6-Klassische Tests zum Prüfen auf Unterschiede: metrische/ordinale Daten
Data Science 2
Universität Hamburg, IMF & IZS
Sommersemester 2026
Lernziele
![]()
Am Ende dieser VL- und Übungseinheit werden Sie
- auf Unterschiede zwischen zwei Mittelwerten für unabhängige UND gepaarte Stichproben testen können.
- wissen, wann sie den parametrische t-Test verwenden können und wann besser den nicht-parametrischen Mann-Whitney U-Test bzw. Wilcoxon-Vorzeichen-Rang-Test.
Heutige Fragen
Unterscheidet sich das durchschnittliche Zugverhalten zwischen Buchfinken und Mönchsgrasmücken?



Singen Kohlmeisen in der Stadt durchschnittlich lauter als auf dem Land?
Bildquellen rechts oben: Wikipedia (Buchfink unter (CC BY-SA 2.5 Lizenz) und Mönchsgrasmücke unter CC0 Lizenz)
Bildquelle links unten: Luc Viator-Wikimedia (CC-BY-SA 2.0 Lizenz)
t-Test: Parametrischer Ein- und Zweistichprobentest

Mittelwertvergleich bei metrischen Daten

t-Test in R
![]()
Built-in Funktion t.test()
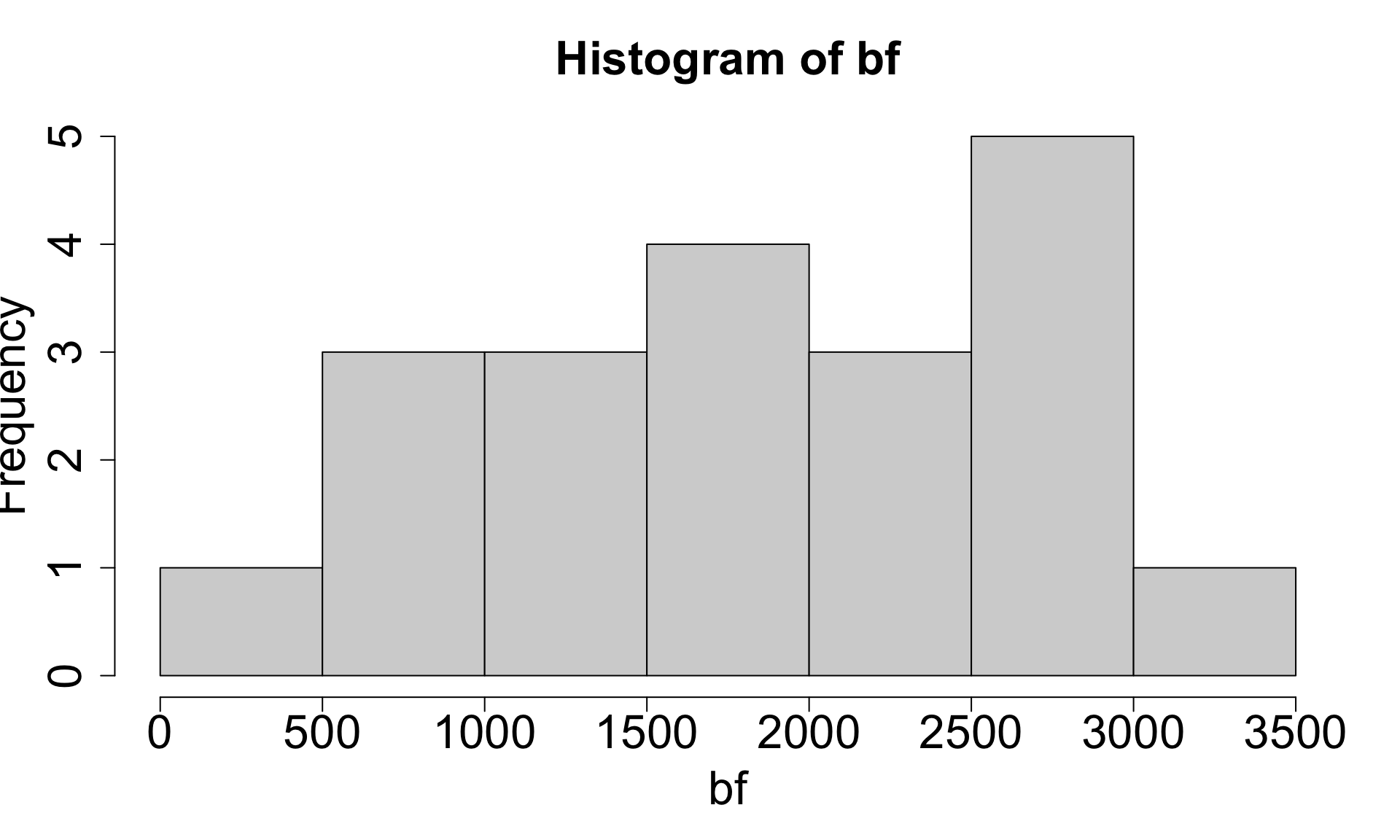
t-Test für 1 Stichprobe | Bsp. Zugverhalten 1
Forschungsfrage
Unterscheidet sich unsere Stichprobe zum Zugverhalten des Buchfinks (BF1) von einer anderen Stichprobe (BF2), für die wir nur den Mittelwert kennen?
