,_male.jpg){kind=link}
{kind=link}
5-Hypothesentest oder was ist eine H0?
Data Science 2
Universität Hamburg, IMF & IZS
Sommersemester 2026
Lernziele
![]()
Am Ende dieser VL- und Übungseinheit werden Sie
- eigene Forschungshypothesen formulieren können.
- den Unterschied zwischen der Null- und Alternativ-Hypothese kennen.
- Hypothesentests schrittweise durchführen können
- Stichproben auf ihre Normalverteilung und Varianzhomogenität testen können.
Heutige Frage
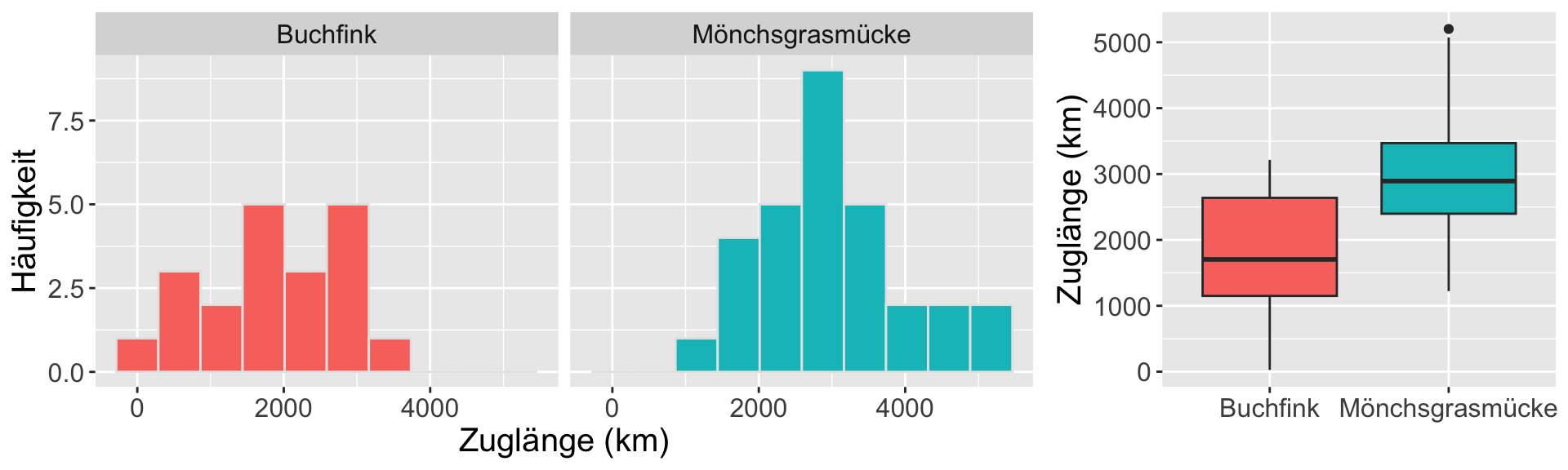
