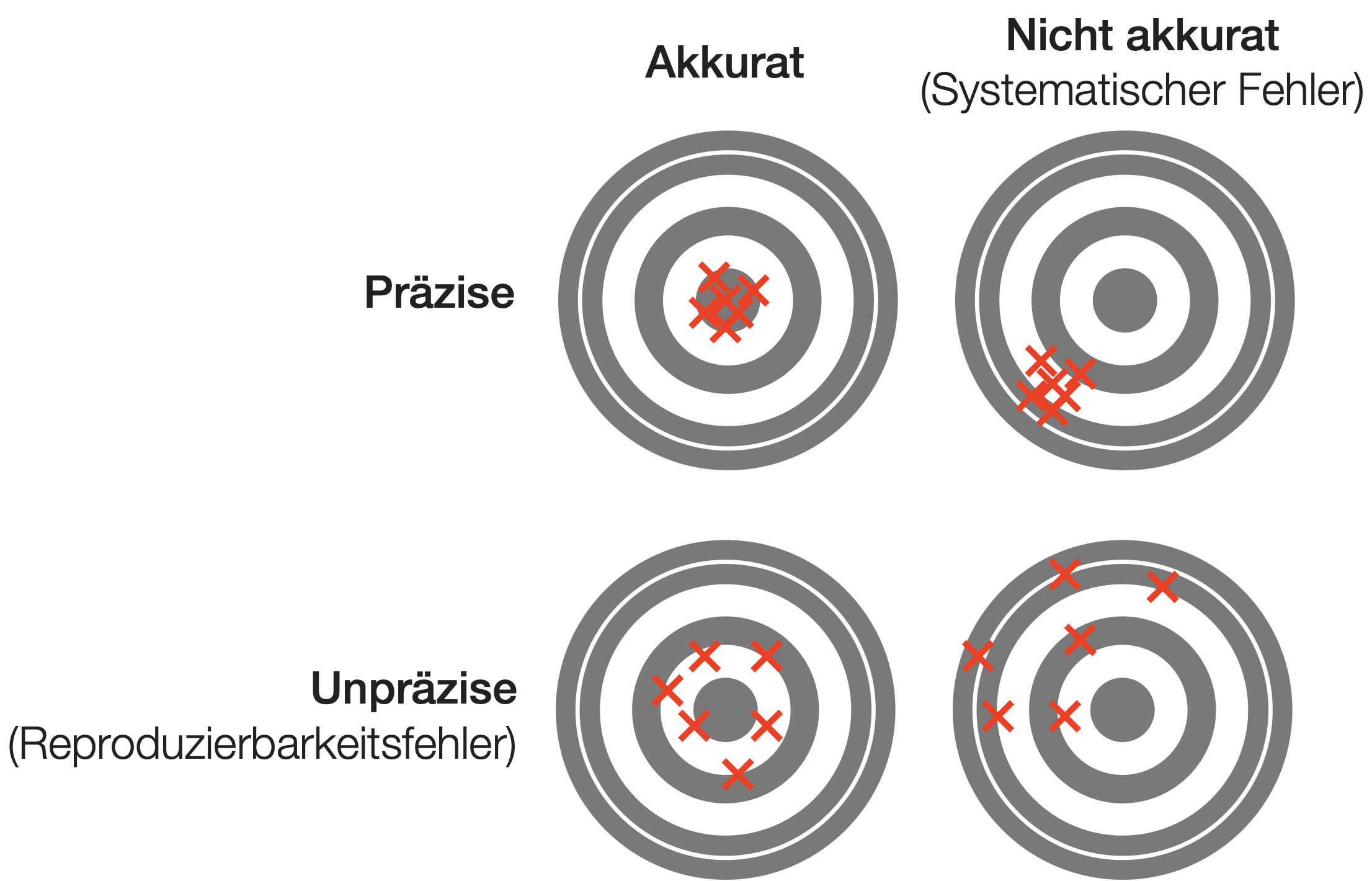
Accuracy (~Treffgenauigkeit) = Nähe einer Schätzung zum wahren Wert des zu schätzenden Parameters.