Bekannte Statistiken
| Kenngröße | BF1 | BF2 |
|---|---|---|
| Mittelwert \bar{X} | 1800 km | 1697 km |
| Standardabw. s | ±900 km | ? |
| Stichprobengröße n | 20 | ? |
Die 8 Schritte
| Kennwert: | \mu bzw. \bar{X} |
| H0: | BF1 = BF2 |
| HA: | BF1 \neq BF2 |
| Voraussetzung: | Normalverteilung |
| Teststatistik: | t |
| alpha: | 0.05 |
| FG: | n-1 = 19 |
| p-Wert: | Vergleich t-Wert mit t_{krit} aus einer t-Verteilung |
Bildquelle: Wikipedia (CC BY-SA 2.5 Lizenz)
t-Test für 1 Stichprobe | Bsp. Zugverhalten 2
t-Test für 1 Stichprobe | Bsp. Zugverhalten 3
Manuelle Berechnung
[1] 0.512[1] 2.09[1] 0.615t-Test für 1 Stichprobe | Bsp. Zugverhalten 4
- Die Teststatistik t liegt zwischen dem unteren und oberen t_{krit}, somit kann die H_0 nicht verworfen werden.
- Anders ausgedrückt:
- Die Wahrscheinlichkeit ein statistisches Ergebnis wie das beobachtete zu erhalten, wenn die Nullhypothese wahr wäre, liegt bei 61.5%.
- Somit können wir die H_0 nicht ablehnen (erst bei <5%).
ZUSAMMENFASSUNG: → Es gibt keinen signifikanten Unterschied zwischen unserer Stichprobe und der Vergleichsstichprobe (t = 0.51, df = 19, p > 0.5).
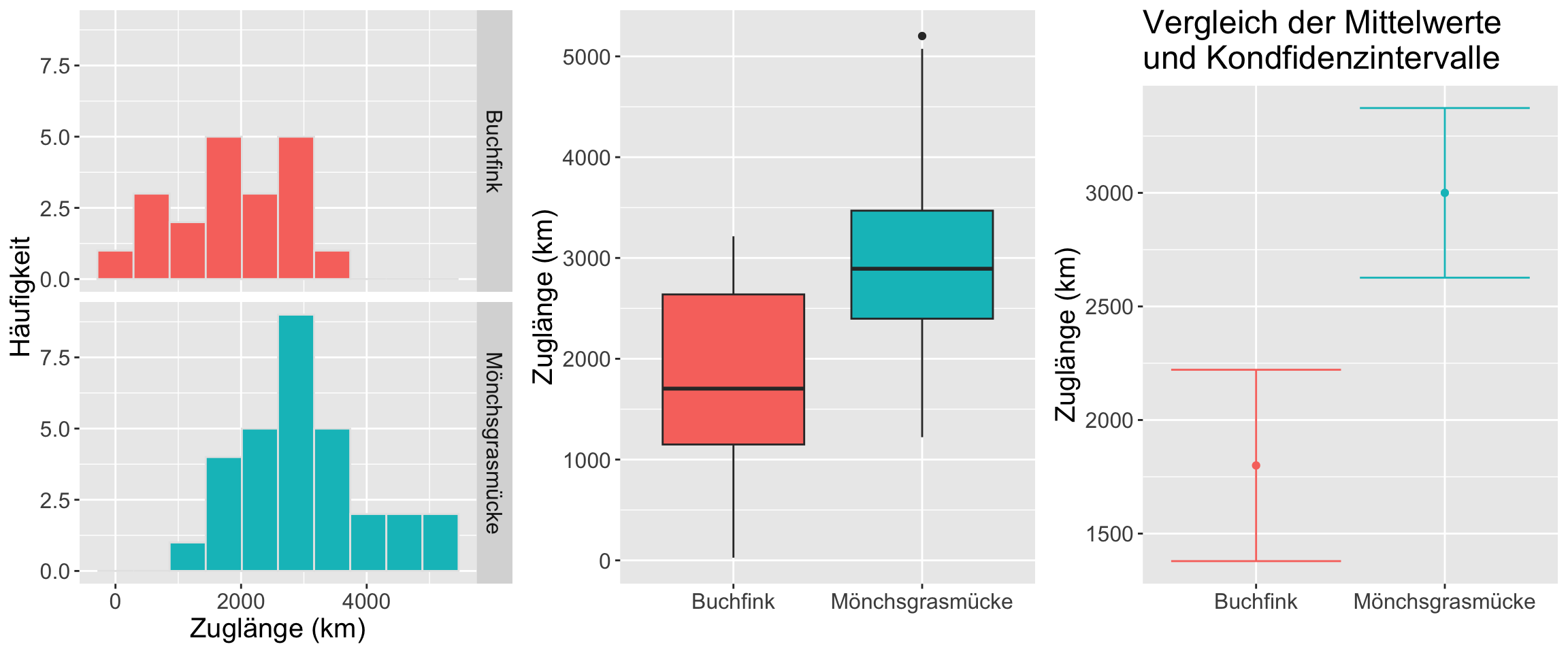
Bsp. Buchfinken vs. Mönchsgrasmücken | 1
Unterscheidet sich das durchschnittliche Zugverhalten zwischen Buchfinken und Mönchsgrasmücken?