Können wir sagen dass, basierend auf unserer Stichprobe, die intraspezifische Streuung des Zugverhaltens bei Buchfinken allgemein kleiner ist als bei der Mönchsgrasmücke?


Bildquellen: Wikipedia (Buchfink unter CC BY-SA 2.5 Lizenz) und Mönchsgrasmücke unter CC0 Lizenz)
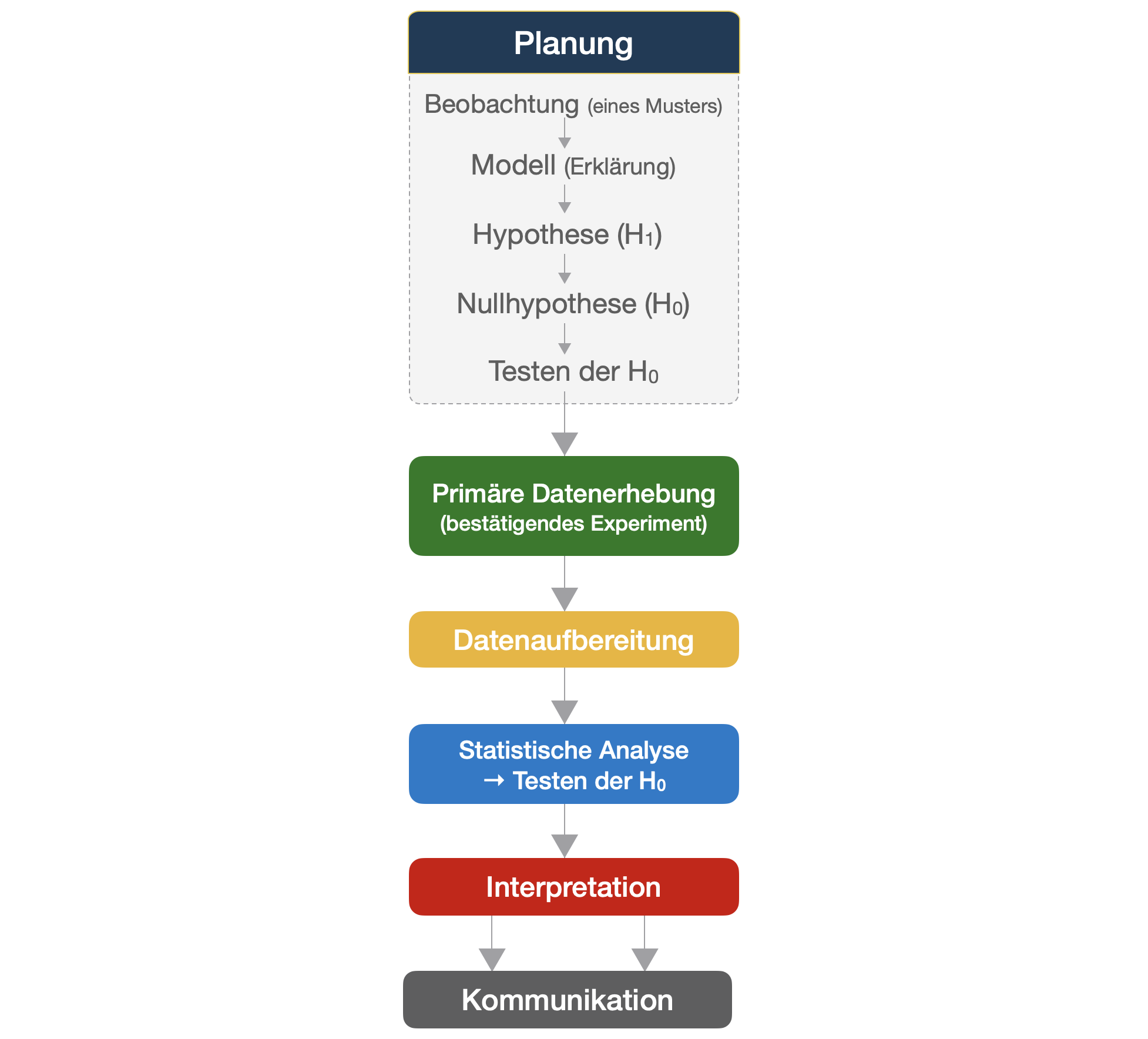
Klassischer Weg in der inferenziellen Statistik | 1
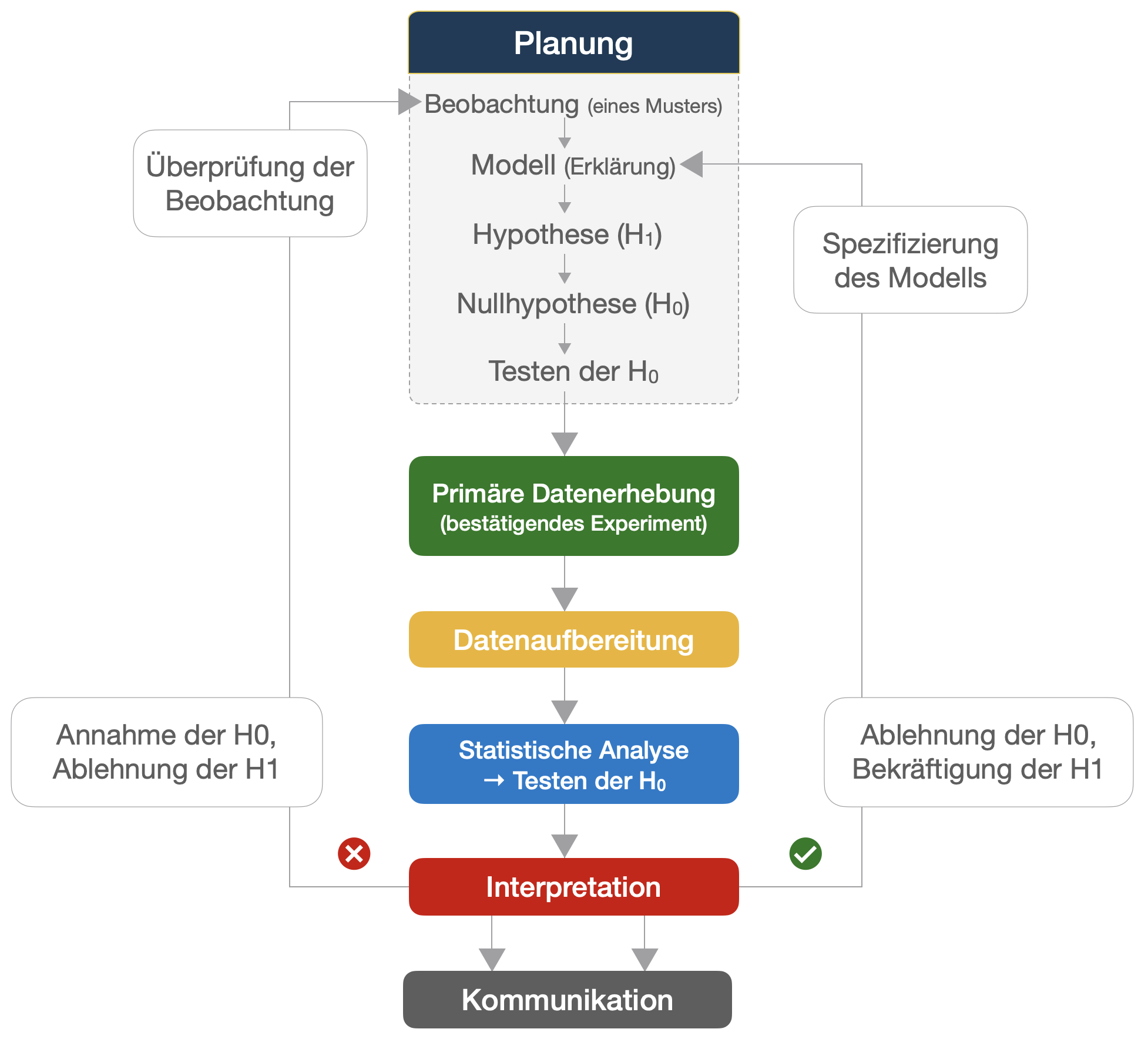
Klassischer Weg in der inferenziellen Statistik | 2
Formulierung der Hypothesen

Was ist ein MUSTER?