Precision (~Exaktheit) = Grad der Übereinstimmung zwischen wiederholten Schätzungen.
Poweranalyse und Berechnung des Stichprobenumfangs
Übliche Experimentfragen
Nachdem das Design des Experiments und die statistische Analyse bestimmt wurden, ergeben sich oft folgende 3 Fragen:
![]()
- Welcher Stichprobenumfang ist nötig?
- Wie hoch ist die Power oder Teststärke des Experiments?
- Was ist der kleinste Effekt, der mit dem Experiment nachgewiesen werden kann?
Berechnung der Effektgrößen Cohen (1992)
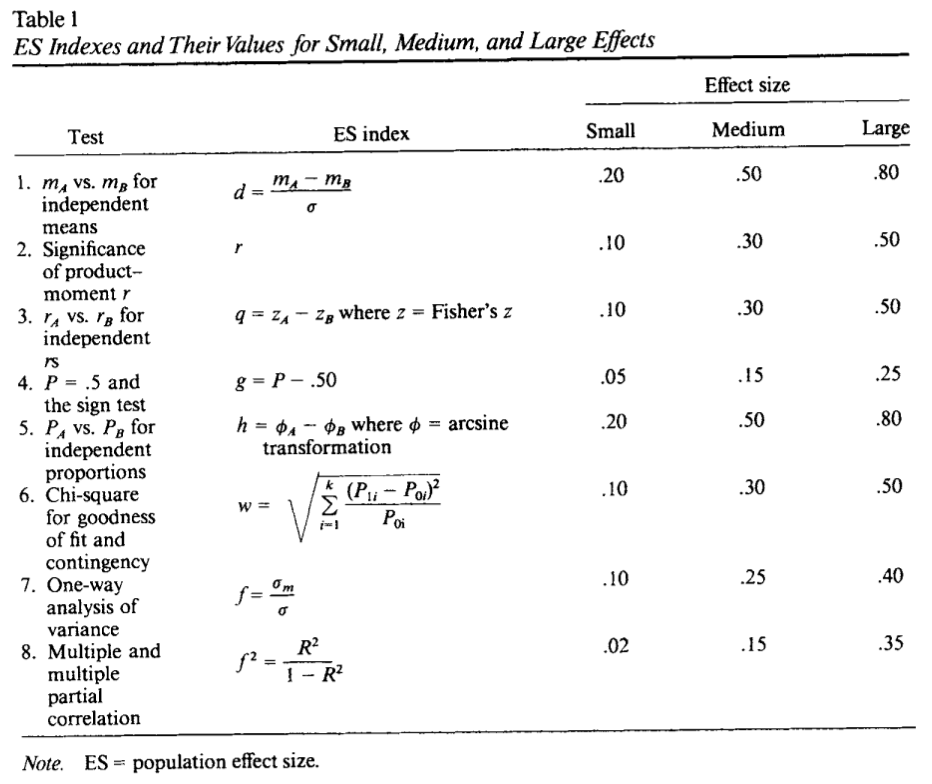
Cohen, J. (1992): A Power Primer, Psychological Bulletin 112(1): 155-159
t-Test | Beispiel Zugverhalten
Wie groß muss die Stichprobe sein, damit der von uns beobachtete Unterschied von 1200 km statistisch nachweisbar ist?
| Kenngröße | Buchfink | Mönchsgrasmücke |
|---|---|---|
| Mittelwert x̅ | 1800 km | 3000 km |
| Standardabweichung s | ±900 km | ±1000 km |
| Stichprobengröße n | 20 | 30 |


Bildquellen: Wikipedia (Buchfink unter (CC BY-SA 2.5 Lizenz) und Mönchsgrasmücke unter CC0 Lizenz)
t-Test | Berechnung von n
Wie groß muss die Stichprobe sein, damit der von uns beobachtete Unterschied von 1200 km statistisch nachweisbar ist?