| Kenngröße | Buchfink | Mönchsgrasmücke |
|---|---|---|
| Mittelwert x̅ | 1800 km | 3000 km |
| Standardabweichung s | ±900 km | ±1000 km |
| Stichprobengröße n | 20 | 30 |
Bildquellen: Wikipedia (Buchfink unter (CC BY-SA 2.5 Lizenz) und Mönchsgrasmücke unter CC0 Lizenz)
Bsp. Buchfinken vs. Mönchsgrasmücken | 2
Testen der Annahmen
Shapiro-Wilk normality test
data: bf
W = 1, p-value = 0.5
Shapiro-Wilk normality test
data: mgm
W = 1, p-value = 0.6→ Die H0 wird jeweils angenommen, da p > 0.05: beide Stichproben sind normal verteilt.
F test to compare two variances
data: bf and mgm
F = 0.8, num df = 19, denom df = 29, p-value = 0.6
alternative hypothesis: true ratio of variances is not equal to 1
95 percent confidence interval:
0.363 1.946
sample estimates:
ratio of variances
0.81 → Die H0 wird angenommen, da p > 0.05: die Varianzen beider Gruppen sind gleich.
Wenn Stichproben abhängig sind

Abb. links: Fotoaufnahmen des Lake Powell, USA, am Zusammenfluss mit dem Dirty Devil River (Quelle: https://pubs.usgs.gov/fs/2004/3062/)
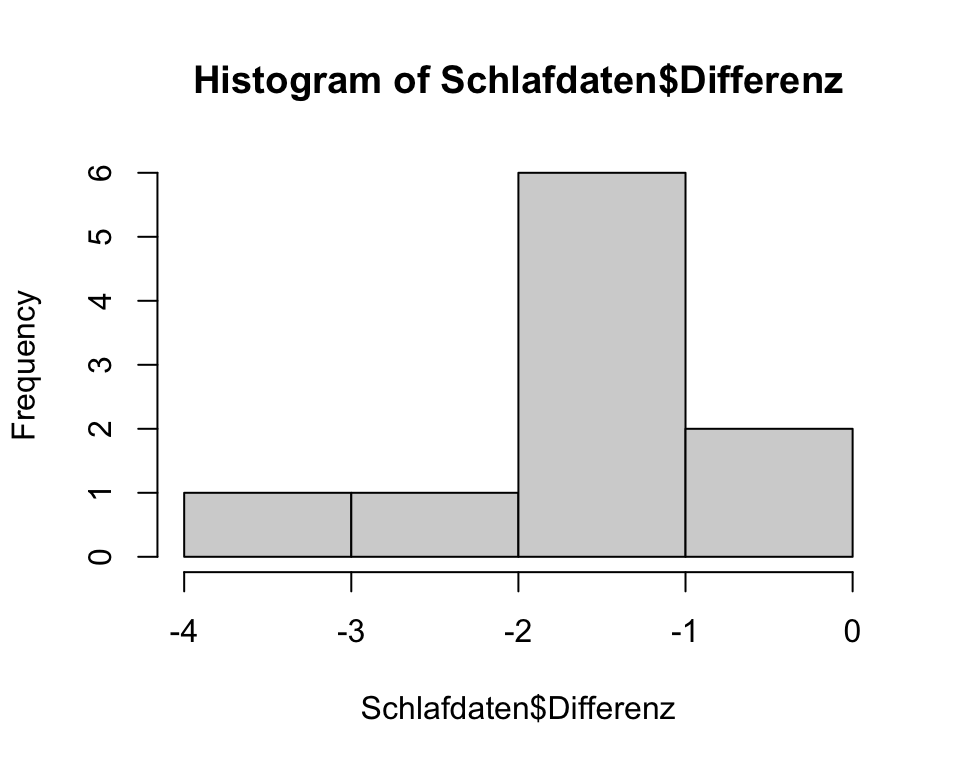
Bsp. Pharmazeutische Schlafstudie | 2
Prüfung auf Normalverteilung
- Da sich der gepaarte t-Test auf die paarweisen Differenzen bezieht, muss diese normal verteilt sein!