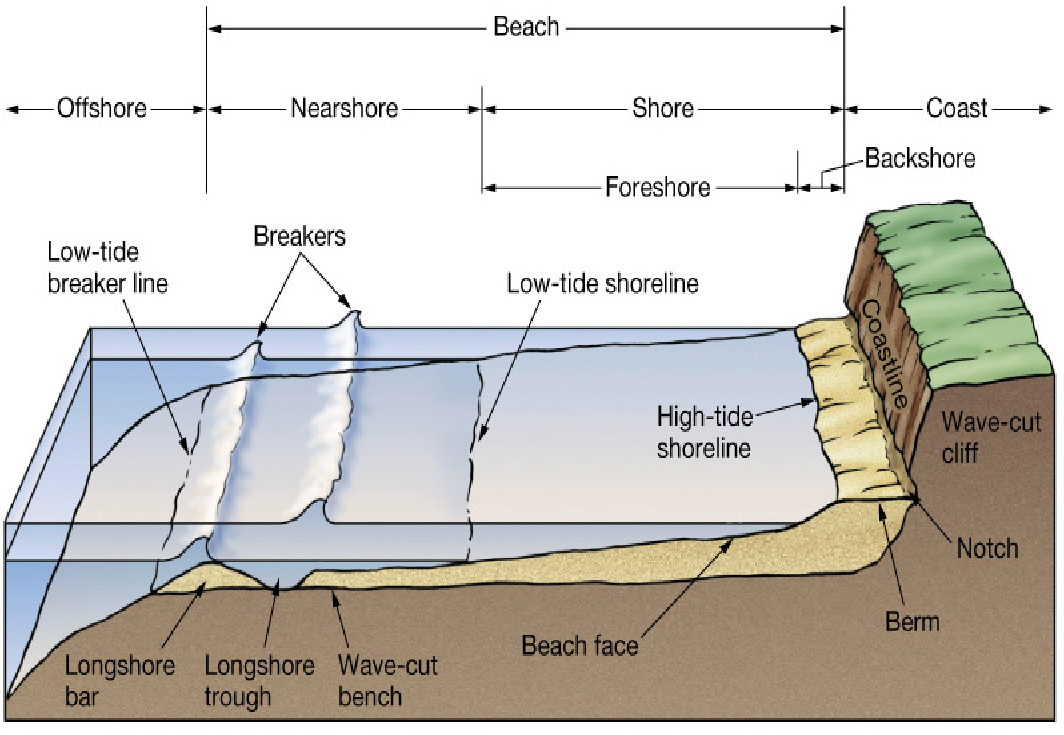

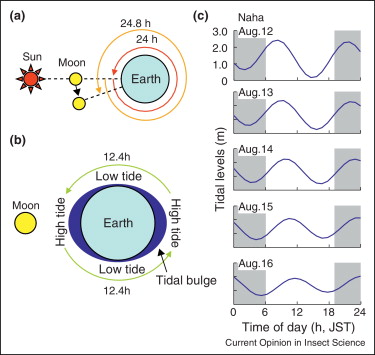
- Kein Chaos oder stochastisches Verhalten
- Regelmäßigkeiten, z.B.
- Räumliche Verteilungen (Küstenzonierung, Umweltgradienten, Streifenmuster bei Schlangen)
- Zeitliche Rhythmen (Sonnenaufgang, Mondphasen, Jahreszeiten, Gezeiten)
- Stetige Veränderungen (Alterung, Wachstum, Klimawandel)
![]() Das MODELL ist eine Erklärung für das Muster, es postuliert Regeln oder Prozesse.
Das MODELL ist eine Erklärung für das Muster, es postuliert Regeln oder Prozesse.
Bildquellen: Goto & Takekata 2015, H.Y. Siry 2007
MUSTER: Saisonale Wanderung einer Fischpopulation
4 mögliche Modelle
- Modell 1: Die Fische folgen der Beute.
- Modell 2: Die Fische meiden saisonal auftauchende Raubtiere.
- Modell 3: Die Fische meiden saisonal niedrige Temperaturen.
- Modell 4: Es ist Gottes Wille.
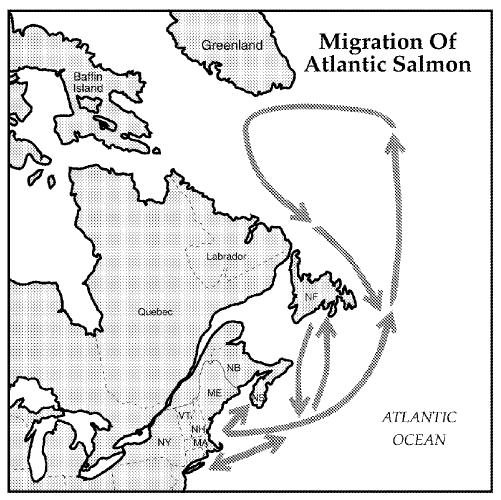
Abb. rechts: Meereswanderung des Atlantischen Lachses
(Atlantic Salmon Life Cycle, U.S. Fish & Wildlife Service, 2010)
HYPOTHESEN: Saisonale Wanderung einer Fischpopulation
4 mögliche Modelle
- Modell 1: Die Fische folgen der Beute.
- H1: Wenn die Fische gefüttert werden, bleiben sie.
- Modell 2: Die Fische meiden saisonal auftauchende Raubtiere.
- H1: Wenn die Raubtiere reduziert oder aus dem Gebiet ausgeschlossen werden,…
- Modell 3: Die Fische meiden saisonal niedrige Temperature.
- H1: Wenn der Kühlwasserabfluss erhöht wird, …
- Modell 4: Es ist Gottes Wille.
- H1: ???
