9-Korrelation & Transformation
Data Science 2
Universität Hamburg, IMF & IZS
Sommersemester 2026
Lernziele
![]()
Am Ende dieser VL- und Übungseinheit werden Sie
- den Zusammenhang zwischen Kovarianz und Korrelation kennen.
- den parametrischen Pearson-Produkt-Moment-Korrelationskoeffizienten und die beiden nicht-parametrischen Spearman Rangkorrelationskoeffizient und Kendall’s Tau in R berechnen können.
- wissen, welcher dieser Koeffizienten bei Ihren Daten der passende ist.
- die R Funktion zum Testen der Nullhypothese \rho = 0 anwenden können.
- viele Korrelationen zusammen visualisieren können.
- die Powertransformation und die Box-Cox-Transformation kennen.
- wissen, wie Sie die richtige Transformation zur Datennormalisierung, Varianzhomogenisierung und Linearisierung auswählen.
Auf Zusammenhänge testen
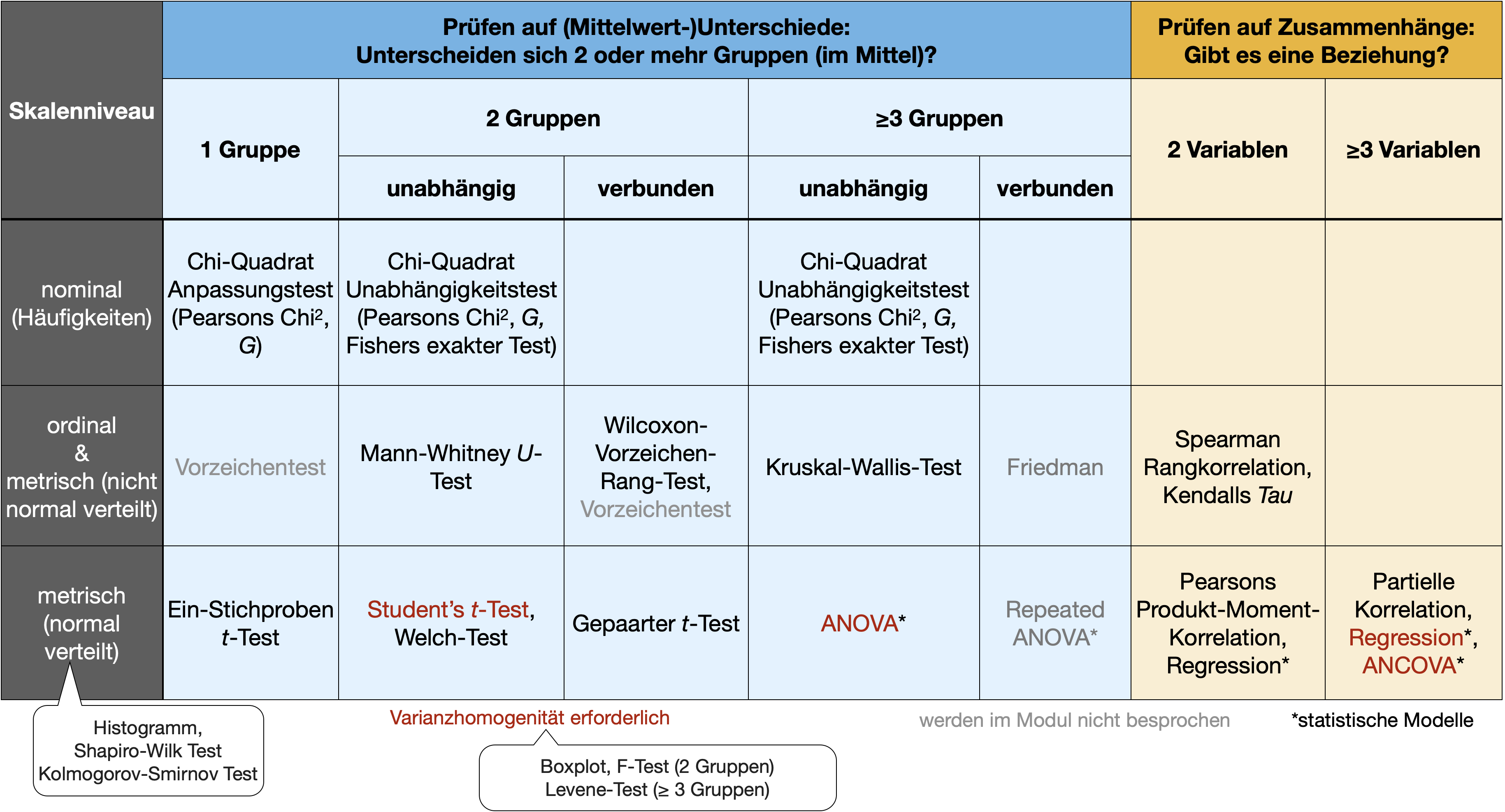


Charakterisierung bivariater Beziehungen
- Form (linear, monoton, nicht-linear, quadratisch)
- Richtung (positiv, negativ)
- Stärke (wie viel Streuung/Rauschen?)
