,_male.jpg){kind=link}
{kind=link}
{kind=link}
4-Schätzverfahren oder was ist ein KI?
Data Science 2
Universität Hamburg, IMF & IZS
Sommersemester 2026
Lernziele
![]()
Am Ende dieser VL- und Übungseinheit werden Sie
- den Unterschied zwischen einem Punktschätzer und einem Intervallschätzer kennen.
- wissen, wie Sie Ihre Punktschätzung optimieren können.
- verstanden haben, was es mit den Freiheitsgraden bei der Varianz auf sich hat.
- das Konfidenzintervall für den Mittelwert für große wie kleine Stichproben berechnen können.
- den Mindeststichprobenumfang für die Ermittlung eines KI für den Mittelwert berechnen können.
Heutige Frage
Unterscheiden sich verschiedene Vogelarten in Skandinavien in der mittleren Entfernung ihrer Zugdistanzen?



Bildquellen: Wikipedia (Buchfink und Grünfink unter CC BY-SA 2.5 Lizenz), Mönchsgrasmücke unter CC0 Lizenz)
Schätzverfahren

Punktschätzung | Wie funktioniert das?
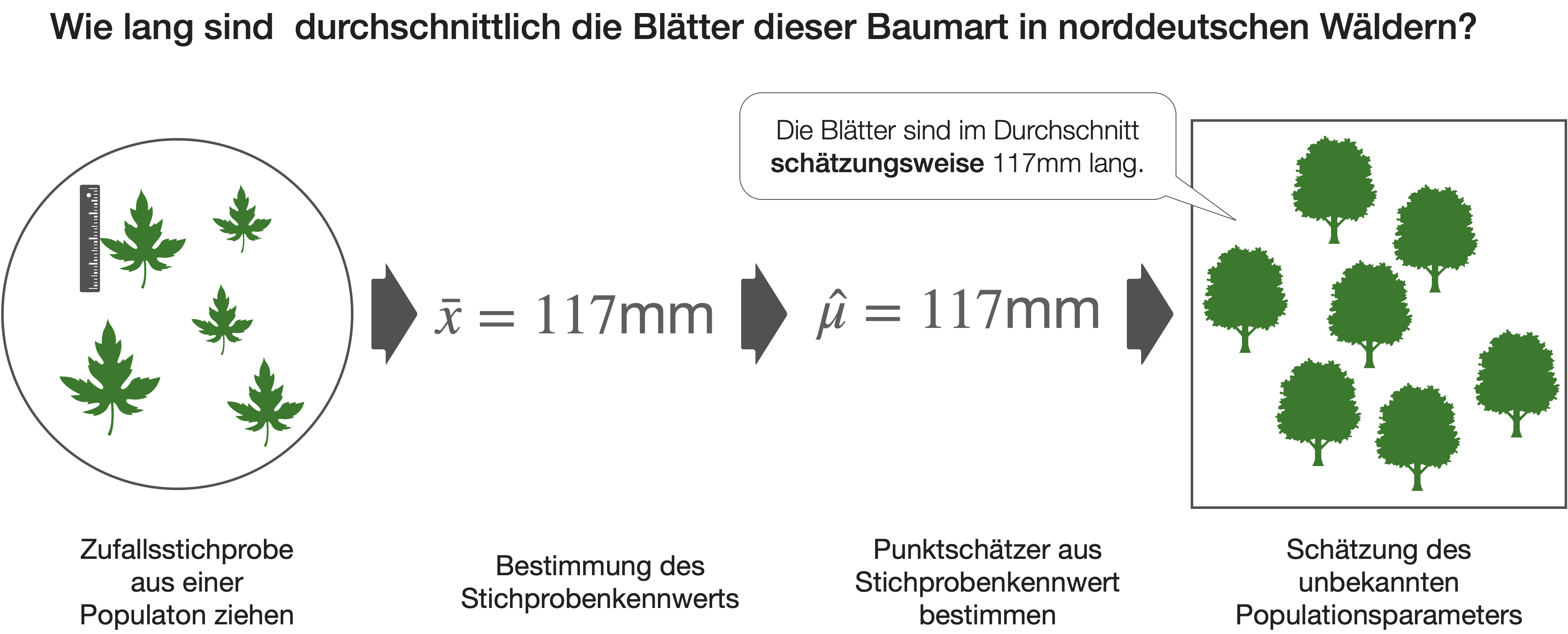
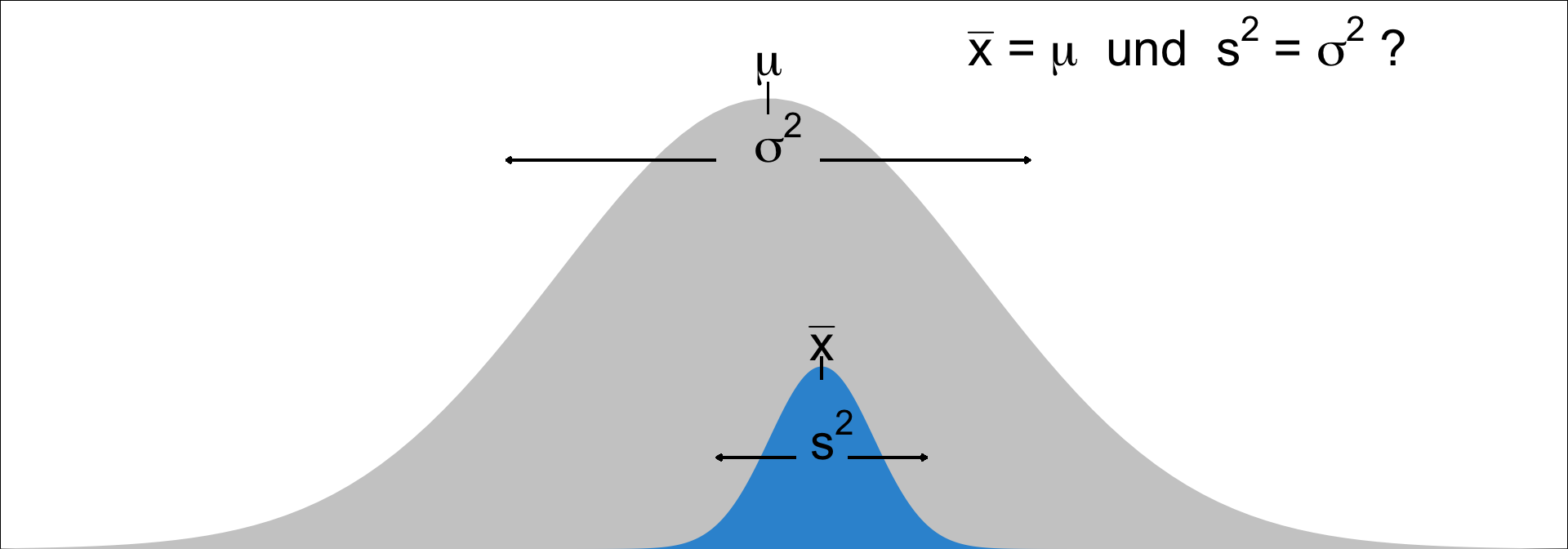
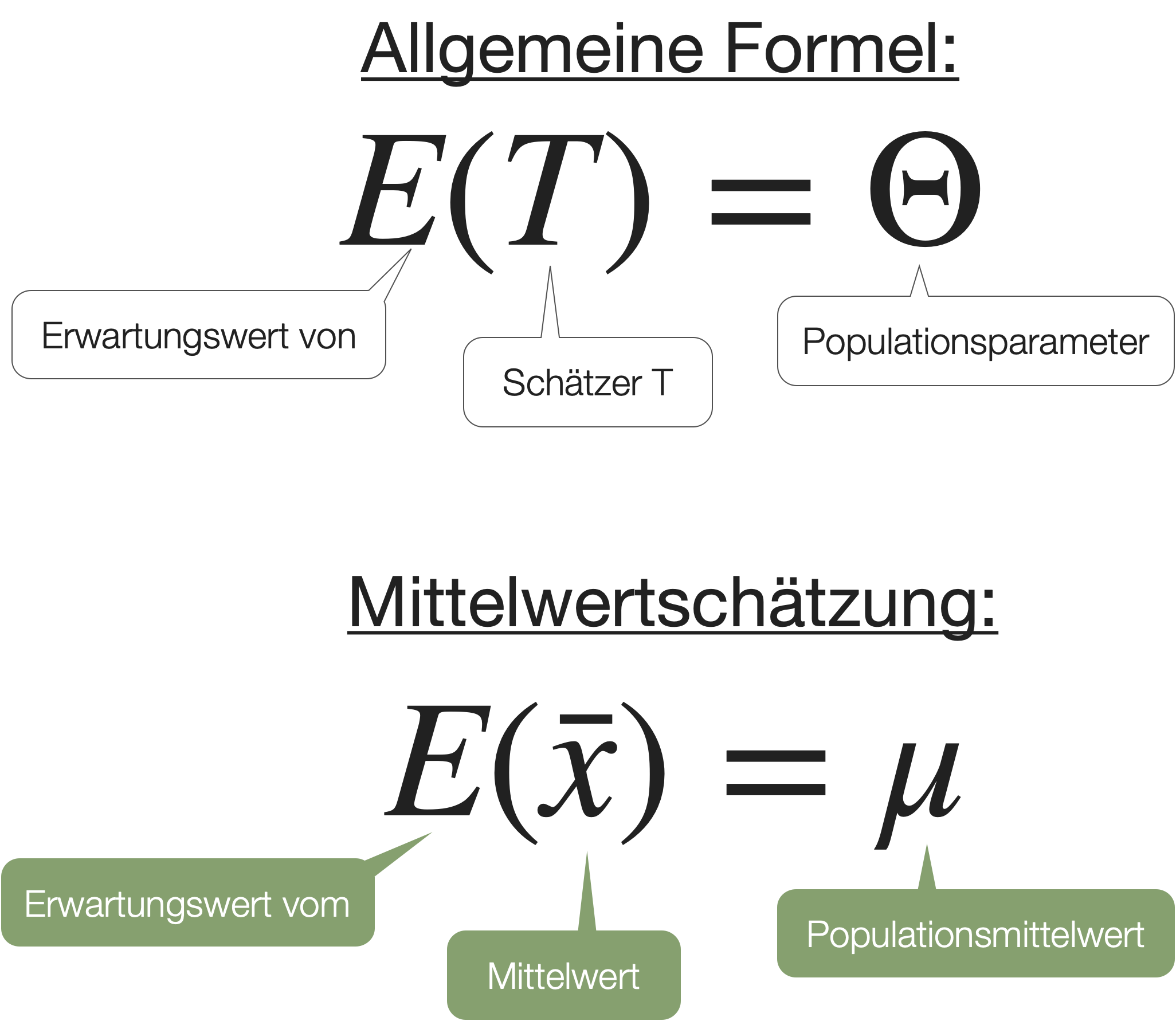
- Damit Stichprobenkennwerte als Punktschätzer genutzt werden können, müssen sie ‘erwartungstreu’ sein, d.h. keinen systematischen Fehler enthalten.