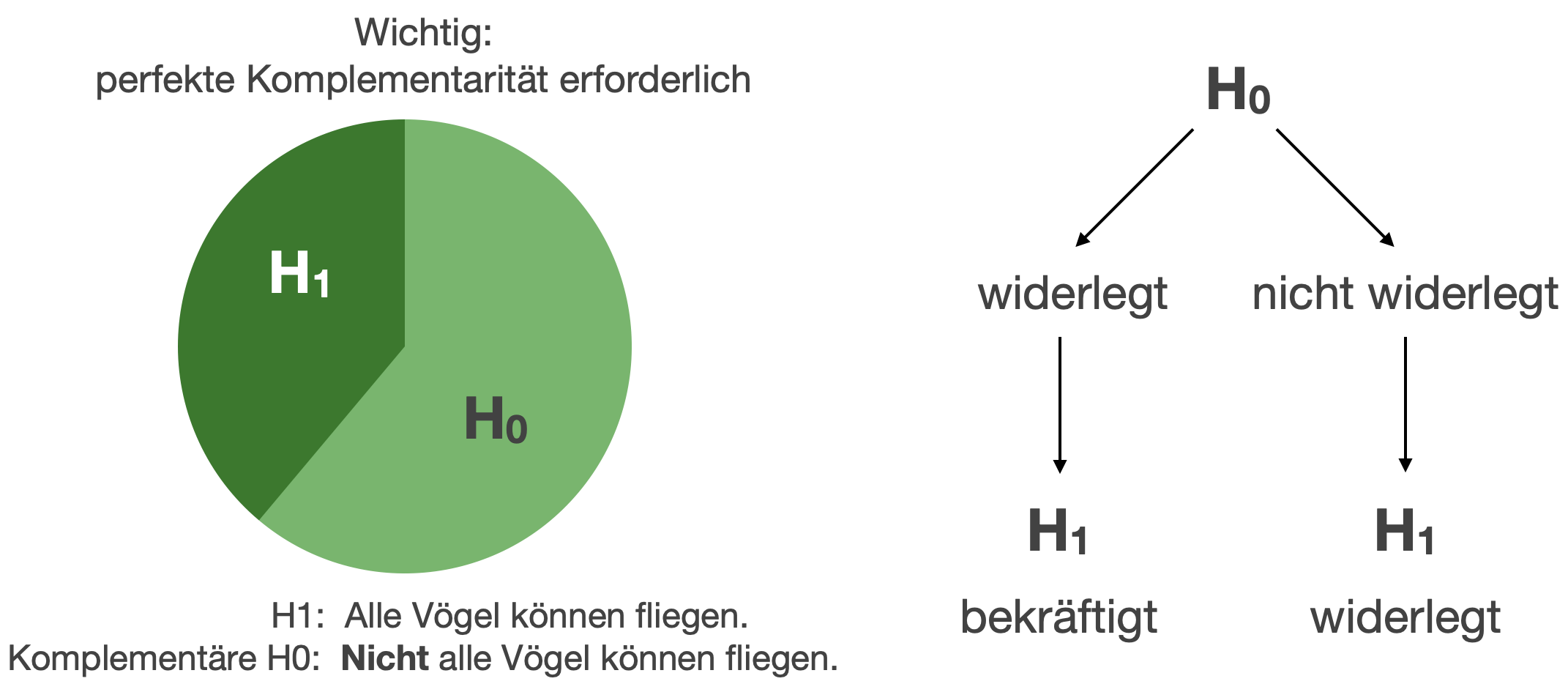
Sir Karl Poppers Idee der Widerlegung oder Falsifikation
- Der Wahrheitsgehalt einer Vorhersage kann nicht für alle Fälle, Orte und Zeiten bewiesen werden, aber ihre Widerlegung ist leicht möglich!
- → Bestärkung der H1 durch Widerlegung der Gegenhypothese (sog. Null-Hypothese oder H0).
Signifikanztests
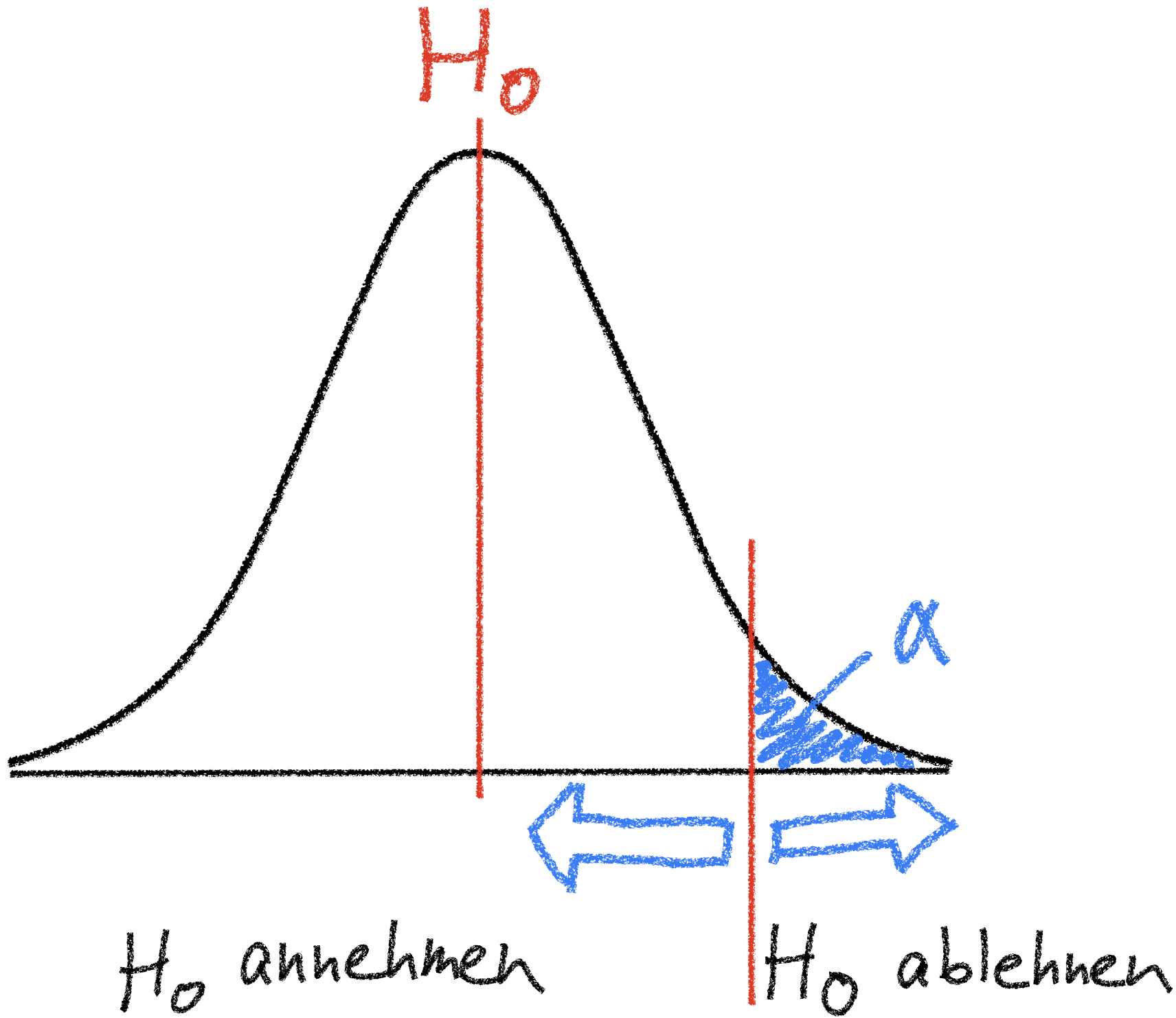
Was sind Signifikanztests?
