3-Wahrscheinlichkeitsverteilungen
Data Science 2
Universität Hamburg, IMF & IZS
Sommersemester 2026
Lernziele
![]()
Am Ende dieser VL- und Übungseinheit werden Sie
- eine Wahrscheinlichkeitsverteilung für eine Zufallsvariable in R konstruieren können.
- eine zufällige Stichprobe aus einer Population mit einer bestimmten Wahrscheinlichkeitsverteilung ziehen können.
- Daten mittels Z-Transformation in eine Standardnormalverteilung überführen können.
- Wahrscheinlichkeiten mittels Verteilungsfunktion (CDF) berechnen und
- die wichtigsten Prüfverteilungen stetiger Variablen unterscheiden können.
Einführung

Typen der Verteilung

Häufigkeitsverteilung (frequency distribution) = empirische V.
- Zeigt einfach nur an, wie oft ein Wert vorkommt (Ist-Werte).
- Die Darstellung der Realisationen x_i mit den dazugehörigen absoluten (h_i) bzw. relativen (h_i*N) Häufigkeiten erfolgt in grafischer oder tabellarischer Form.
Wahrscheinlichkeitsverteilung (probability distr.) = theoretische V.
- Zeigt an, wie häufig ein Wert hätte vorkommen sollen (Erwartungswerte).
- Jeder messbaren Teilmenge der möglichen Ergebnisse eines Zufallsexperiments wird eine Wahrscheinlichkeit zugeordnet.
- Der Erwartungswert einer Zufallsvariablen E(x) ist einfach der Mittelwert (µ) ihrer Wahrscheinlichkeitsverteilung.
- Kenntnis der Wahrscheinlichkeitsverteilung wichtig für viele statistischen Verfahren!