- Die Varianzhomogeniät zwischen den beiden Gruppen fällt entsprechend weg.
,_male.jpg){kind=link}
{kind=link}
{kind=link}
Übersicht der t-Test Anwendungen
![]()
- Einstichproben t-Test, zweiseitige Hypothese (Standard):
t.test(x, mu)
- Unabhängiger Zweistichproben-t-Test (gleiche Varianzen), zweiseitig: H_A:µ1 ≠ µ2
t.test(x, y, var.equal = TRUE)
- Unabhängiger Zweistichproben-t-Test (gleiche Varianzen), einseitig: H_A:µ1 > µ2:
t.test(x, y, var.equal = TRUE, alternative = “greater”)
- Welch-Test (ungleiche Varianzen = default), einseitig: H_A:µ1 < µ2
t.test(x, y, alternative = “less”)
- Gepaarter Zweistichproben-t-Test (gleiche Varianzen) , zweiseitige Hypothese:
t.test(x, y, paired = TRUE, var.equal = TRUE)
- Gepaarter t-Test mit 2 Stichproben (ungleiche Varianzen) , einseitig: H_A:µ1 > µ2
t.test(x, y, paired = TRUE, alternative = “greater”)
Übersicht der Hypothesen bei den t-Tests

Your turn …
![]()
Quiz 1 | Testwahl
Kelchblattlänge in iris
![]()
Ausgangssituation:
- Es soll die Hypothese getestet werden, dass die durchschnittliche Kelchblattlänge der Art Iris setosa kleiner ist als bei der Art Iris virginica.
- Beide Stichproben sind normal verteilt (jeweils W = 0.97, p > 0.05).
- Die Varianzen beider Stichproben sind signifikant unterschiedlich (F_{(49,49)}=3.25, p < 0.001).
Quiz 2 | Funktionsaufruf
Kelchblattlänge in iris
![]()
Quiz 3 | Interpretation
Kelchblattlänge in iris
![]()
Nicht-Parametrische Tests - Teil 1
Vergleich zweier Stichproben mit ordinalen und metrischen (nicht normal verteilten) Daten

Mann-Whitney U | Kohlmeisen Beispiel
Studie

…Great tits in cities sing faster and at a higher pitch compared to their conspecifics dwelling in forests, as reported in this issue by Slabbekoorn and den Boer-Visser [6]. They suggest that the birds changed their songs to make them stand out against the masking traffic noise in urban areas. ..