- Zielen auf eine Entscheidung über die Beibehaltung oder Ablehnung einer statistischen Hypothese ab.
- Die Hypothese bezieht sich immer auf einen statistischen Kennwert.
- Je nachdem, ob der Stichprobenkennwert in den Annahme- oder Ablehnungsbereich fällt (also größer oder kleiner als der kritischen Werte ist), wird die Hypothese als richtig oder nicht zutreffend angesehen.
Schritt 1 | Wahl der Statistik
Beispiel einer Forschungshypothese
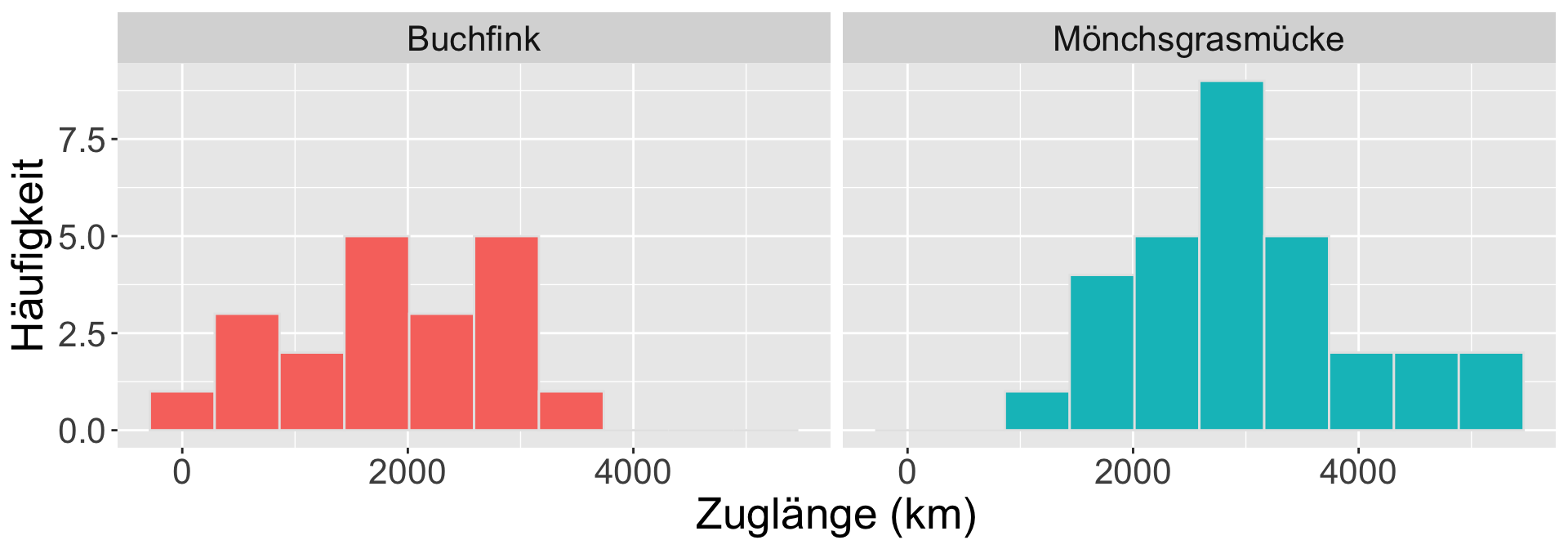
Die intraspezifische Streuung des Zugverhaltens ist bei Buchfinken kleiner als bei der Mönchsgrasmücke.
Zu vergleichender Parameter bzw. Kennwert
Die Varianz \sigma^2 bzw. s^2
Bildquellen: Wikipedia (Buchfink unter CC BY-SA 2.5 Lizenz) und Mönchsgrasmücke unter CC0 Lizenz)
Schritt 2 | Formulierung der Hypothesen
Beispiel Zugverhalten
Die intraspezifische Streuung des Zugverhaltens ist bei Buchfinken kleiner als bei der Mönchsgrasmücke.
Hypothesen (einseitig)
- H_A: \sigma_{Buchfink}^2 < \sigma_{Mönchsgrasmücke}^2
- H_0: \sigma_{Buchfink}^2 \geq \sigma_{Mönchsgrasmücke}^2
Bildquellen: Wikipedia (Buchfink unter CC BY-SA 2.5 Lizenz) und Mönchsgrasmücke unter CC0 Lizenz)
Schritt 3 | Datenerhebung und -exploration
Beispiel Zugverhalten
| Kenngröße | Buchfink | Mönchsgrasmücke |
|---|---|---|
| Mittelwert x̅ | 1800 km | 3000 km |
| Standardabweichung s | ±900 km | ±1000 km |
| Stichprobengröße n | 20 | 30 |
Wahl des statistischen Test | Schritt 4
Folgende grundlegende Fragen müssen beantwortet werden:
- Welches Skalenniveau liegt vor (nominal, ordinal, metrisch)?
- Wie viele Stichproben sollen verglichen werden (1, 2, ≥2)?
- Was soll getestet werden (Abweichungen von einer Verteilung, einer erwarteten Häufigkeitsverteilung, einem Erwartungswert)?