- → Es braucht mindestens 10 Replikate pro Gruppe.
t-Test | Berechnung von n
Und wie groß müsste die Stichprobe sein, wenn wir bereits einen Unterschied von 600 km bzw. 300 km statistisch nachweisen wollen?
t-Test | Poweranalyse
Im vorliegenden Experiment betrug der Stichprobenumfang 20 und 30. Wie hoch wäre die Teststärke bei 20 oder bei 5 Vogelmessungen (in beiden Gruppen) gewesen, um einen Unterschied von 1200 km statistisch nachweisen zu können?
t-Test | Berechnung des minimal
nachweisbaren Effektes
Angenommen es soll die Untersuchung des Zugverhaltens wiederholt werden, es können aber nur 8 Vögel jeweils untersucht werden. Welche Differenz könnte dann überhaupt statistisch nachgewiesen werden?
→ Die Differenz müsste mindestens 1433.3 km betragen, um überhaupt einen signifikanten Unterschied zwischen den beiden Arten nachweisen zu können.
t-Test | Sog. ‘Power Curves’ 1
![]()
Anstatt immer nur einzelne Szenarios durchzuspielen, ist es hilfreich, die Teststärke für mehrere Kombinationen an Parametern als Kurve zu visualisieren:
[1] 144 4 n sd delta power
1 5 500 500 0.28593
2 7 500 500 0.40570
3 9 500 500 0.51333
4 11 500 500 0.60708
5 13 500 500 0.68671
6 15 500 500 0.75292t-Test | Sog. ‘Power Curves’ 2
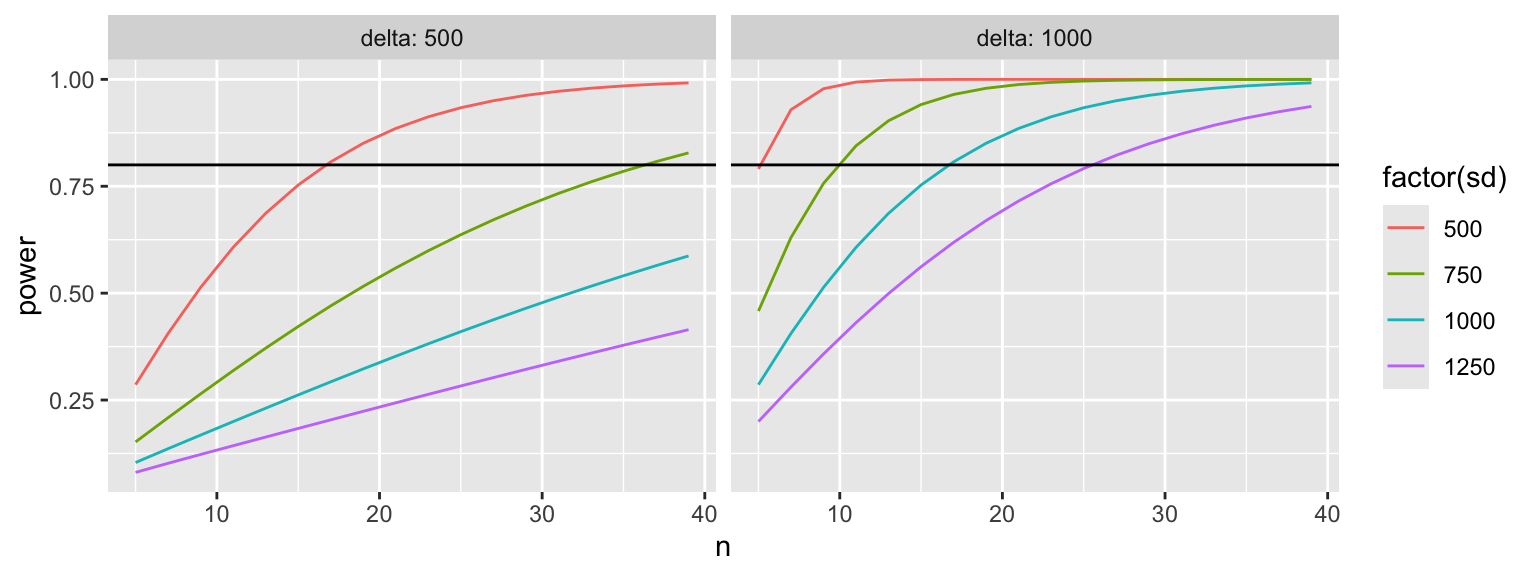
- Bei hoher Effektgröße und geringer Variabilität wird die nicht-lineare Beziehung zwischen der Stichprobengröße und der Power sichtbar.