- Ausreißer
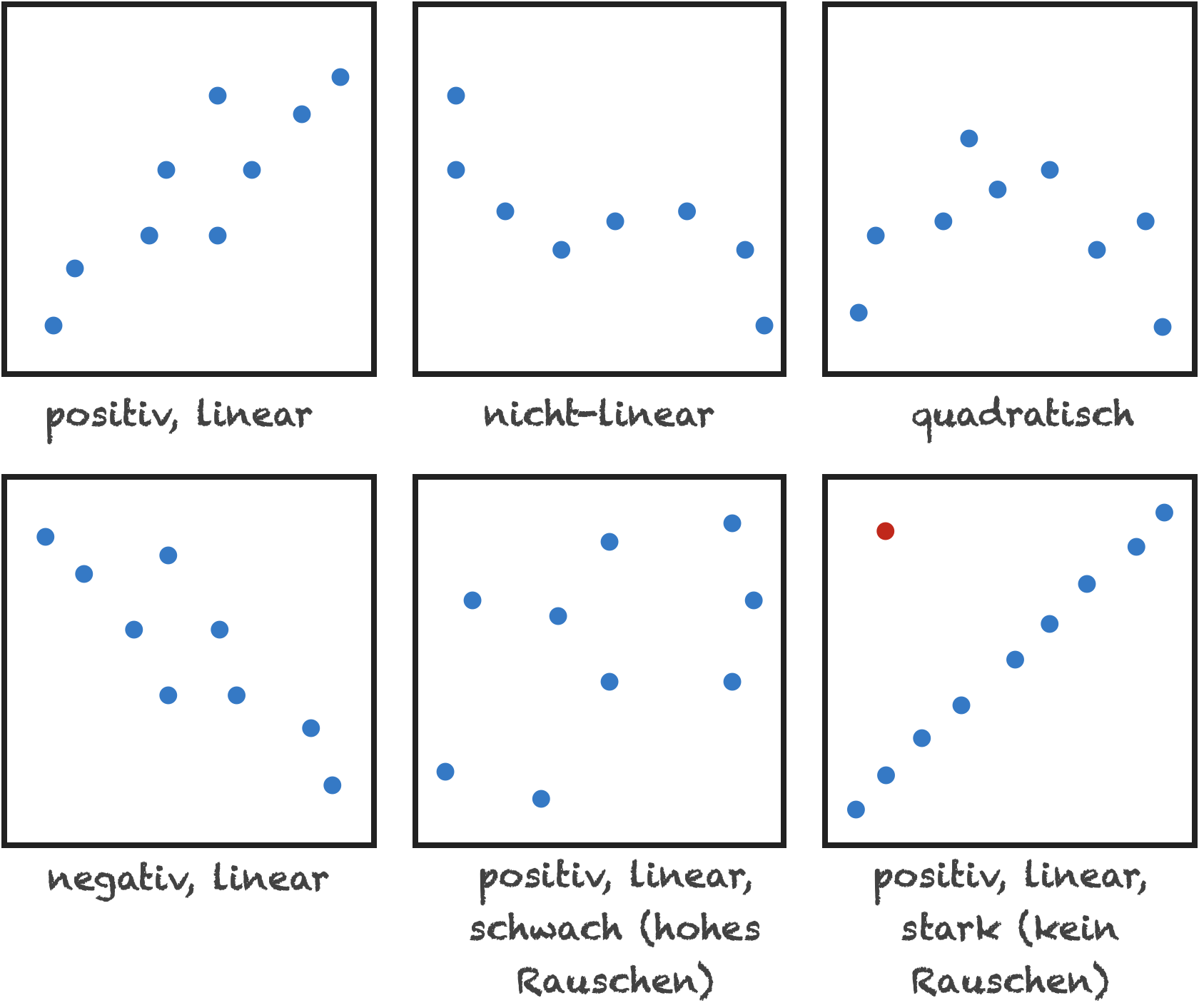
Die Form | Streudiagramm der Rohdaten
Hier ein Beispiel des möglichen Zusammenhangs zwischen dem Körpergewicht (in kg) und der Gehirnmasse (in g) von Säugetieren (Datensatz mammals aus dem Paket ‘MASS’).