- → Dann entspricht z.B. der Mittelwert der Stichprobenverteilung (=Erwartungswert E(\bar{x})) dem Populationsmittelwert → und dann ist auch \bar{x} ein guter Schätzer für \mu.
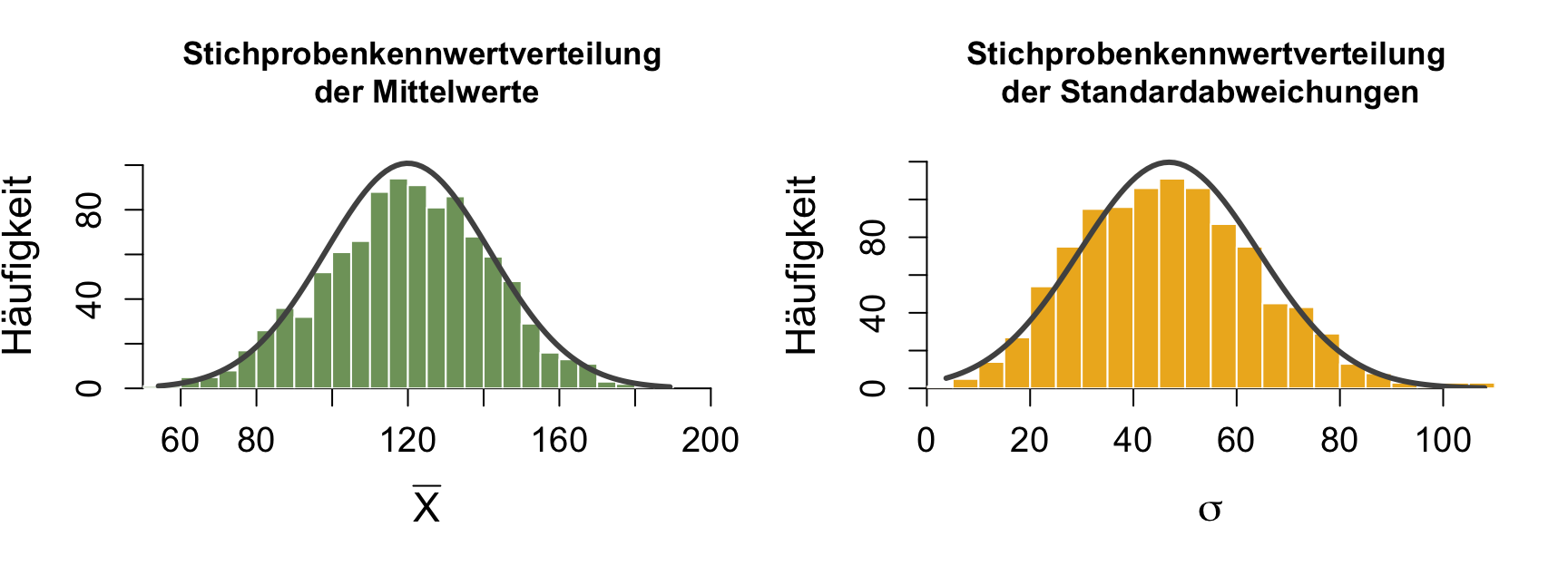
Die Stichprobenkennwertverteilung | 1
Eine hypothetische Verteilung
Die Stichprobenkennwertverteilung | 2
Einflussgrößen
![]()
Ihre Verteilung ist abhängig von
- der Verteilung des Merkmals in der Population.
- der Größe der Stichprobe (N).
- dem Typ des Kennwerts.
- der Art der Stichprobe (repräsentativ oder nicht).