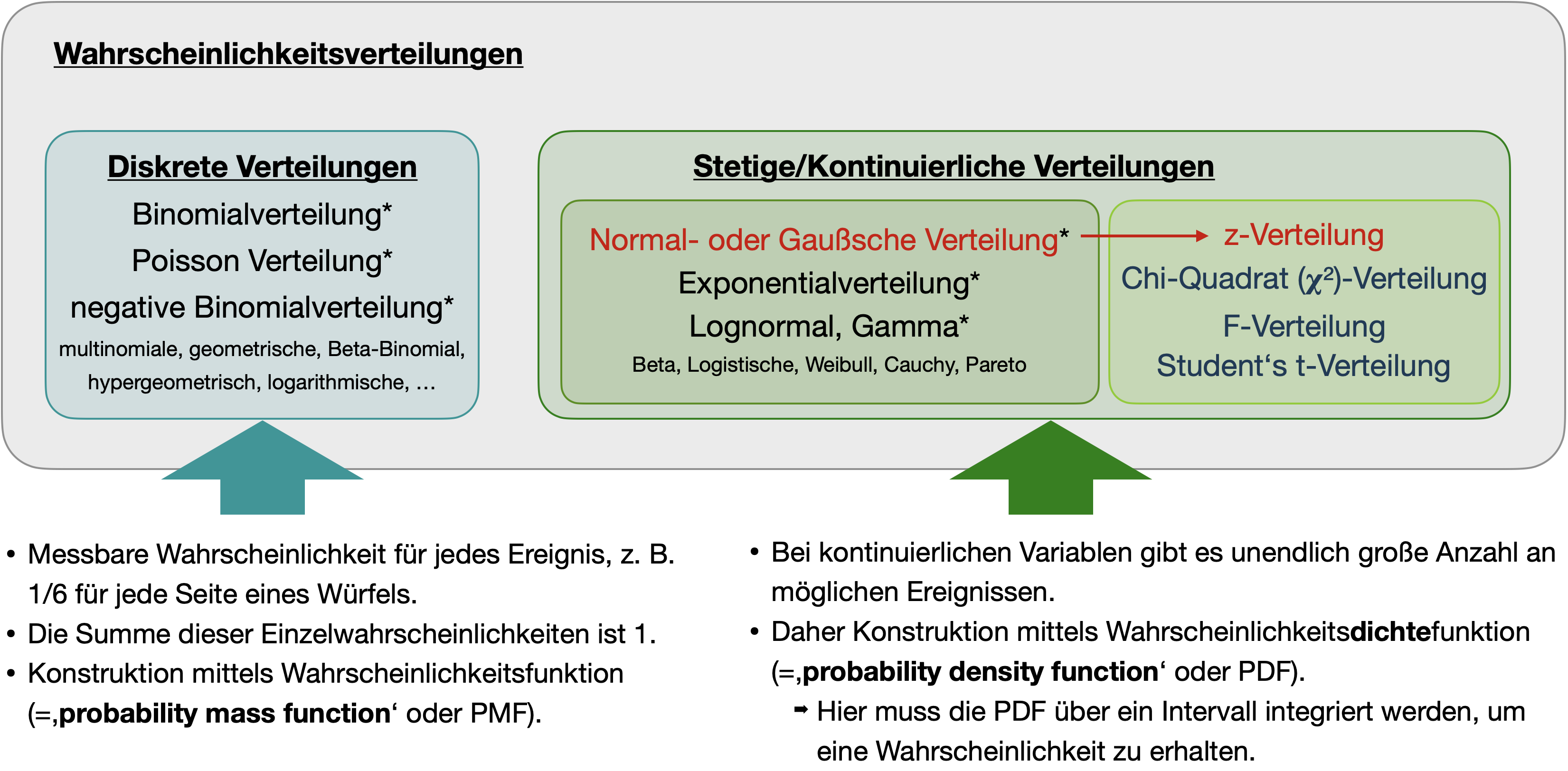
Übersicht wichtiger Wahrscheinlichkeitsverteilungen
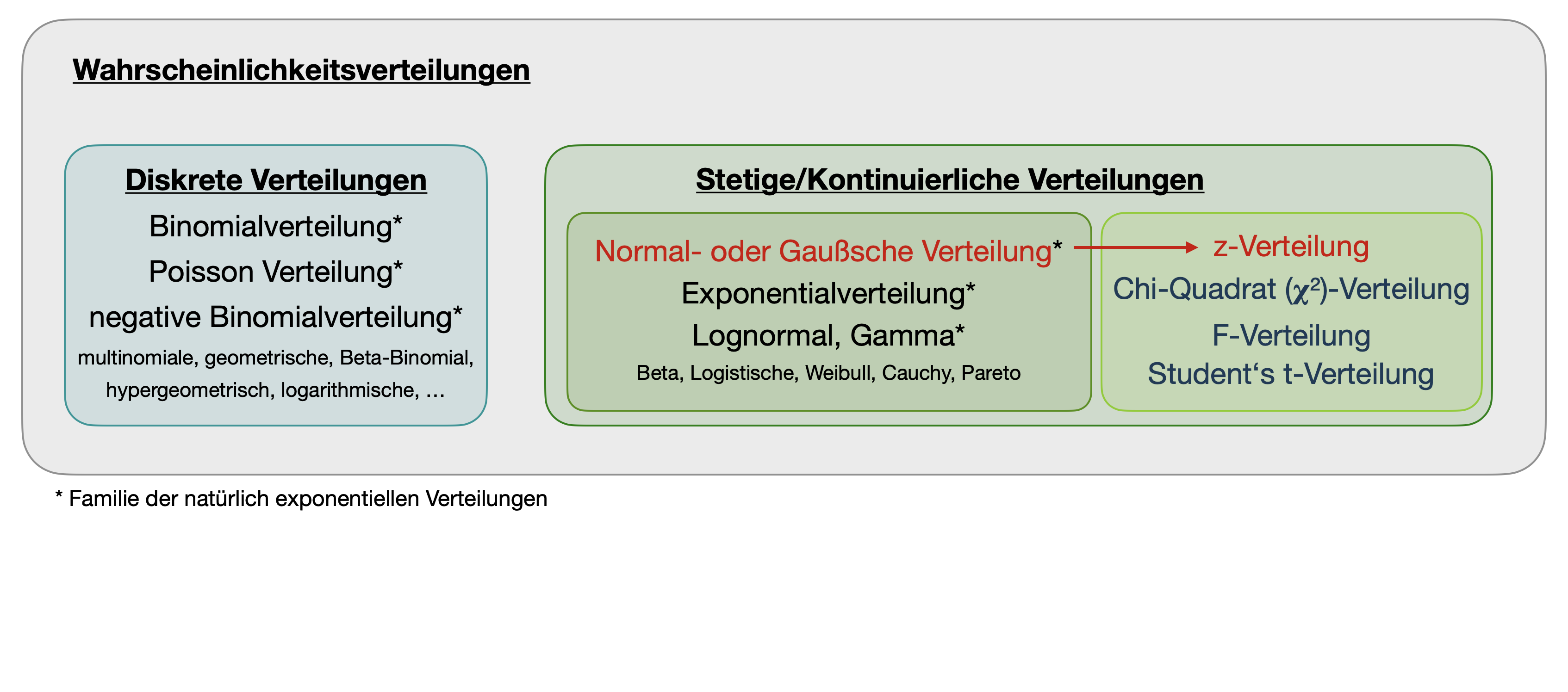
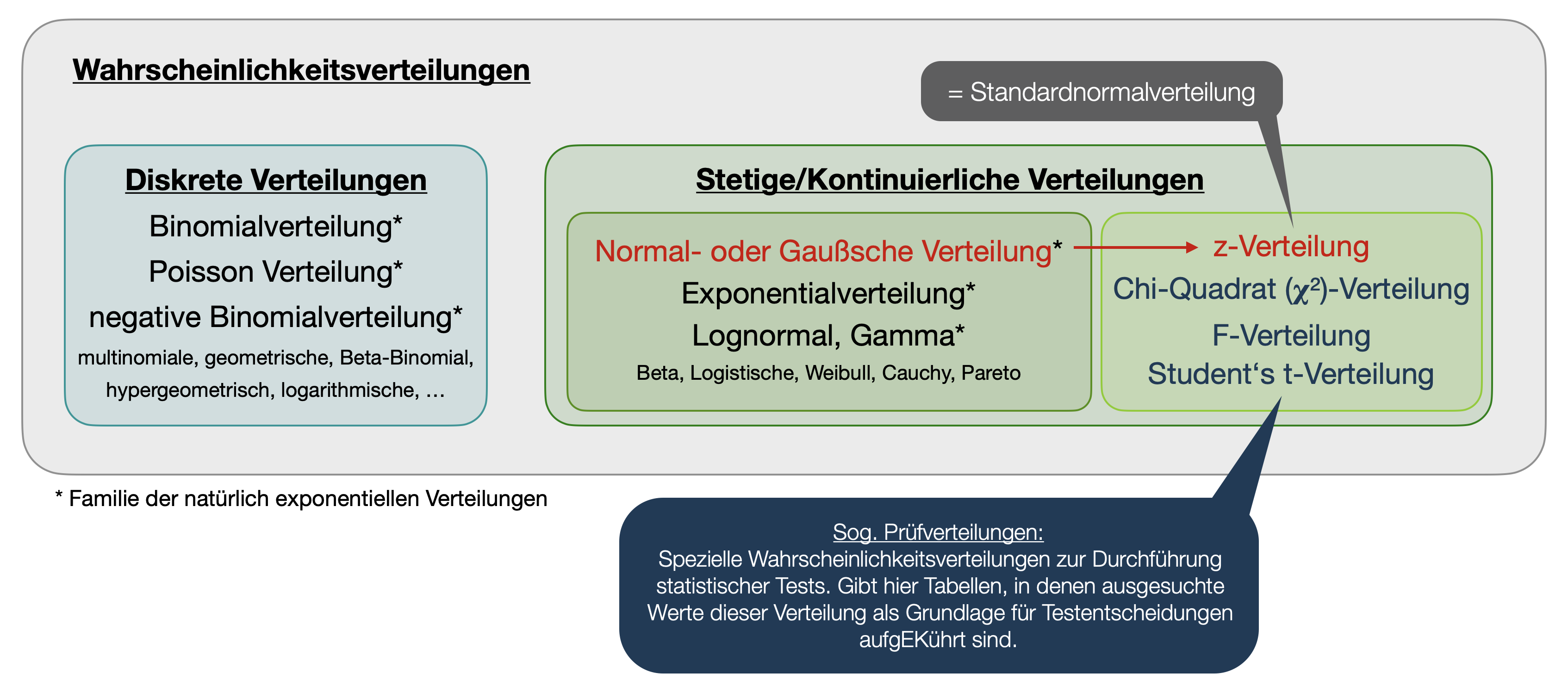
PMF vs. PDF
4 Verteilungen im Vergleich
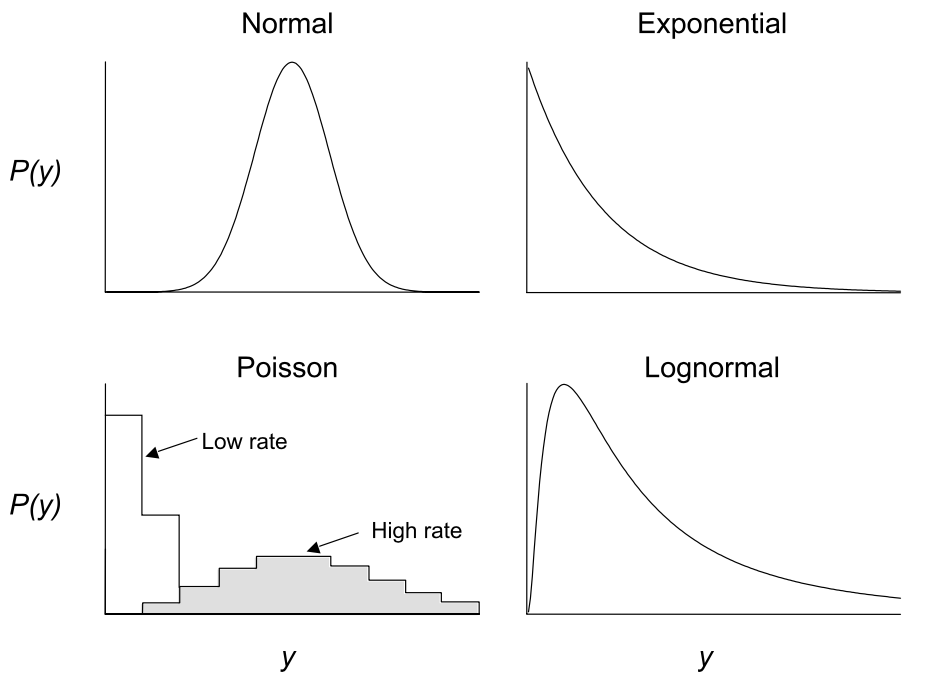
Bildquelle: Quinn & Keough (2002)
Experimentieren Sie selbst…
![]()
Bei welcher Stichprobengröße scheinen die Verteilungen stabil zu werden?
Link zur Shiny App: teaching-stats/distributions/distributions/
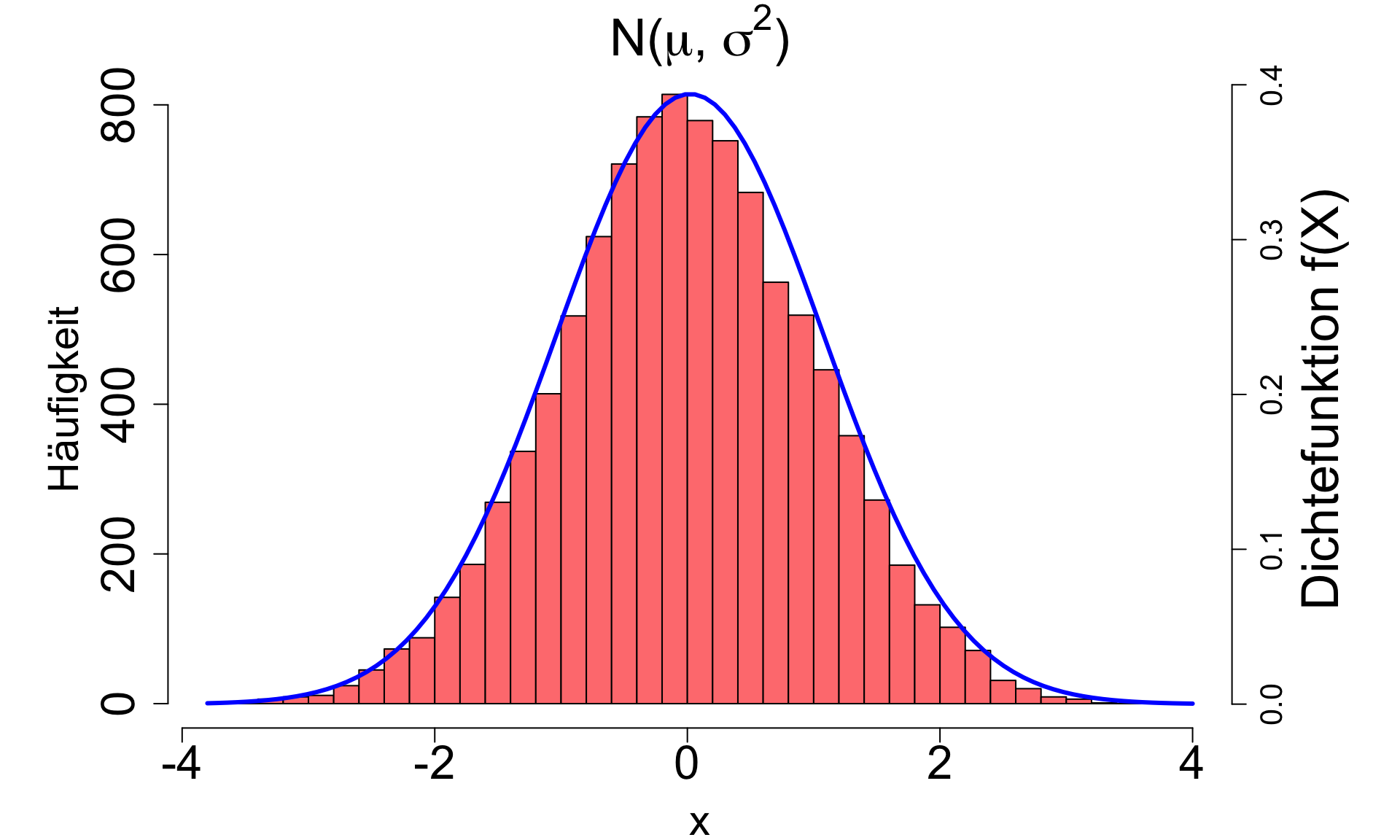
Die (Standard)Normalverteilung
Wichtigste Wahrscheinlichkeitsverteilung | 1
![]()
Hat 3 Eigenschaften