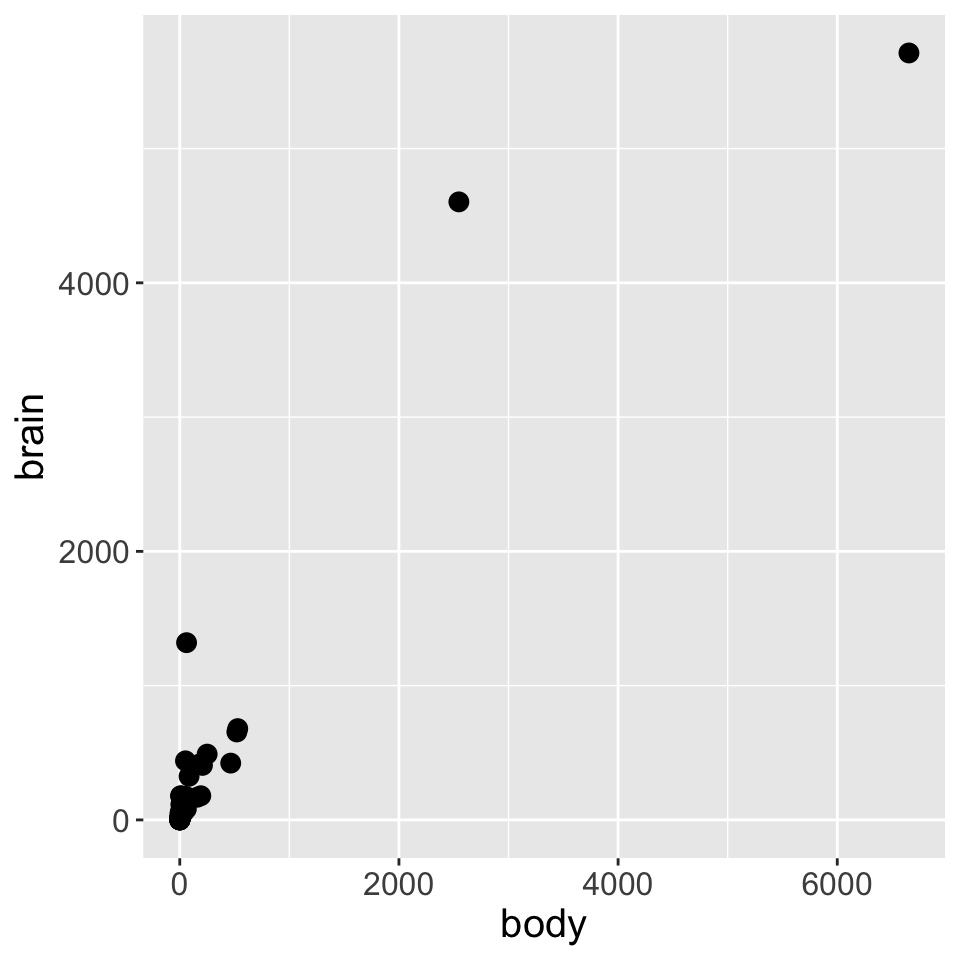
Die Form | Streudiagramm mit scale_...
Hier ein Beispiel des möglichen Zusammenhangs zwischen dem Körpergewicht (in kg) und der Gehirnmasse (in g) von Säugetieren (Datensatz mammals aus dem Paket ‘MASS’).
Die Form | Streudiagramm mit coord_trans()
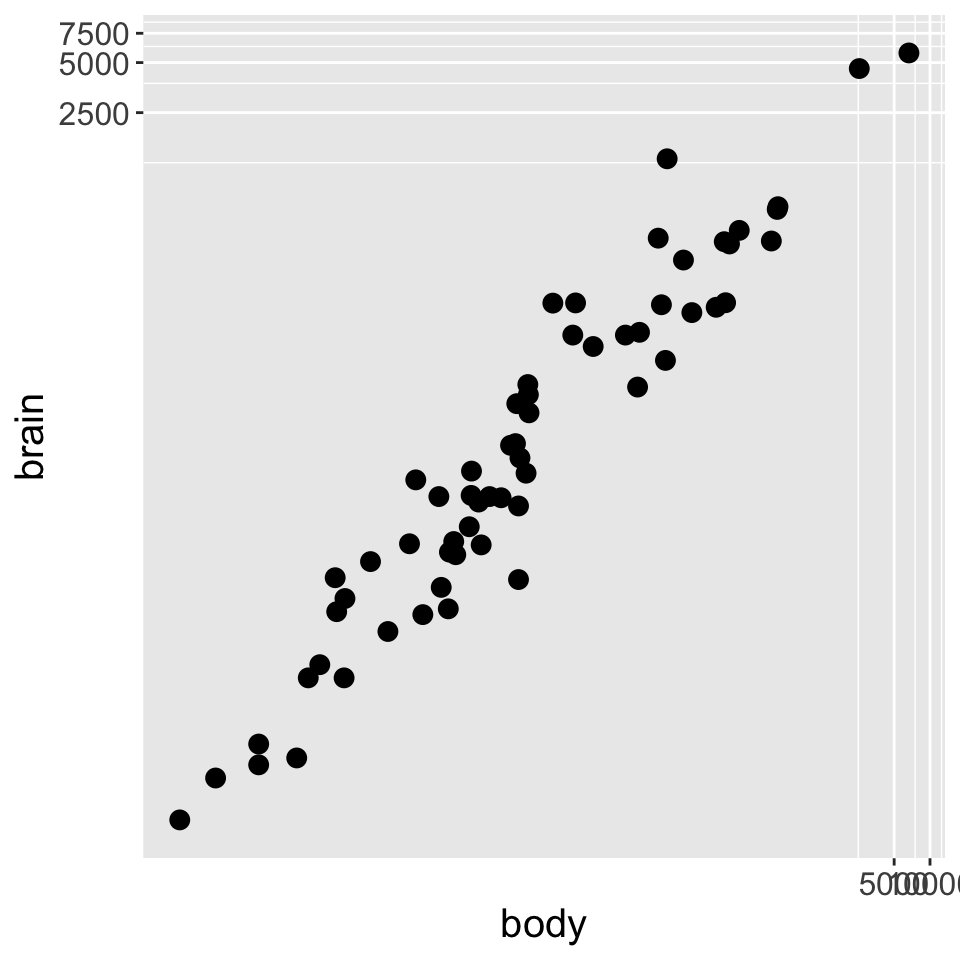
Hier ein Beispiel des möglichen Zusammenhangs zwischen dem Körpergewicht (in kg) und der Gehirnmasse (in g) von Säugetieren (Datensatz mammals aus dem Paket ‘MASS’).