- Ermöglicht die Stichprobenverteilung die Anwendung parametrischer Verfahren, d.h. sind die Daten normal verteilt (und Varianzhomogen) (Schritt 3)?
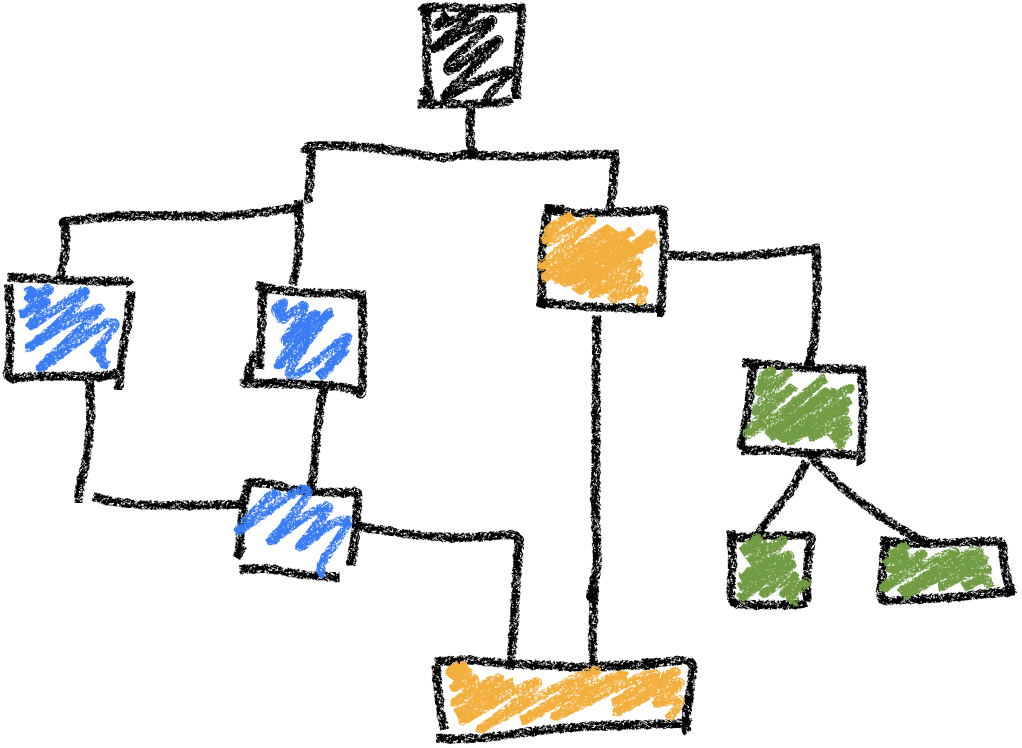
Wahl des statistischen Test | Übersicht
Klassische Tests
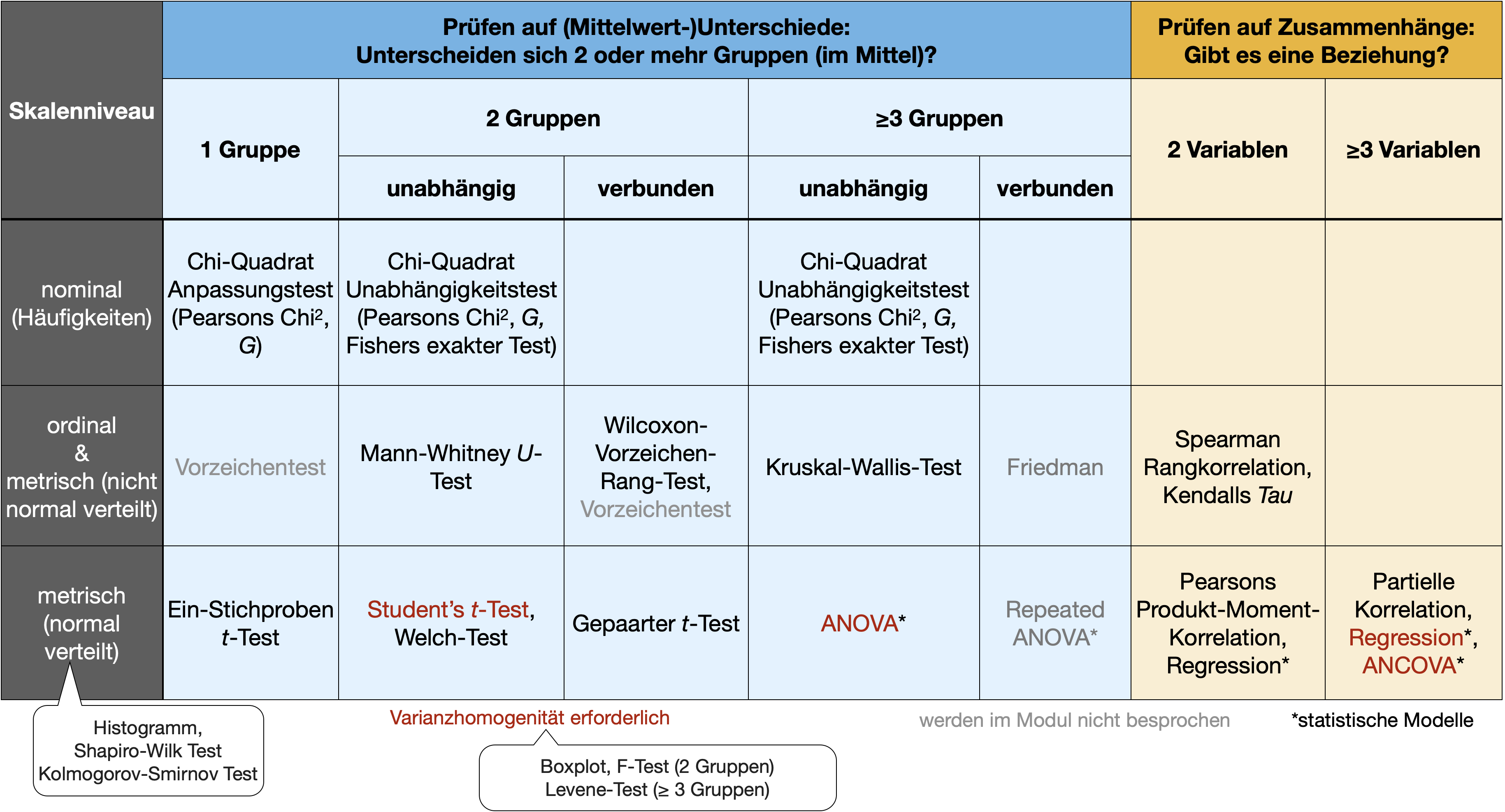
Wahl des statistischen Test | Entscheidungsbaum
Entscheidungsbaum (auch im Handbuch enthalten) sollte für die Fallstudie verwendet werden.