Punktschätzung | Mittelwert
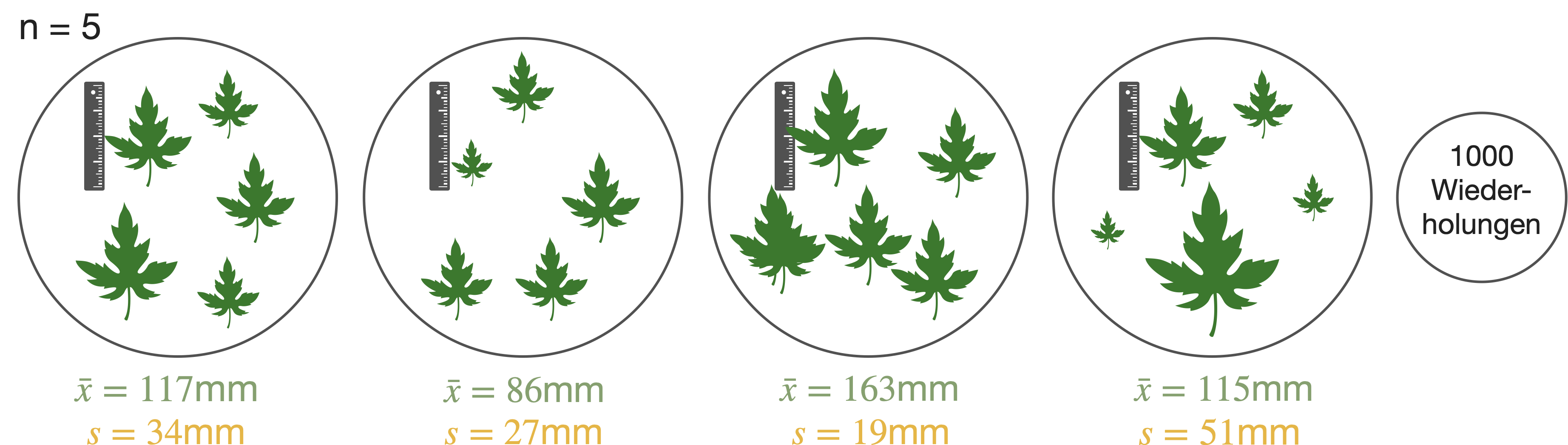
Beispiel mit \mu = 120\text{mm}
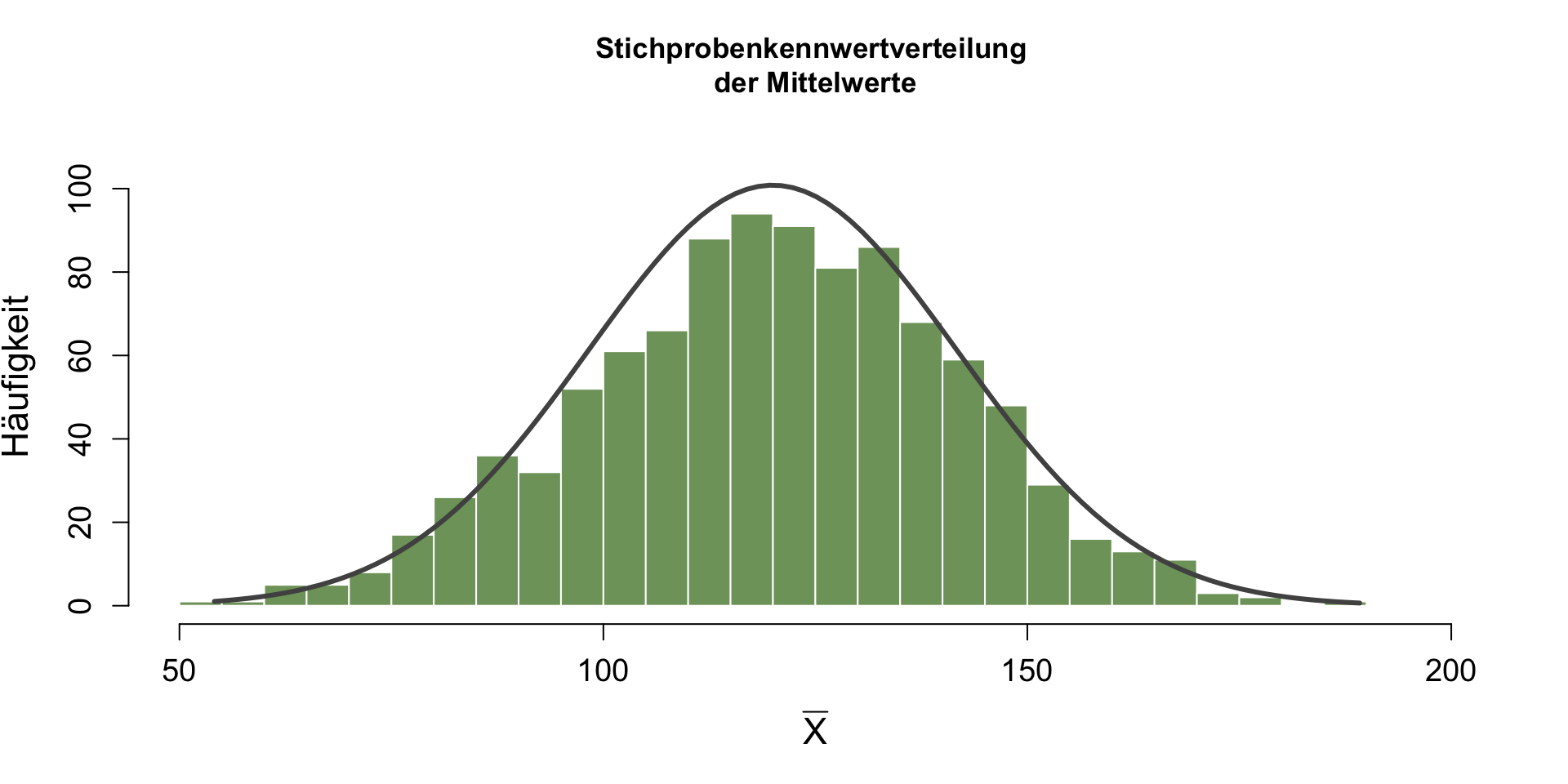
- Bei 1000 Proben mit je N = 5 ist Mittelwert der Stichprobenkennwertverteilung: E(\bar{x}) = 119.97 \text{mm}
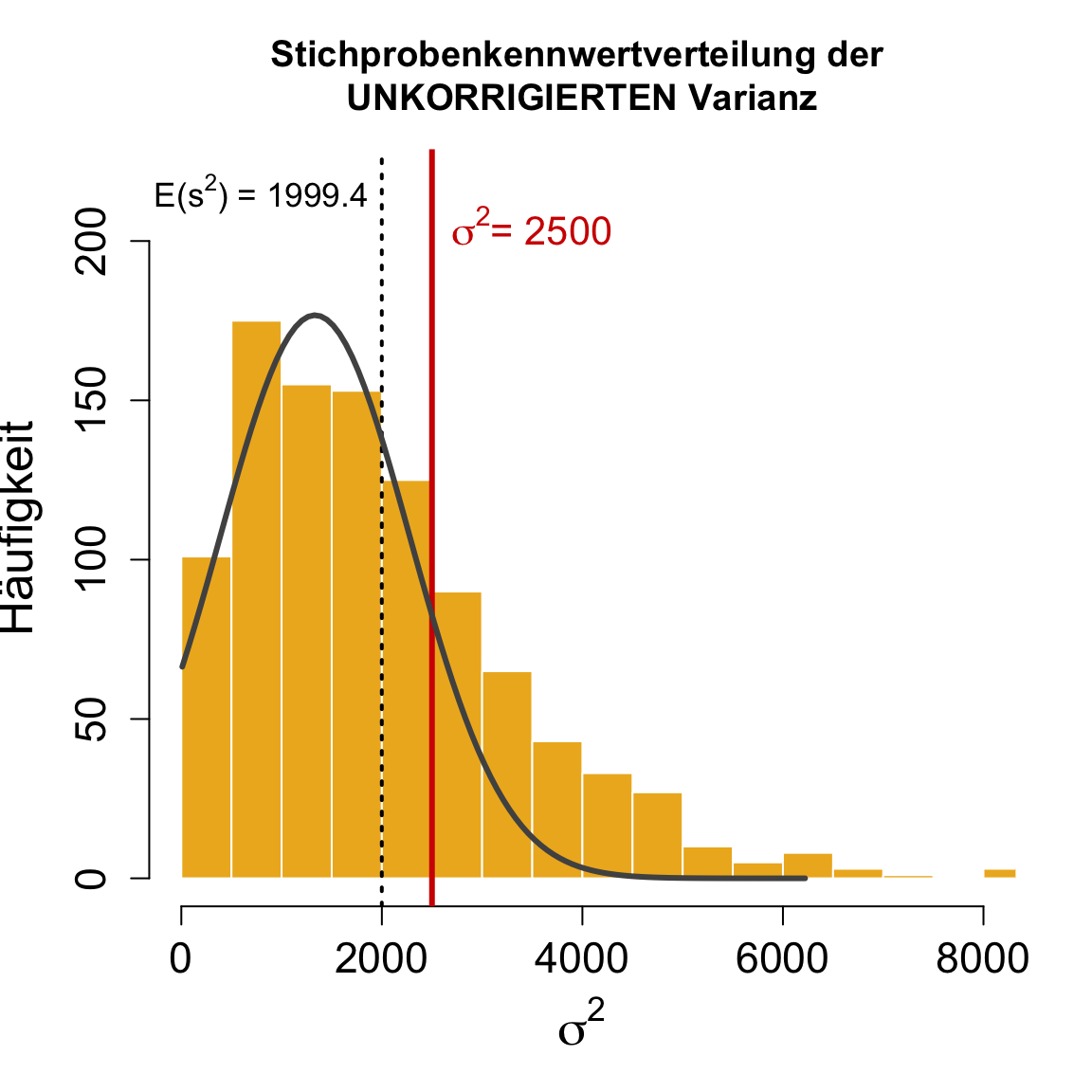
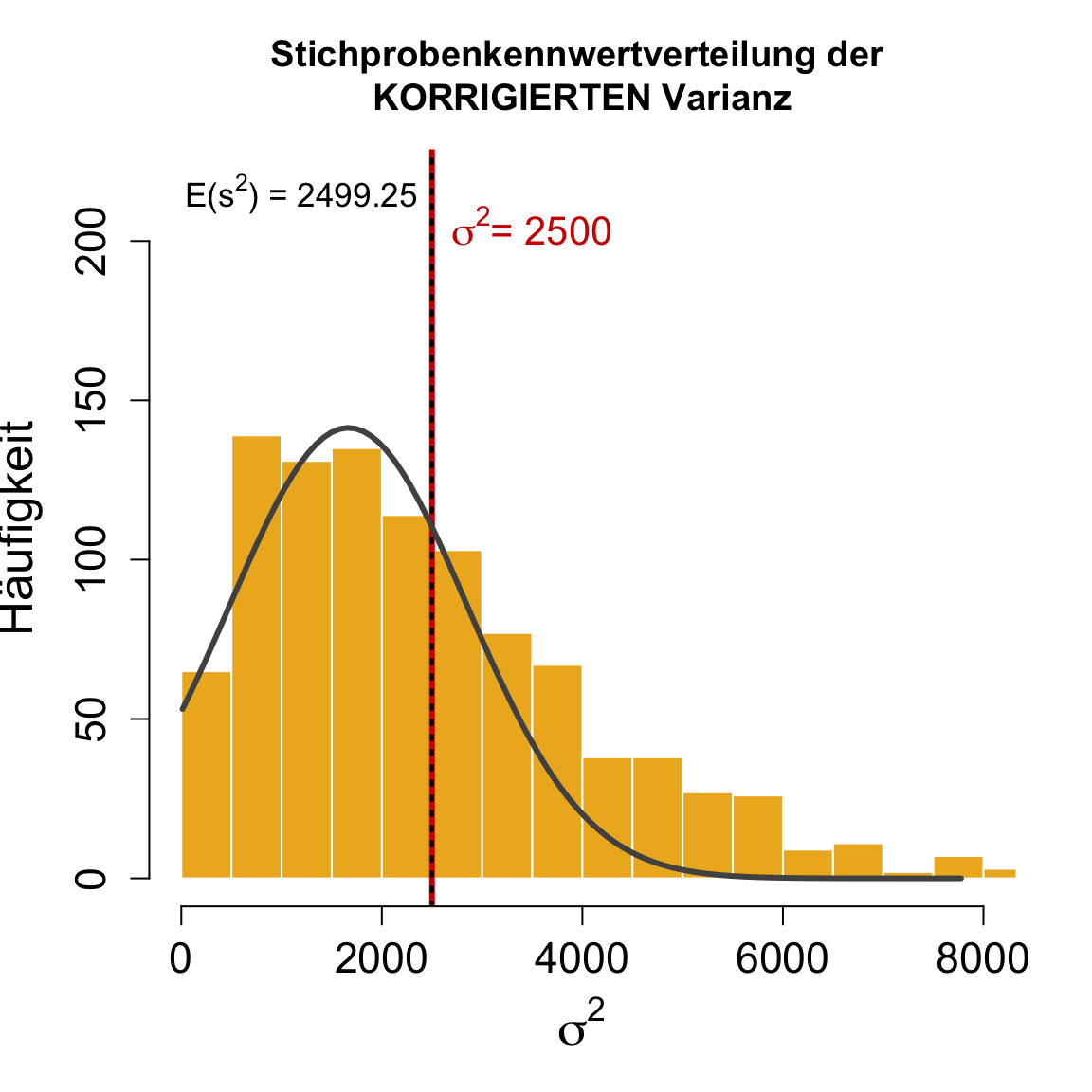
Punktschätzung | Varianz 2
Beispiel mit \sigma^2 = 2500
Konfidenzintervalle (KI)
Ausgangsfrage
- Wie präzise ist diese Schätzung von 117mm?
- Kann es denn sein, dass der wahre Populationsmittelwert auch 100mm oder 140mm ist und wir einfach Pech mit der Probe hatten?
- In welchem Bereich liegt der wahre Mittelwert höchstwahrscheinlich?
Diese Fragen kann ein Punktschätzer nicht beantworten – aber ein Intervallschätzer!
Intervallschätzung | 2
Konfidenzintervall
- KIs sind immer 2-seitig da Parameter immer größer oder kleiner als der Kennwert sein können:
- 95% => 2.5% auf beiden Seiten.
- Grundsätzlich gilt: je höher die Konfidenz, desto breiter das Intervall.
- Zur Berechnung des KI wird der Standardfehler mit einer geeigneten statistischen Verteilung kombiniert, zum Beispiel
- z und t für Mittelwerte,
- \chi^2 für Varianzen.