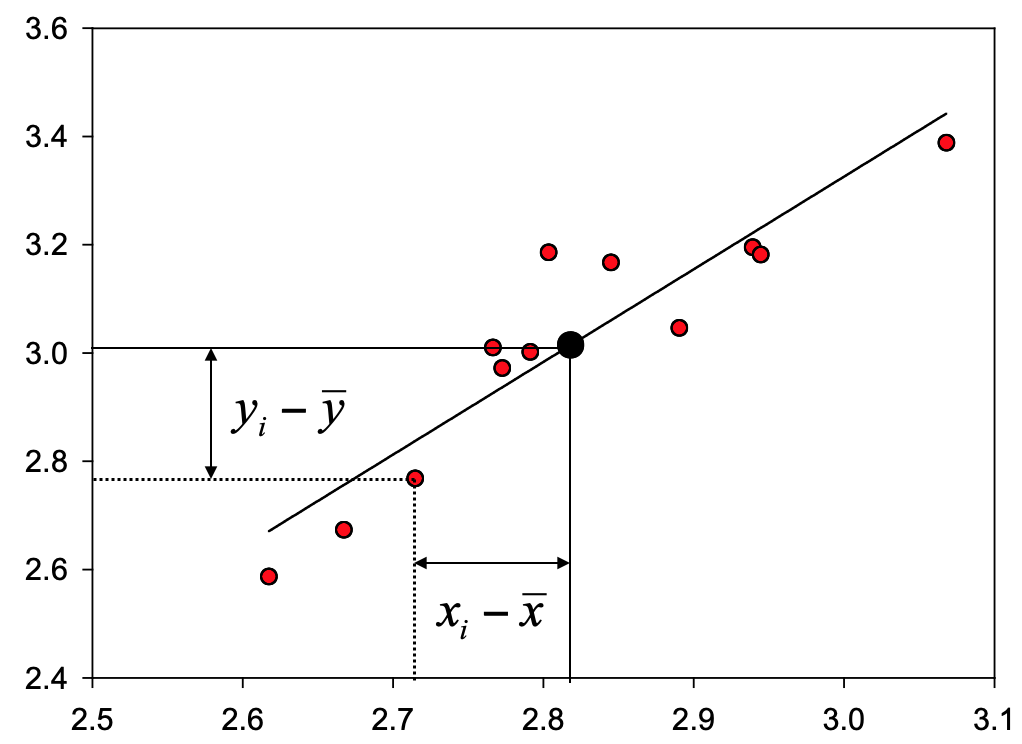
Kovarianz | Grafisch
Korrelationstests in R
![]()
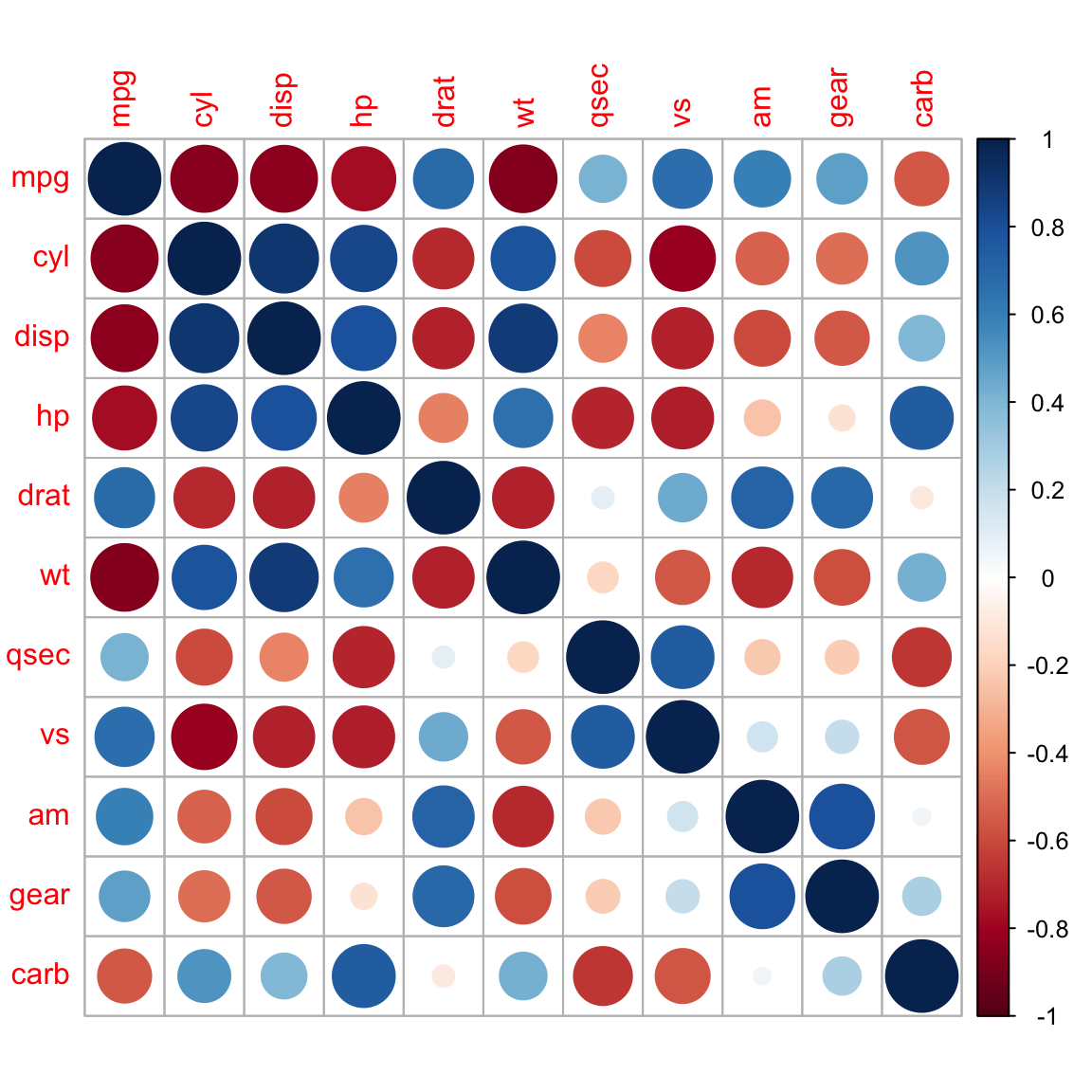
Viele Beziehungen visualisieren | 2
Transformation

Wann transformieren?
![]()
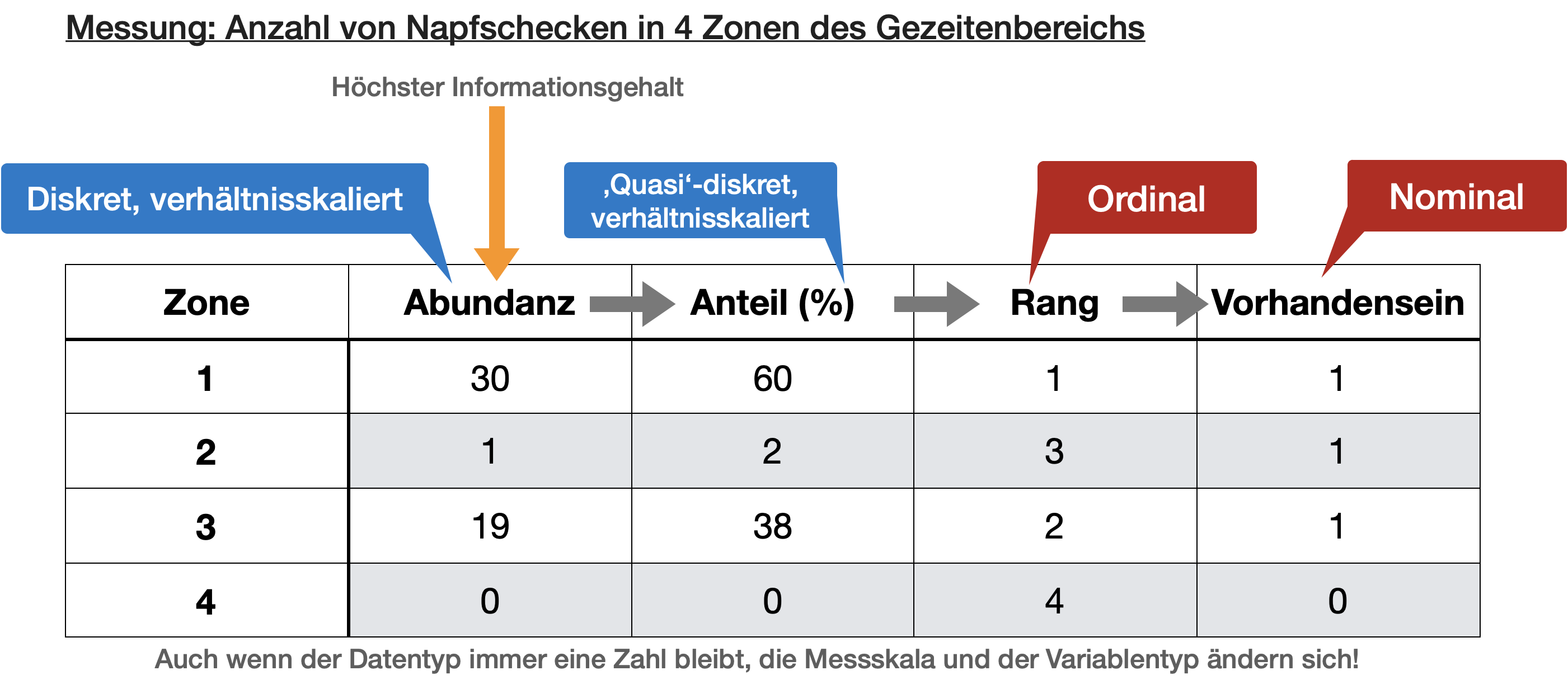
Aus DS1: Umwandlung des Skalenniveaus
Das Skalenniveau lässt sich umwandeln, allerdings kann dies immer mit einem Informationsverlust einhergehen.
Häufig angewandte Transformationen