- Kontinuierliche, symmetrische Verteilung mit mehr Werten in der Mitte als am Rand (tails) → typische Glockenform (bell shape). Spannweite von -∞ bis +∞.
- Die Schiefe (skewness) ist null, da die Verteilung symmetrisch um den Mittelwert liegt.
- Zwei Parameter spezifizieren die Normalverteilung: Mittelwert und Varianz
Wichtigste Wahrscheinlichkeitsverteilung | 2
Gauß-Funktion (=PDF)
- Normalverteilungen sind durch folgende Formel beschrieben:
X \sim N(\mu_x, \sigma_x^2)
f(X)=\frac{1}{\sqrt{2\pi\sigma_x^2}}e^\frac{-(X-\mu_x)^2}{2\sigma_x^2}
- Beispiel: Mittelwert = 1, Varianz = 2
X \sim N(1, 2)
f(X)=\frac{1}{\sqrt{4\pi}}e^\frac{-(X-1)^2}{4}
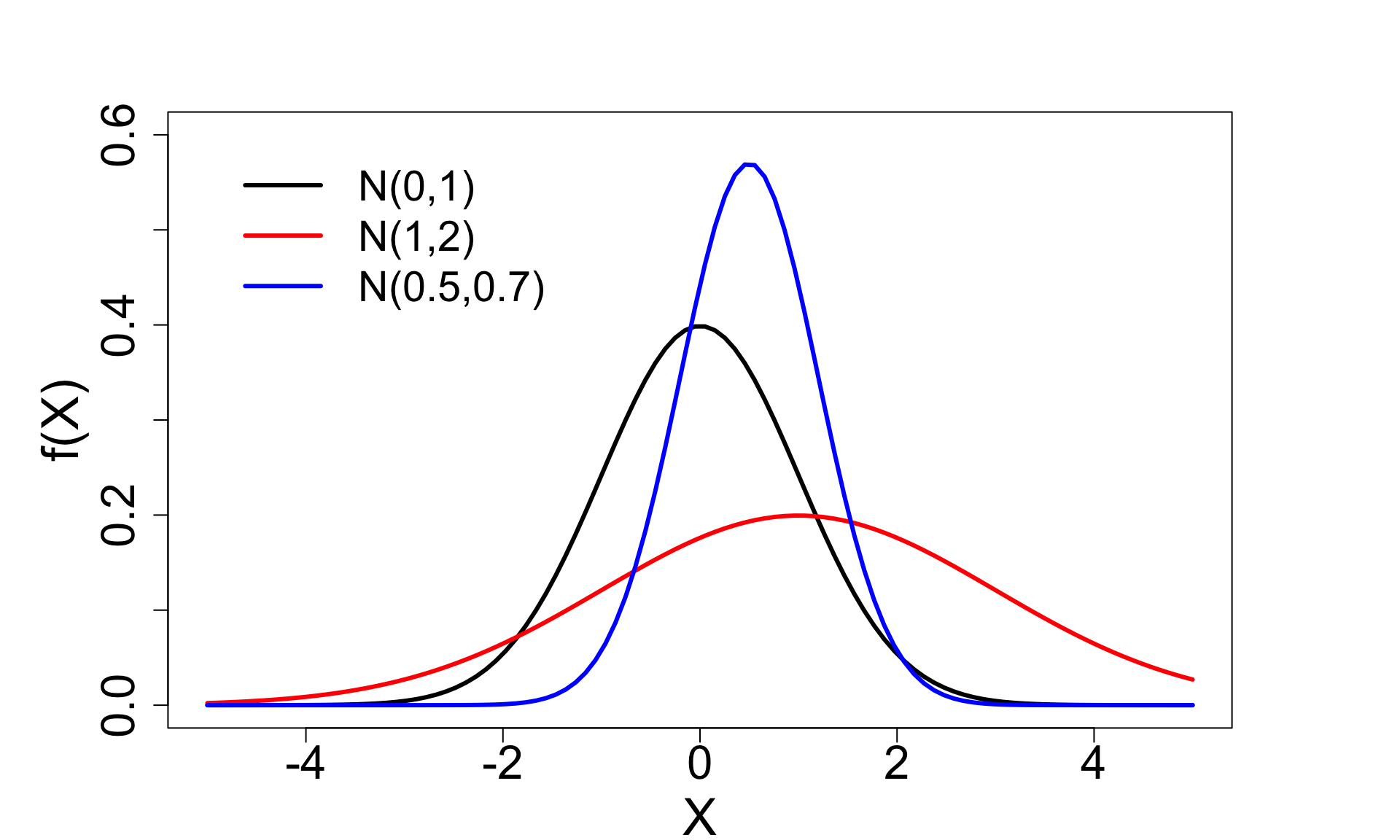
→ Erhöhen wir \mu, rücken wir die Kurve nach rechts.