Bildquelle männliche Kohlmeise: Luc Viator-Wikimedia (CC-BY-SA 2.0 Lizenz)
Die Wilcoxon-Verteilung
Bestimmung von U_{krit} (bei 2-seitiger Hyopothese)
![]()
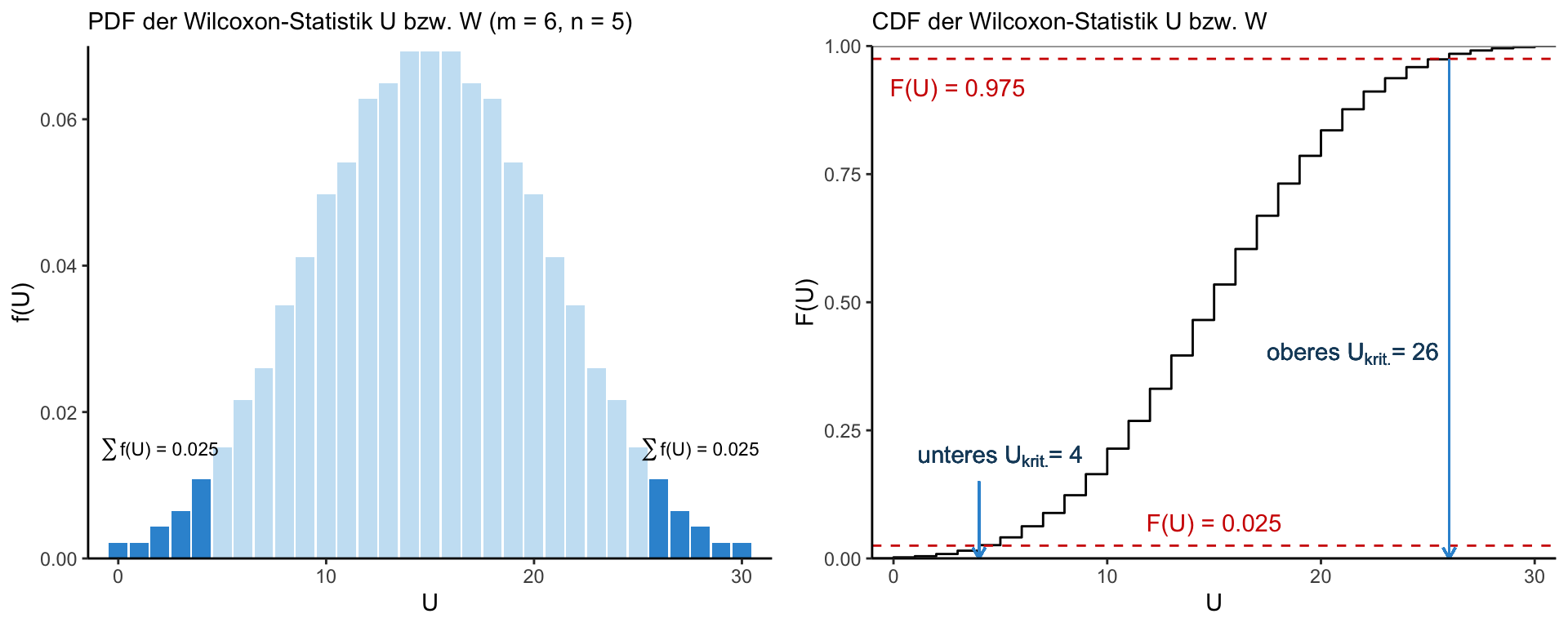
- Rangsumme der Ränge in einer Stichprobe = Zufallsvariable aus der kombinierten Rangverteilung
- Diese Rangverteilung wird Wilcoxon-Verteilung genannt und ist eine diskrete Verteilung → U_{krit} = (m, n, \alpha)
- Für große Stichproben (nicht mehr in den U-Tabellen abgebildet) wird allerdings ein Z-Wert ausgerechnet.
- Die Irrtumswahrscheinlichkeit für diesen Z-Wert kann in der Z-Tabelle nachgeschlagen bzw. in R mit
pnorm()ermittelt werden.