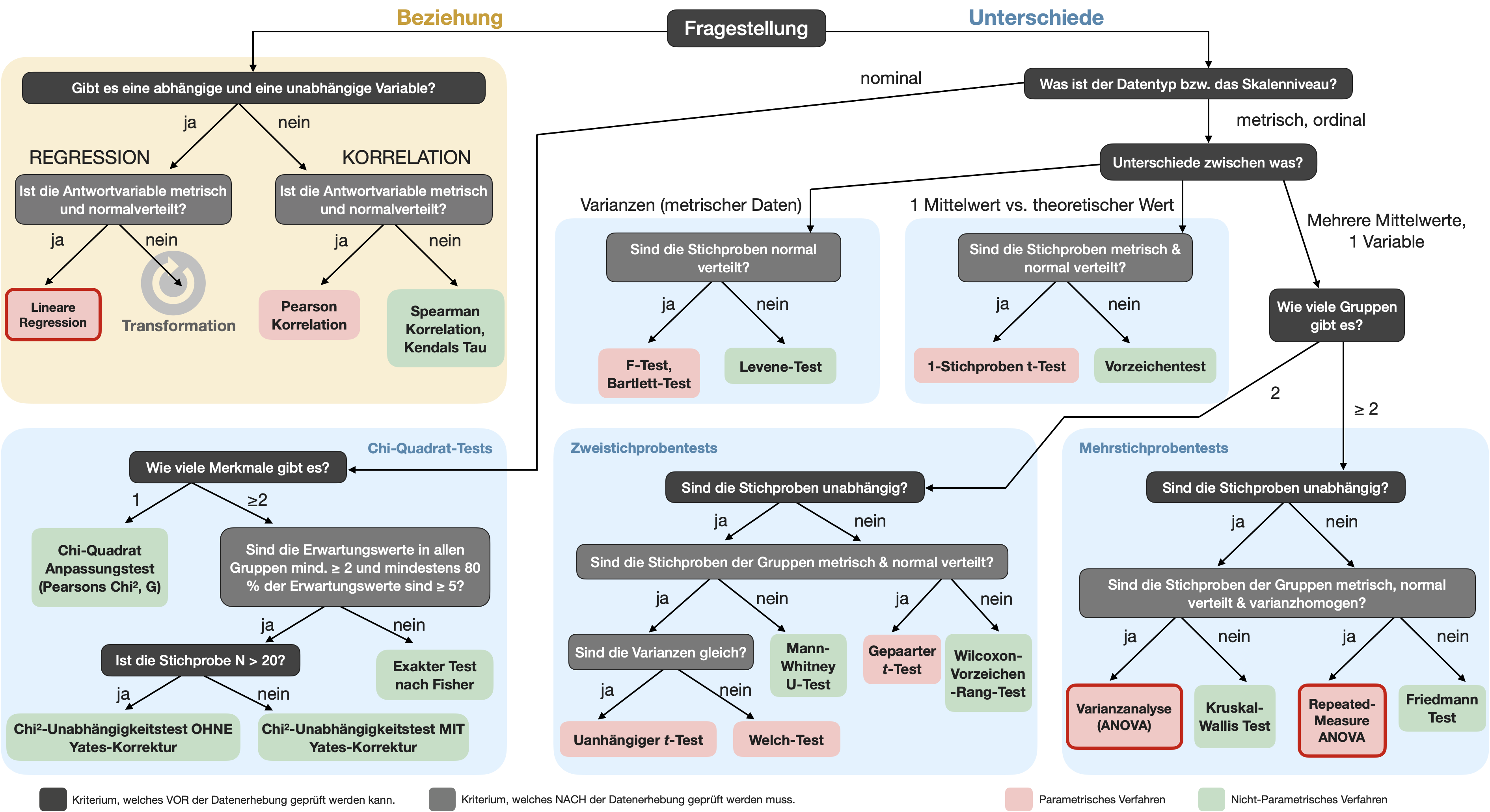
Berechnung von β
Fall 1 (links): Angenommen, wir testen die H_A, dass der Durchschnitt unserer Probe -4σ Einheiten von der H_0 entfernt sei und die H_A ist wahr. Dann ist für eine Zufallsprobe aus dieser Population die Wahrscheinlichkeit, dass sie in den Akzeptanzbereich von H_0 fällt (welcher bei ±1.96σ um μ liegt wenn α = 0.05), etwa 2.5% → β = 0.025 und die Teststärke ist dann 1-0.025=0.975 (im Durchschnitt würden wir für 97.5% aller Proben die H_0 korrekt verwerfen).
Fall 2 (rechts): Angenommen, der Unterschied der H_0 und H_A Population liegt nur noch bei -2σ Einheiten. Dann ist die Wahrscheinlichkeit, dass eine zufällig gewählte Probe von H_A außerhalb des kritischen Bereichs fällt (μ ± 1.96σ) nur noch 50%. Bei der Hälfte aller Proben würden wir also die H_0 fälschlicherweise akzeptieren (Fehler 2. Art).