→ Erhöhen wir \sigma^2 wird die Kurve flacher, verringern wir \sigma^2 wird die Kurve steiler.
Z-Transformation | Vorteil

Ein weiterer Vorteil der Z-Transformation (auch Standardisierung oder Normalisierung genannt):
- Sie überführt Werte, die mit unterschiedlichen Messinstrumenten erhoben wurden, in eine neue gemeinsame Einheit: in Standardabweichungs-Einheiten.
- Biologische und chemisch-physikalische Variablen können jetzt direkt verglichen werden.
Z-Transformation | Beispiel Kronblattlänge im iris Datensatz
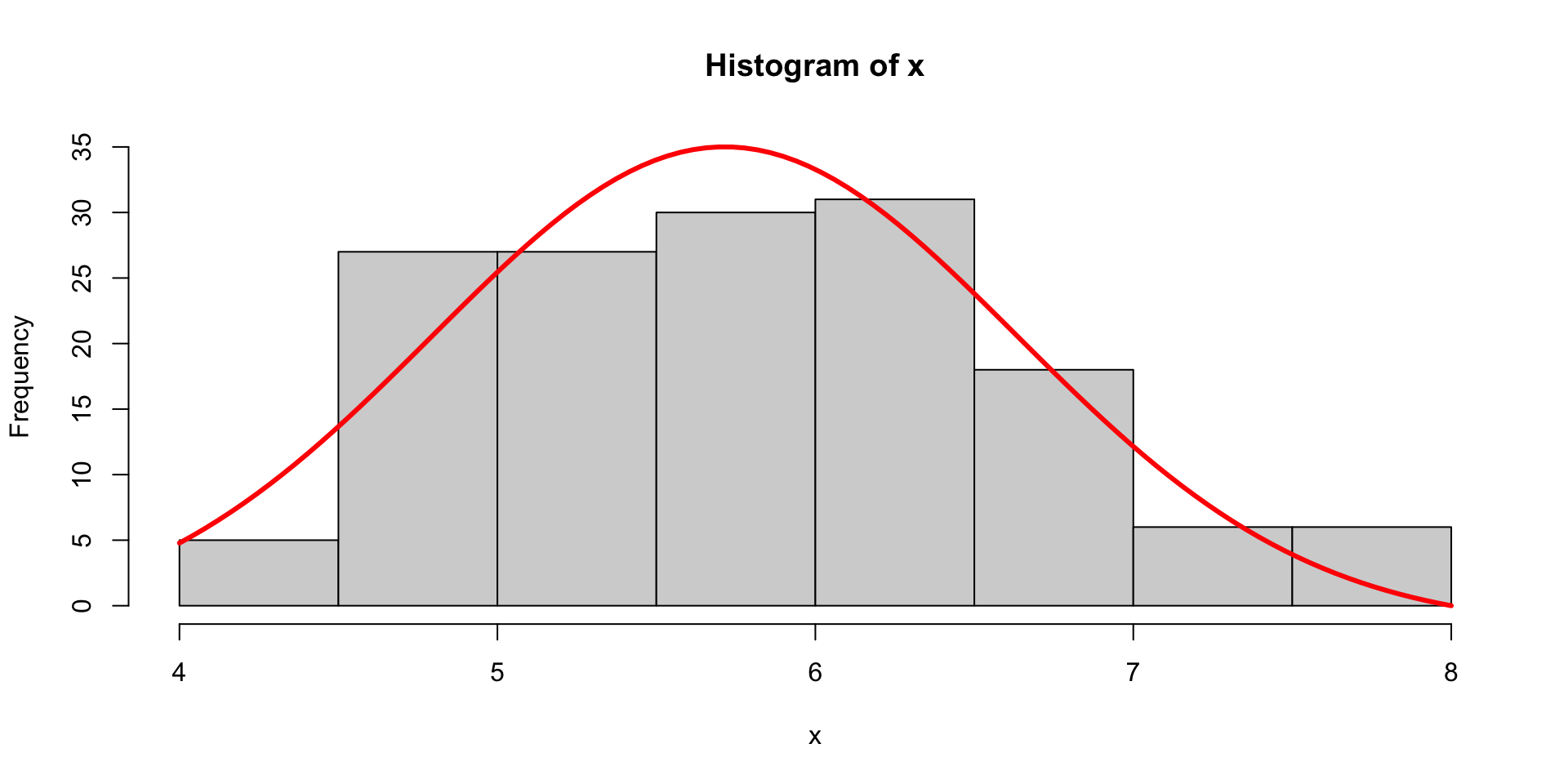
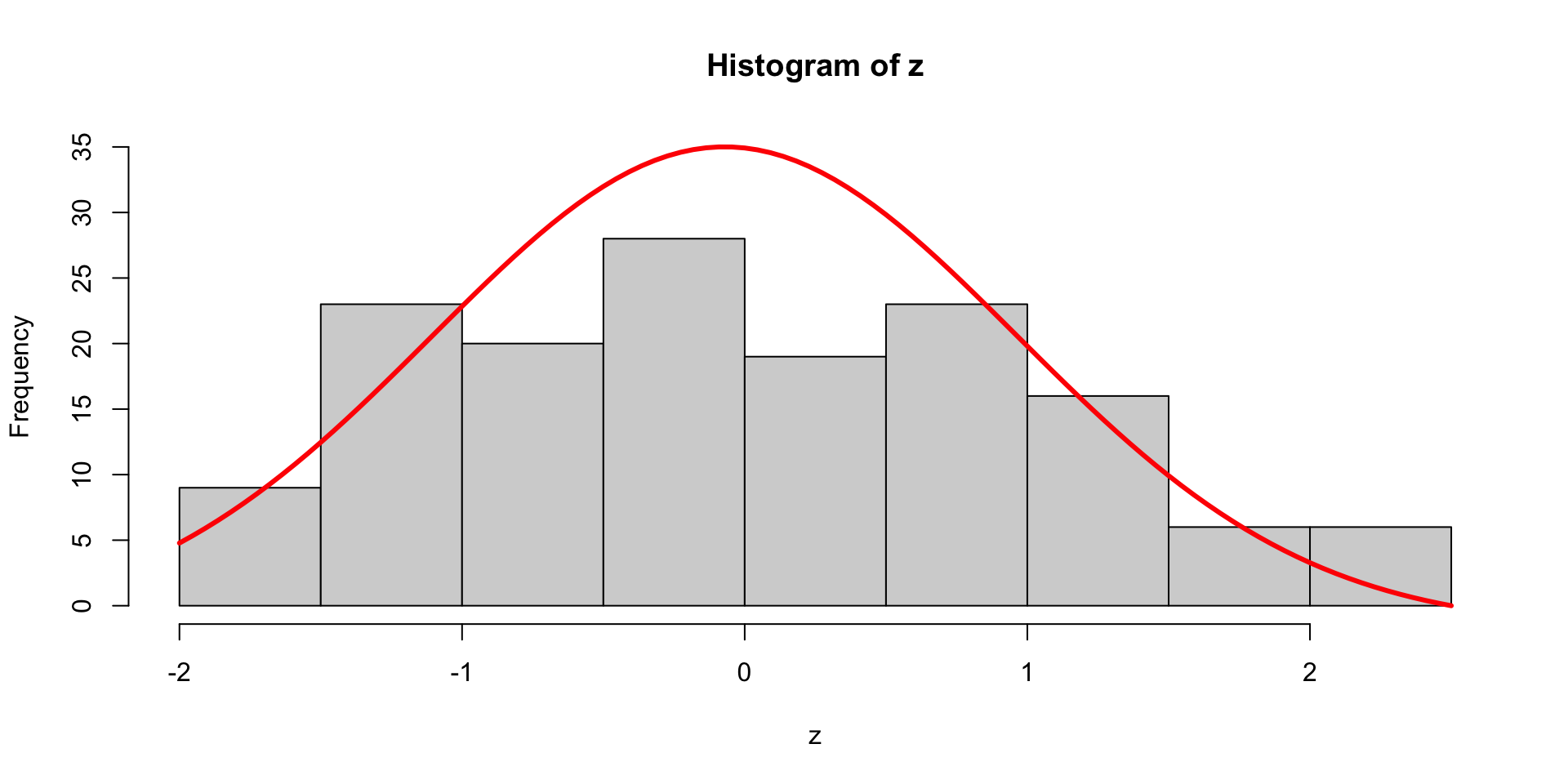
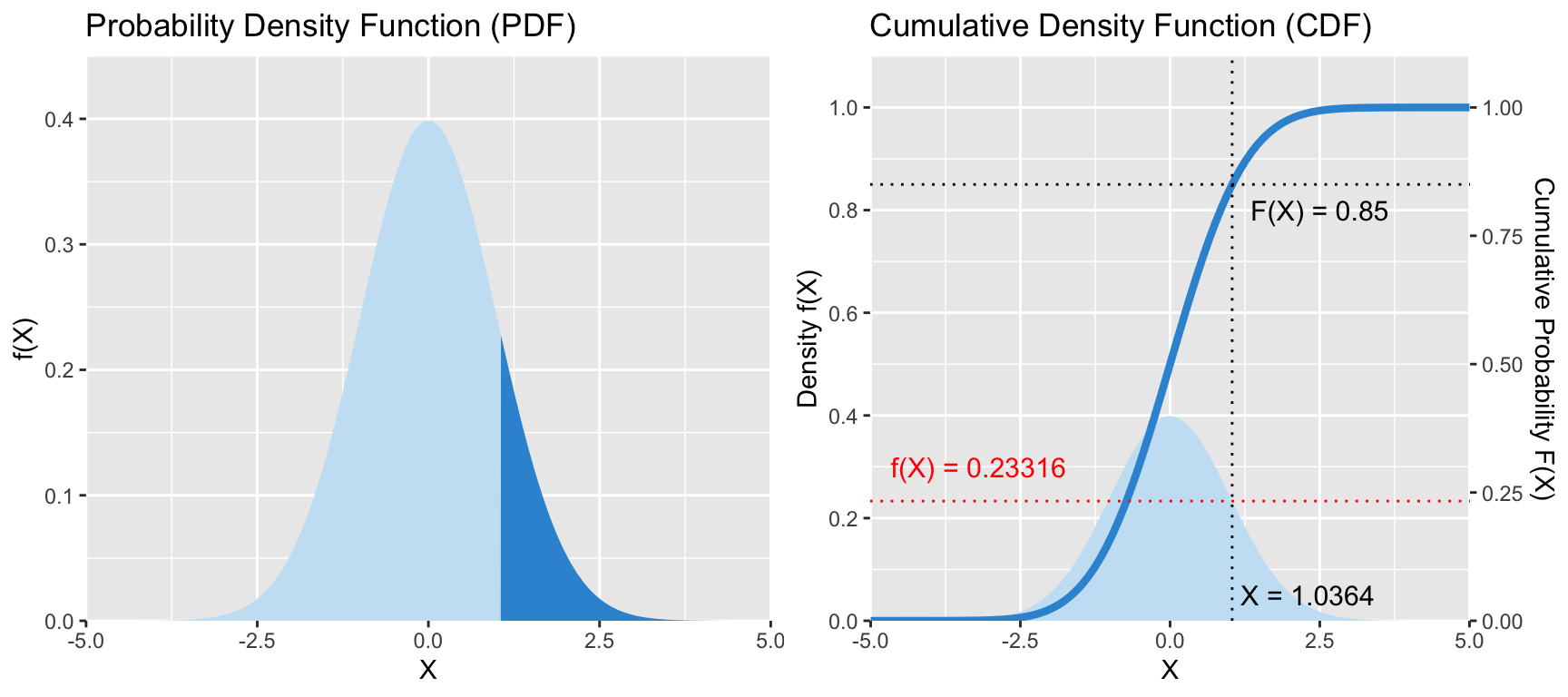
Die Verteilungsfunktion oder CDF | Beispiel
Wie groß muss X sein, damit 85% aller Werte darunter liegen?