Übersicht der Funktionsanwendungen
![]()
- Unabhängiger Zweistichproben-Test: Mann-Whitney U-Test, zweiseitige Hypothese (Standard): H_A: µ1 ≠ µ2
wilcox.test(x, y)
- Unabhängiger Zweistichproben-Test: Mann-Whitney U-Test, einseitig: H_A: µ1 > µ2:
wilcox.test(x, y, alternative = “greater”)
- Gepaarter Zweistichproben-Test: Wilcoxon-Vorzeichen-Rang-Test, zweiseitige Hypothese: H_A: µ1 ≠ µ2
wilcox.test(x, y, paired = TRUE)
- Gepaarter Zweistichproben-Test: Wilcoxon-Vorzeichen-Rang-Test, einseitig: H_A: µ1 < µ2
wilcox.test(x, y, paired = TRUE, alternative = “less”)
Vergleich Mann-Whitney U-Test vs. t-Test
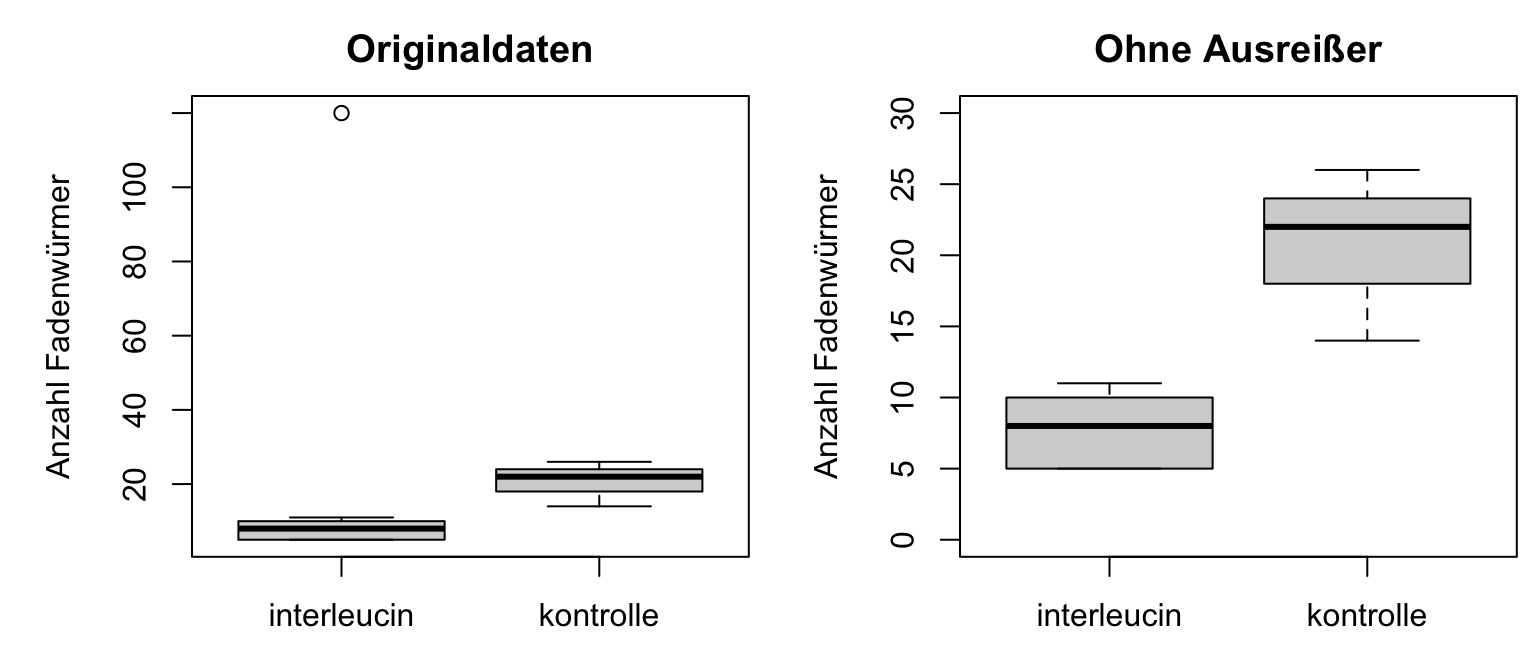
Einfluss von Ausreißern
Unterscheiden sich mit Fadenwürmern infizierte und mit Interleucin-33 behandelte Mäuse von nicht behandelten Kontrollen in der Zahl adulter Fadenwürmer im Dünndarm?
Übungsaufgaben
![]()
Übungstag 3
Einführung in die inferenzielle Statistik
![]()
- Aufgaben:
- Vorbereitung @home: Erstellung von Hypothesen - Korallenriffe
- Aufgaben @Übungsstunde: Parametrischer Zweistichprobentest für unabhängige Stichproben
- Prüfung der (parametrischen) Testannahmen (SW-, KS, F-Tests)
- Vergleich der Gruppenmittelwerte: Student’s t-Test oder Welch-Test
- Challenges @Übungsstunde & @home: MWU-Test, Testwahl
- Fallstudie @home: Fragestellung 2.1
- R Notebook-Skript:
- DS2_03_Uebungen_Hypothesen_Anpassungstests_Zweistichprobentests.Rmd
Abschlussquiz
![]()
Bei weiteren Fragen: saskia.otto(at)uni-hamburg.de

Diese Arbeit is lizenziert unter einer Creative Commons Attribution-ShareAlike 4.0 International License mit Ausnahme der entliehenen und mit Quellenangabe versehenen Abbildungen.