![]()
Wurzeltransformation sqrt()
- Geeignet für Häufigkeitsdaten (‘count data’).
- Quadratwurzel → wenn Varianz = Mittelwert oder Daten Poisson-verteilt sind.
- Vierte Wurzel → wenn die Varianz > Mittelwert entspricht oder Daten negativ binomial-verteilt sind.
Logarithmus log()
- Geeignet wenn Varianzen >> Mittelwert.
- Wenn der Datensatz Nullen enthält wird zu jeder Beobachtung eine Konstante addiert.
Powertransformation | Vergleich versch. \lambda
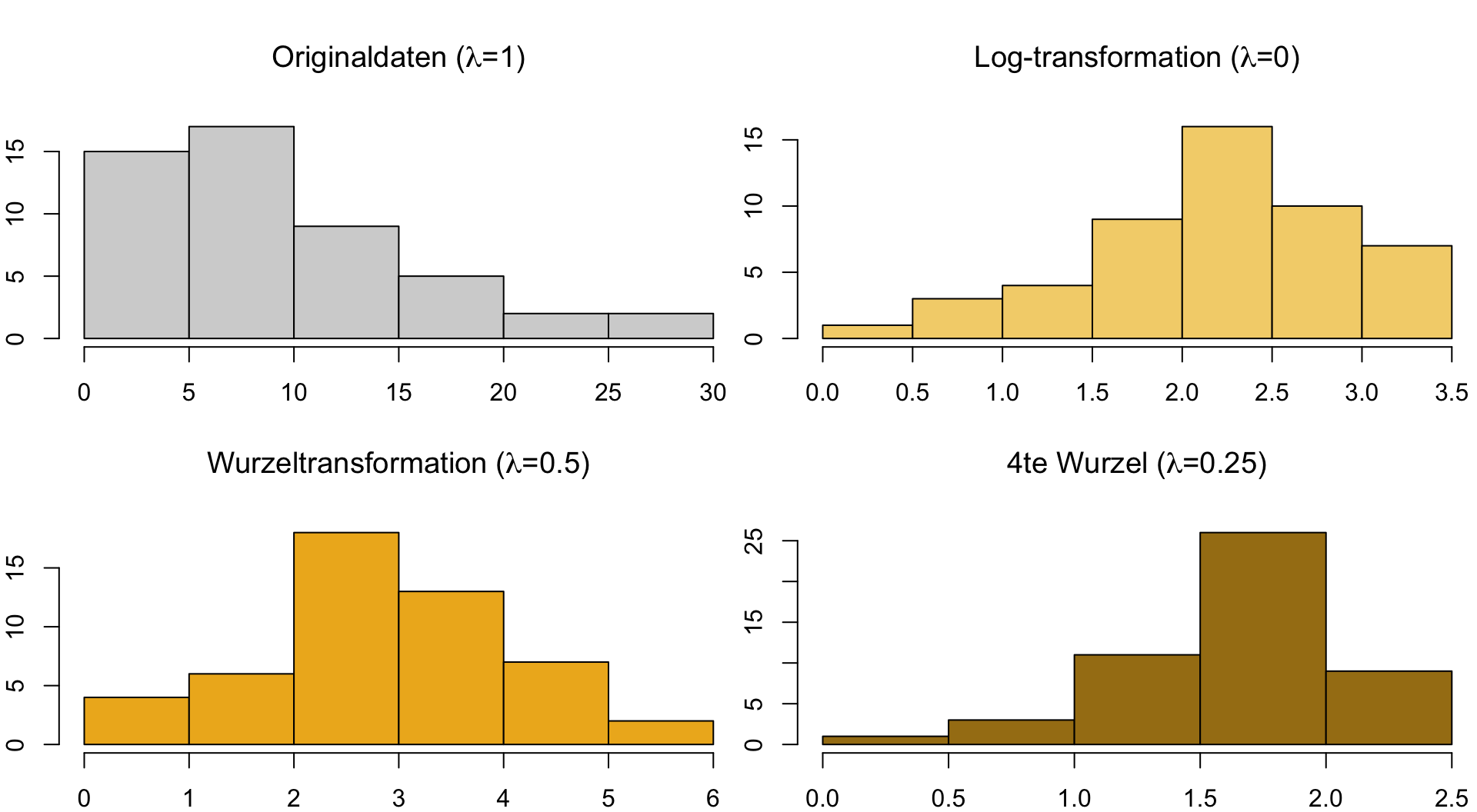
Vergleich Power- vs. Box-Cox-Transformation
\lambda = 0.5
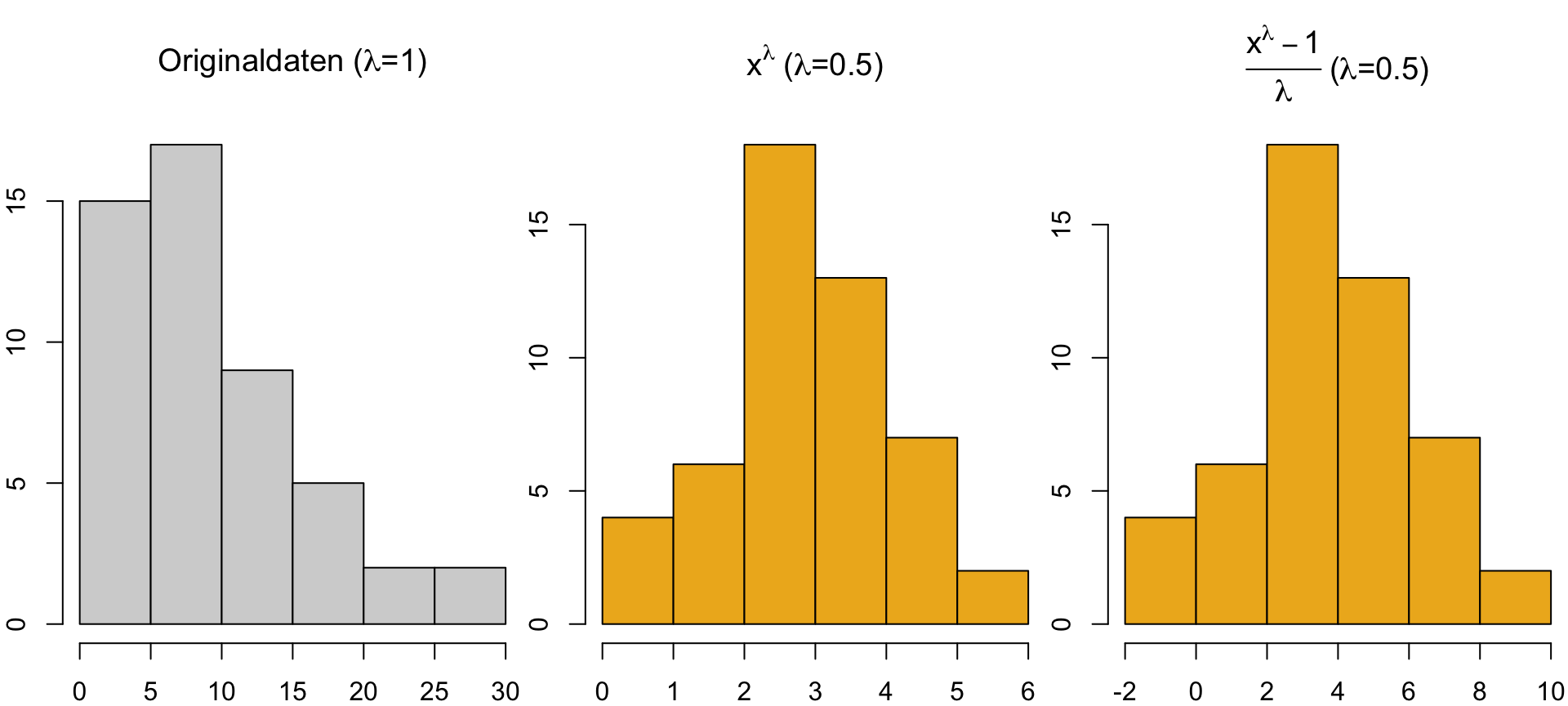
Aus DS1: Linearisierung durch Transformation
Allgemeines Schema
Bildquelle: Zuur et al., 2007 (Kap. 4)
Aus DS1: Anwendung der ‘bulging’ Regel
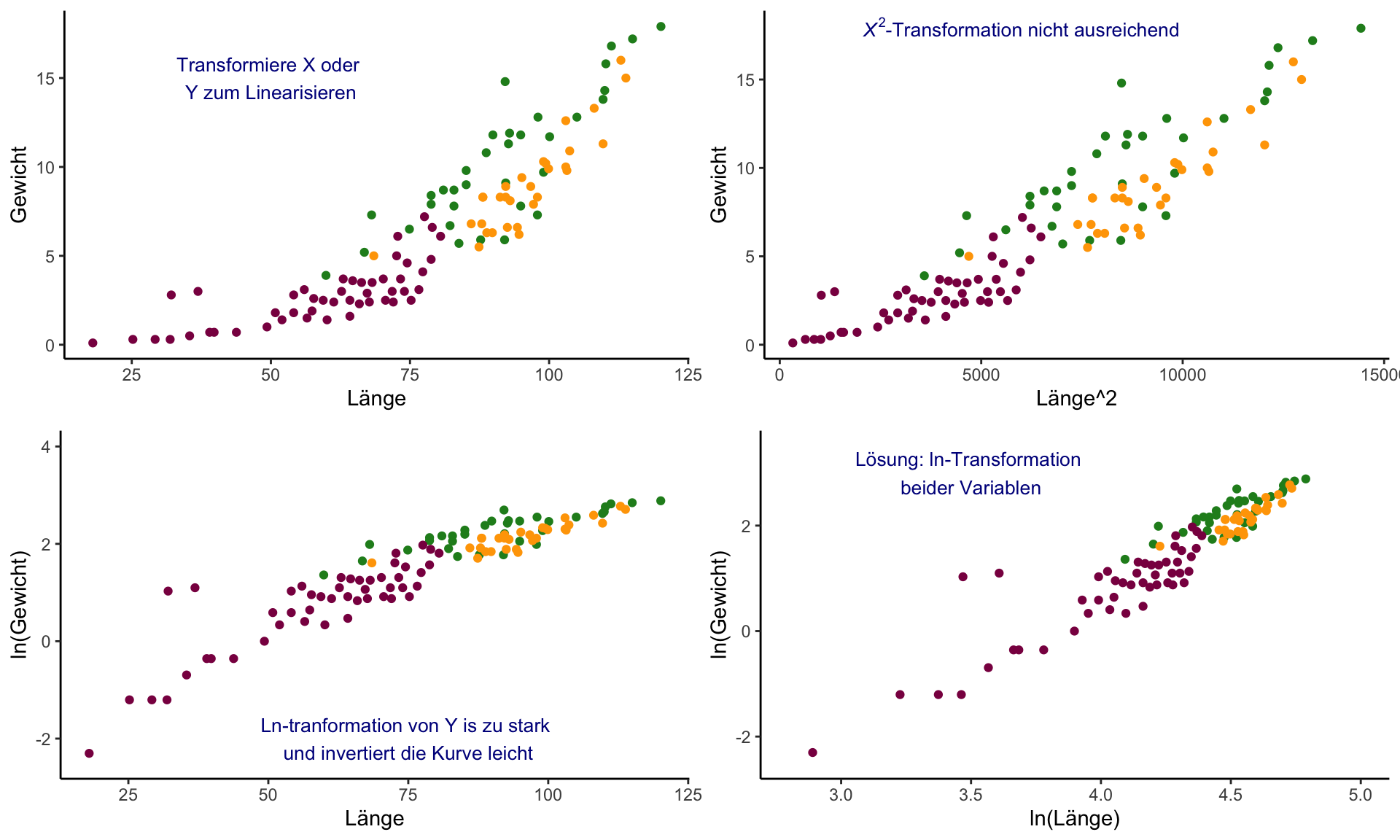
Your turn …
![]()
Quiz | Shiny App 1
Welches Lambda zur Datennormalisierung?
![]()
Link zur Shiny-App: teaching-stats/transformations/normality/
Quiz | Shiny App 2
Welches Lambda zum Angleichen von Varianzen?
![]()
Link zur Shiny-App: teaching-stats/transformations/variance-homogeneity/
Quiz | Shiny App 3
Welches Lambda zur Linearisierung?
![]()
Link zur Shiny-App: teaching-stats/transformations/linearity/
Übungsaufgaben
![]()
Vorbereitungsaufgabe für Übungstag 5

Was ist zu tun?
Eigene Simulationen zu Powertransformationen mithilfe von Shiny Apps durchführen:
Wichtig
Moodle-Quiz VOR der nächsten Übung ausfüllen!
Abschlussquiz
![]()
Bei weiteren Fragen: saskia.otto(at)uni-hamburg.de

Diese Arbeit is lizenziert unter einer Creative Commons Attribution-ShareAlike 4.0 International License mit Ausnahme der entliehenen und mit Quellenangabe versehenen Abbildungen.