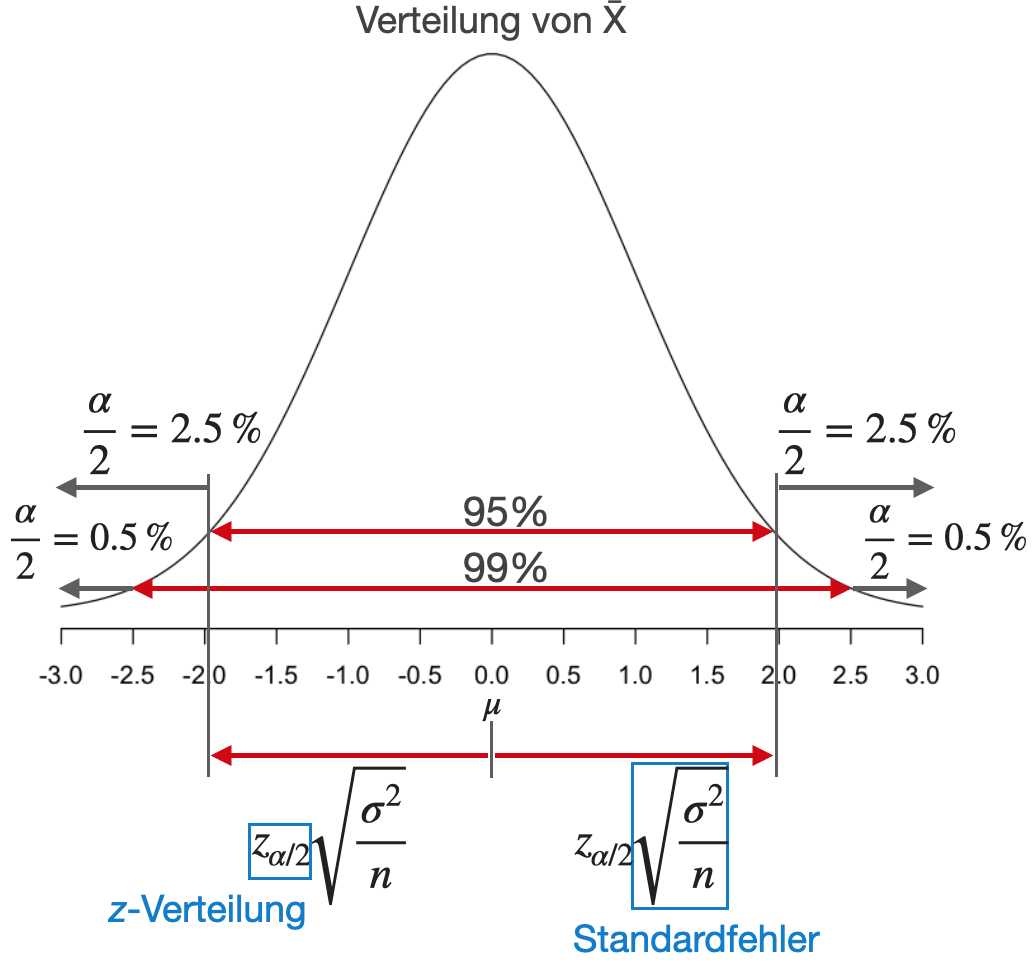
Im folgenden gehen wir zwei Beispiele für die Konfidenzintervalle des Mittelwerts durch.
Berechnung in R: Große Stichprobe
Beispiel Blattlänge
\mu = 120\text{mm}, \sigma = 50\text{mm}
Normalverteilung bei N = 500
[1] 120[1] 2.1[1] -1.96[1] 1.96[1] -4.12[1] 4.12→ Der wahre Populationsmittelwert liegt mit 95%-iger Konfidenz im Bereich 115.90 – 124.10 (120 ± 4.10).
Berechnung in R: Kleine Stichprobe | 1
Beispiel Blattlänge
\mu = 120\text{mm}, \sigma = 50\text{mm}
t-Verteilung bei N = 5
[1] 132[1] 19.3[1] -2.78[1] 2.78[1] -53.6[1] 53.6→ Der wahre Populationsmittelwert liegt mit 95%-iger Konfidenz im Bereich 78.30 – 185.50 (131.90 ± 53.60).
Your turn …
![]()
Quiz: Vergleichen Sie die Konfidenzintervalle | 1
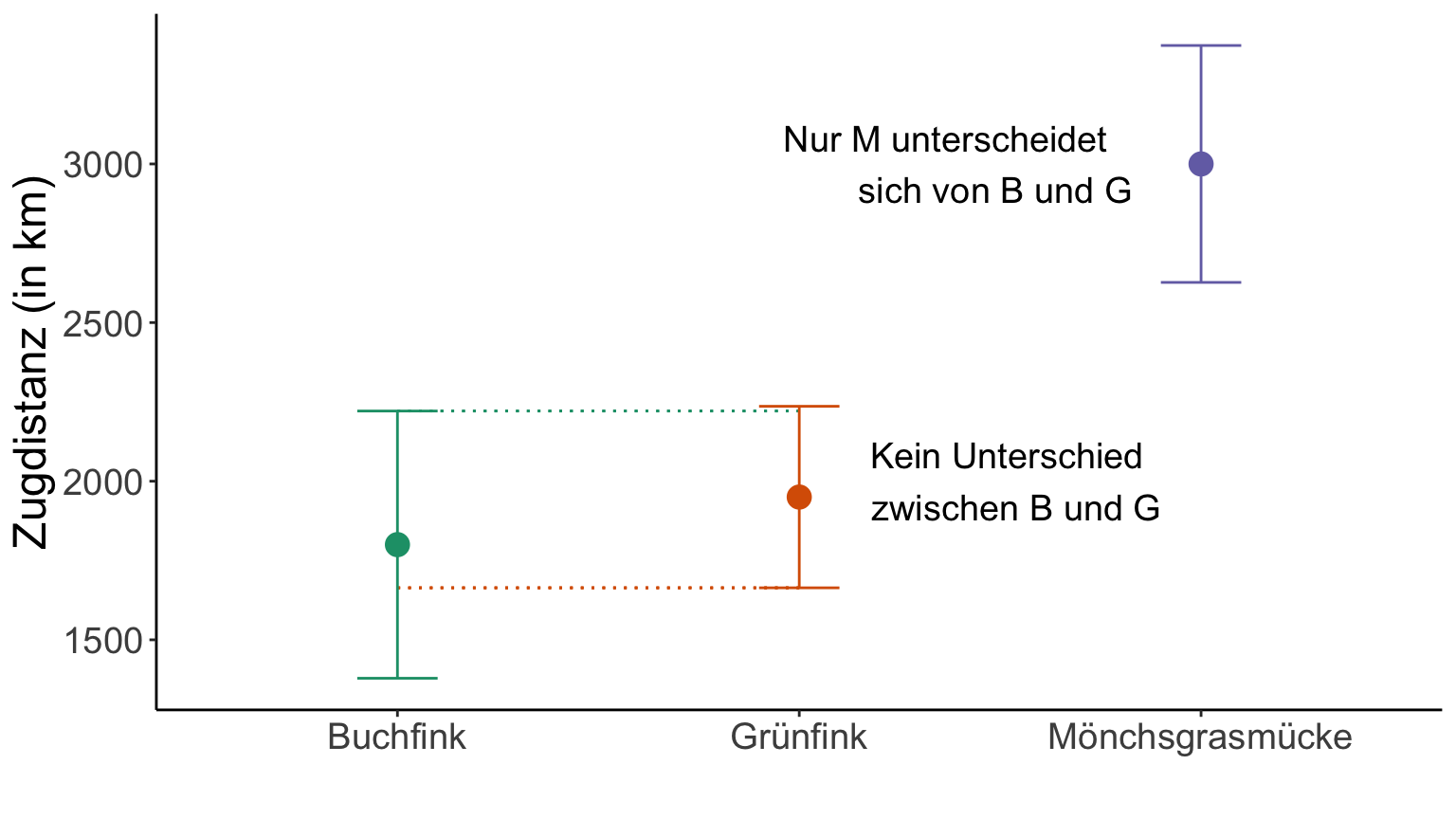
Wie groß ist das KI_{95\%} beim Zugverhalten verschiedener Vogelarten?
Bildquellen: Wikipedia (Buchfink und Grünfink unter CC BY-SA 2.5 Lizenz), Mönchsgrasmücke unter CC0 Lizenz)
Quiz: Vergleichen Sie die Konfidenzintervalle | 2
![]()
Statistiken der erhobenen Daten:
| Kenngröße | Buchfink | Grünfink | Mönchsgrasmücke |
|---|---|---|---|
| Mittelwert x̅ | 1800 km | 1950 km | 3000 km |
| Standardabweichung s | ±900 km | ±400 km | ±1000 km |
| Stichprobengröße n | 20 | 10 | 30 |
| t_{(\alpha, df)} | 2.09 | 2.26 | 2.04 |
Da symmetrisches KI, nur Berechnung des oberen Bereichs
[1] "1378.8 - 2221.2 (±421.2)"[1] "1663.9-2236.1 (±286.1)"[1] "2626.6-3373.4 (±373.4)"Visualisierung des KI