- → Kleine Erhöhungen des Stichprobenumfangs führen hier bereits zu großen Erhöhungen der Teststärke.
- Die Kurve macht schnell deutlich, dass ein n von 40 nicht ausreicht um eine Power von 0.8 zu erzielen, wenn die Standardabweichung >750 ist und die Differenz bei nur 500 km liegt.
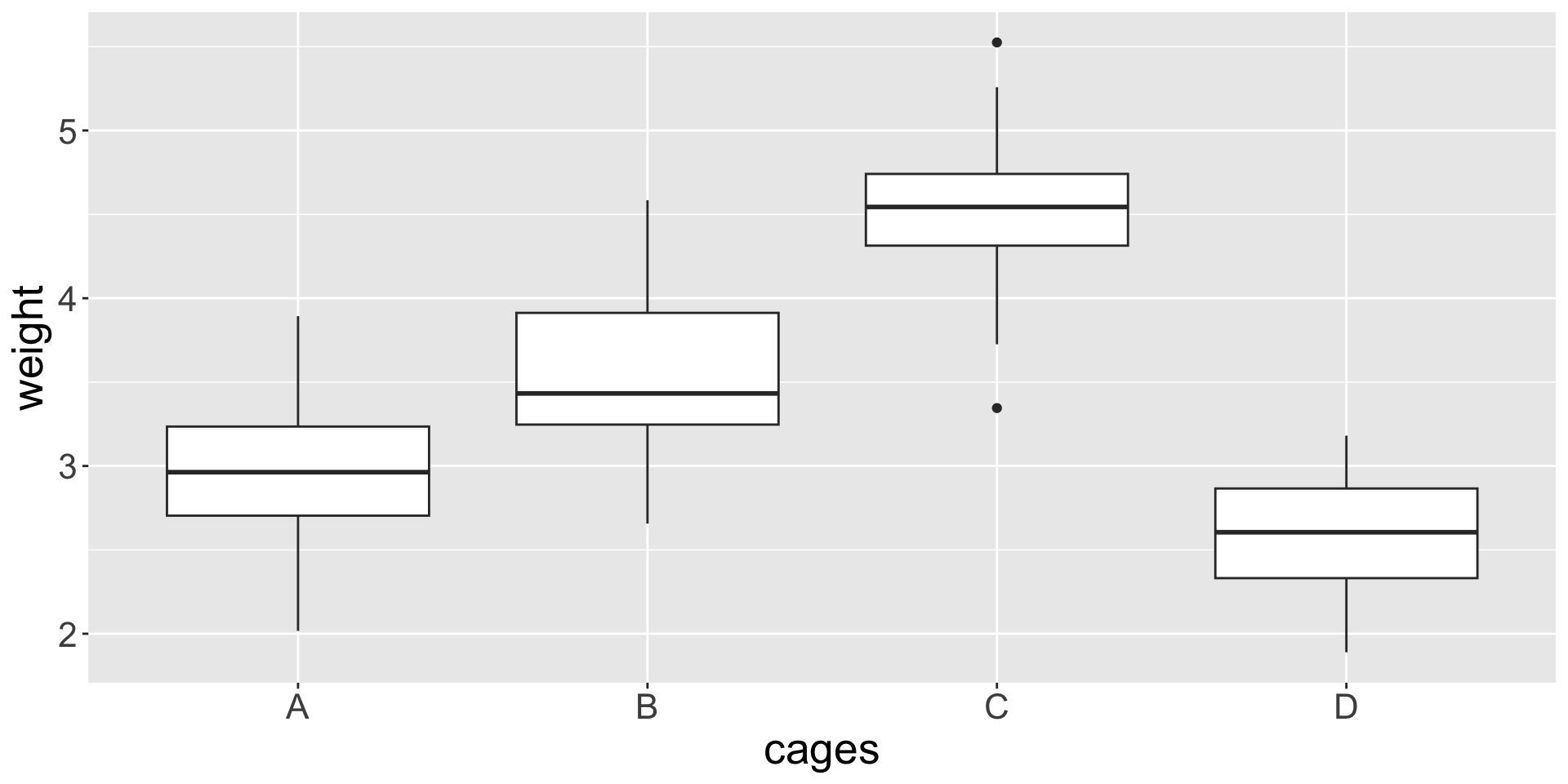
ANOVA | Berechnung von n - Lachs-Beispiel
![]()
Gewichtsunterschiede von Atlantischem Lachs, der in 4 verschiedenen Typen von Netzkäfigen gezüchtet wurde (n = 24).
,_male.jpg){kind=link}
{kind=link}
G*Power
Nützliche Open Source Software für Windows und Mac
G*Power | ANOVA-Demonstration
![]()
Literaturempfehlungen
![]()
Bücher
- Lazic, S.E. (2016) Experimental Design for Laboratory Biologists, Cambridge University Press
- Quinn, G.P. & Keough, M.J. (2002): Experimental Design and Data Analysis for Biologists, Cambridge, UK, 553 S.
- Cohen, J. (1988): Statistical Power Analysis for the Behavioral Sciences (2nd Ed.). Hillsdale, NJ: Lawrence Erlbaum Associates, Publishers, 567 S.
Artikel
- Underwood, A.J. (2009): Components of design in ecological field experiments, Annales Zoologici Fennici, 46(2): 93-111
- Hurbert, S.H. (1984): Pseudoreplication and the design of ecological field experiments, Ecological Monographs 54(2): 187-211