Oder anders gefragt: Wie groß ist die Wahrscheinlichkeit, dass X ≤ 1.0364 ist?
CDF
Die CDF ist eine S-förmige Kurve, die für jeden Wert von x die Wahrscheinlichkeit anzeigt, einen Stichprobenwert zu erhalten, der kleiner oder gleich x ist.
Die PDF repräsentiert die Steigung dieser Kurve (ihre “Ableitung”), welche niemals negativ ist. Die Steigung beginnt sehr flach (bei der Standardnormalverteilung bis etwa -2), steigt dann an bis zu einem Maximalwert (hier bei x = 0), wird dann flacher und oberhalb von x = +2 sogar sehr klein.
Streuintervalle | z-Tabelle
Aus einer Standardnormalverteilungs- tabelle kann abgelesen werden, dass bei normalverteilten Zufallsvariablen jeweils ungefähr
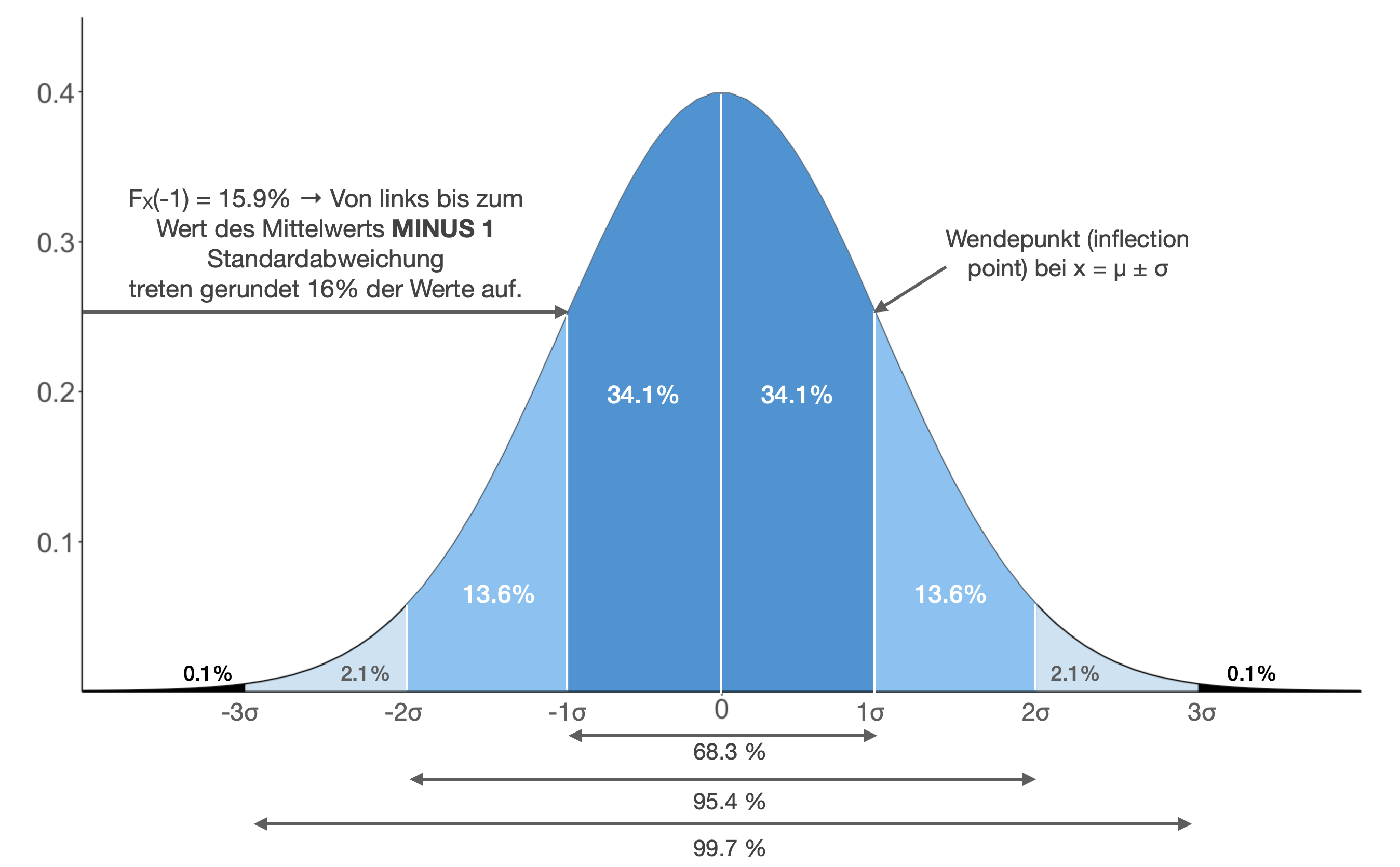
- 68.3 % der Realisierungen im Intervall \mu \pm \sigma,
- 95.4 % im Intervall \mu \pm 2\sigma und
- 99.7 % im Intervall \mu \pm 3\sigma liegen.