- Wenn das 95% Konfidenzintervall (KI) der einen Stichprobe das KI der anderen nicht beinhaltet, kann man schlussfolgern, dass sich die Mittelwerte voneinander unterscheiden.
Berechnung des Stichprobenumfangs N
Bei Normalverteilung
Umformung der Formel zur Berechnung des KI des Mittelwerts nach der Stichprobe:
E = z_{\alpha/2}\sqrt\frac{\sigma^2}{n}
\Rightarrow~n=(\frac{z_{\alpha/2}\cdot\sigma}{E})^2
(E ist der maximale Schätzfehler)
Beispiel: Zugverhalten des Buchfink
Wie groß muss N sein, damit wir zu 99% sicher sind, dass der wahre Mittelwert im Bereich ±25 km (=E) um den Stichprobenmittelwert liegt?
- Bereits bekannt (aus vorheriger Studie):
- \alpha = 0.01 → z_{\alpha/2}=2.58
- \sigma = 900\text{ km}
- E = 25\text{ km}
- n=(\frac{z_{\alpha/2}\cdot\sigma}{E})^2=(\frac{2.58\cdot 900}{25})^2 = 8599
Übungsaufgaben
![]()
Übungstag 2
Wahrscheinlichkeitsverteilungen und Schätzverfahren
![]()
- Aufgaben:
- Vorbereitung @home: zentraler Grenzwertsatz
- Aufgaben @Übungsstunde
- Standardnormalverteilung: Berechnung von Wahrscheinlichkeiten bei Hailängen
- Schätzverfahren: Konfidenzintervalle (KI) basierend auf Wahrscheinlichkeitsverteilungen
- Fallstudie @home: Fragestellung 1
- R Notebook-Skript:
- DS2_02_Uebungen_Wahrscheinlichkeitsverteilungen_Schätzverfahren.Rmd
Abschlussquiz
![]()
Bei weiteren Fragen: saskia.otto(at)uni-hamburg.de

Diese Arbeit is lizenziert unter einer Creative Commons Attribution-ShareAlike 4.0 International License mit Ausnahme der entliehenen und mit Quellenangabe versehenen Abbildungen.