Festlegung des Ablehnungsbereichs | Schritt 6
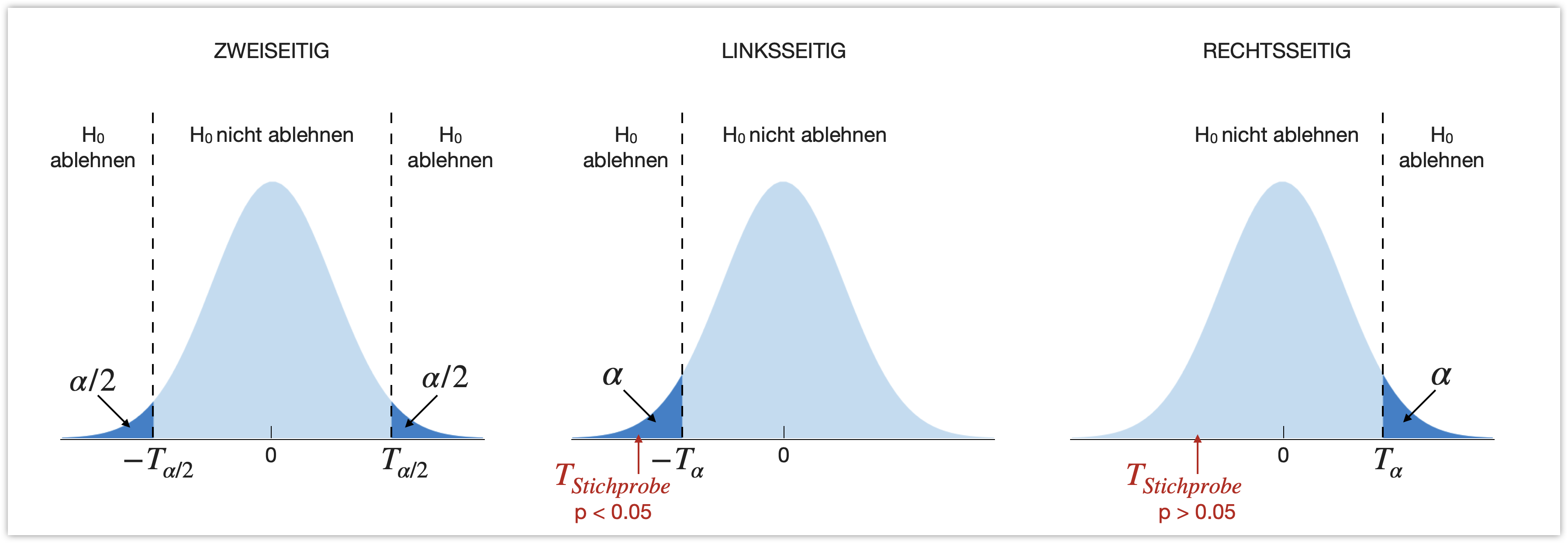
Der statistische Test..
liefert eine Teststatistik (T) und eine Wahrscheinlichkeit (p-Wert) basierend auf dessen Prüfverteilung, dass das statistische Ergebnis so extrem ausfällt wie das beobachtete, wenn die Nullhypothese wahr wäre (nach der z.B. zwei Stichproben zur gleichen Grundgesamtheit gehören).
Zusammenfassung | Schritt 8
Bei den klassischen Tests sollte immer die Teststatistik, der bzw. die Freiheitsgrade (für die Prüfverteilung), und der p-Wert angegeben werden:

Testauswahl
Auswahl des richtigen Test
Überprüfung der Testannahmen bei metrischen Daten
Normalität: Shapiro-Wilk-Test
Beispiel Zugverhalten
| Kennwert: | \mu, \sigma^2 bzw. \bar{X} und s^2 |
| H0: | X ist normalverteilt |
| HA: | X ist nicht normalverteilt |
| Teststatistik: | W |
| alpha: | 5% |
| p-Wert: | Vergleich Teststatistik W mit kritischen Wert für den Ablehnungsbereich (aus Verteilung der Teststatistik) |
Shapiro-Wilk normality test
data: bf
W = 1, p-value = 0.5
Shapiro-Wilk normality test
data: mgm
W = 1, p-value = 0.6- H_0 kann in beiden Tests nicht abgelehnt werden, da die p-Werte > 0.05 sind.
- → beide Stichproben sind normalverteilt (W = 0.96, p = 0.5 bzw. W = 0.97, p = 0.6).
Zurück zu unserer Forschungshypothese..
Die intraspezifische Streuung des Zugverhaltens ist bei Buchfinken kleiner als bei der Mönchsgrasmücke.
Bildquellen: Wikipedia (Buchfink unter CC BY-SA 2.5 Lizenz) und Mönchsgrasmücke unter CC0 Lizenz)
Your turn …
![]()
Quiz 1 zum Nachmachen
![]()
Normalverteilung der Kelchblattlänge
Shapiro-Wilk normality test
data: iris$Sepal.Length[iris$Species == "setosa"]
W = 1, p-value = 0.5
Shapiro-Wilk normality test
data: iris$Sepal.Length[iris$Species == "versicolor"]
W = 1, p-value = 0.5
Shapiro-Wilk normality test
data: iris$Sepal.Length[iris$Species == "virginica"]
W = 1, p-value = 0.3Quiz 2 zum Nachmachen
![]()
Varianzvergleich der Kelchblattlänge
F test to compare two variances
data: set and ver
F = 0.5, num df = 49, denom df = 49, p-value = 0.009
alternative hypothesis: true ratio of variances is not equal to 1
95 percent confidence interval:
0.265 0.822
sample estimates:
ratio of variances
0.466 Übungsaufgaben
![]()
Vorbereitungsaufgabe für Übungstag 3

Was ist zu tun?
Die passenden Null- und Alternativhypothesen für ein Modell zu Veränderungen in Korallenriffen definieren.
Wichtig
Moodle-Quiz VOR der nächsten Übung ausfüllen!
Abschlussquiz
![]()
Bei weiteren Fragen: saskia.otto(at)uni-hamburg.de

Diese Arbeit is lizenziert unter einer Creative Commons Attribution-ShareAlike 4.0 International License mit Ausnahme der entliehenen und mit Quellenangabe versehenen Abbildungen.