- Dutilleul, P. (1993): Spatial Heterogeneity and the Design of Ecological Field Experiments, Ecology 74(6): 1646-1658
- Krzywinski, M., Altman, N. & Blainey, P. (2014): Nested designs, Nature Methods 11: 977–978
- Altman, N. & Krzywinski, M. (2015): Split-plot design, Nature Methods 12: 165–166
- Stallings, W.M. & Gillmore, G.M. (1971): A Note on ‘Accuracy’ and ‘Precision’, Journal of Educational Measurement 8(2): 127-129
- Cohen, J. (1992): A Power Primer, Psychological Bulletin 112(1): 155-159
- Faul, F., Erdfelder, E., Lang, A.-G., & Buchner, A. (2007): G*Power 3: A flexible statistical power analysis program for the social, behavioral, and biomedical sciences. Behavior Research Methods 39: 175-191.
Übungsaufgaben
![]()
Vorbereitungsaufgabe für Übungstag 6

Was ist zu tun?
Wiederholung zentraler Konzepte des experimentellen Designs und der Poweranalyse
Wichtig
Moodle-Quiz VOR der nächsten Übung ausfüllen!
Abschlussquiz
![]()
Bei weiteren Fragen: saskia.otto(at)uni-hamburg.de

Diese Arbeit is lizenziert unter einer Creative Commons Attribution-ShareAlike 4.0 International License mit Ausnahme der entliehenen und mit Quellenangabe versehenen Abbildungen.