- 95% liegen zwischen \pm1.96\sigma und
99% zwischen \pm2.58\sigma- Beide Werte werden traditionell in Signifikanztest verwendet.
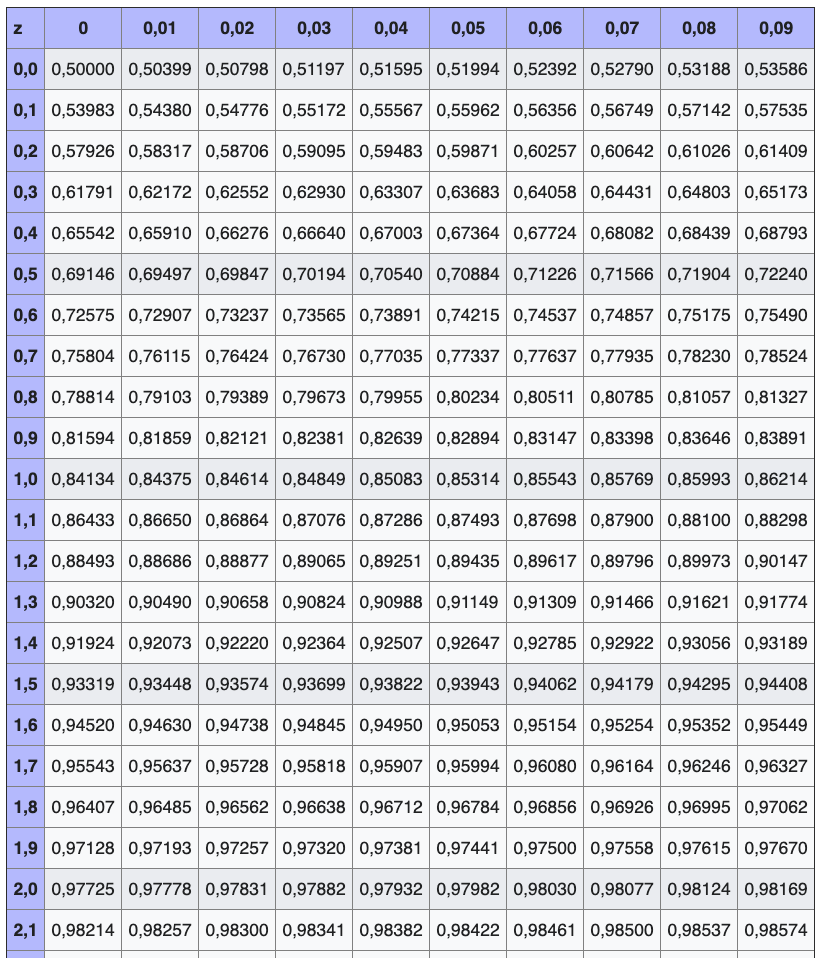
Quelle der Tabelle: Wikipedia
Streuintervalle | Grafisch
Die Normalverteilung in R
![]()

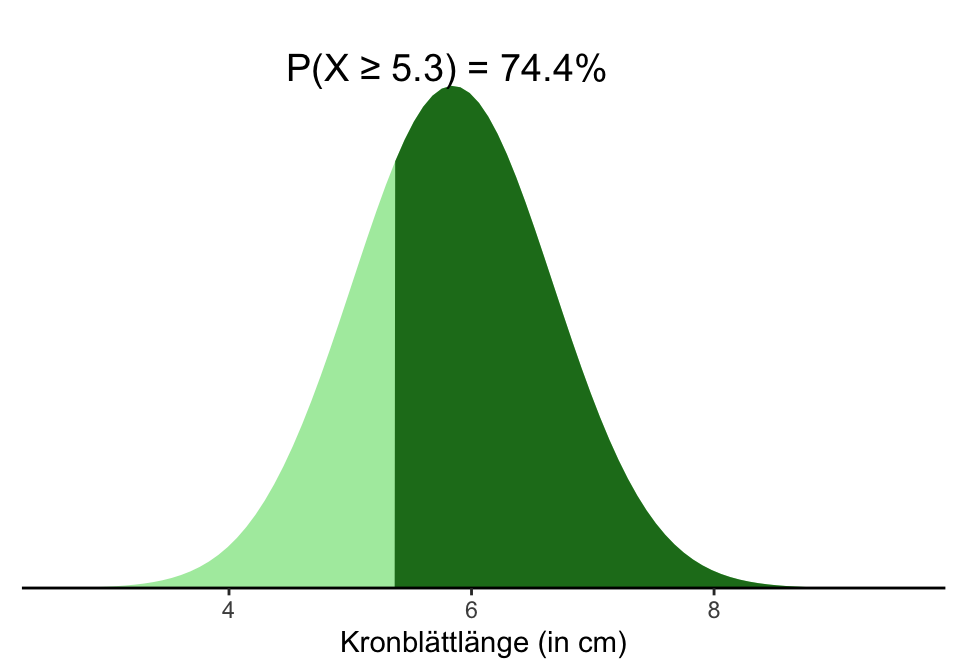
Die Normalverteilung in R | Beispiel 2 pnorm()
Iris Kronblattlänge
Und wie hoch ist die Wahrscheinlichkeit, dass eine zufällig ausgewählte Blume aus dem iris Datensatz eine Kronblattlänge von 5.3cm oder größer hat? Wir suchen also P(X ≥ 5.3):
Die Normalverteilung in R | Beispiel 3
Zurück zu folgendem Beispiel
- Wie groß ist die Wahrscheinlichkeit, dass X ≤ 1.0364 ist
- Wie groß muss X sein, damit 85% aller Werte darunter liegen?
- Wie hoch ist f_X(1.0364)?
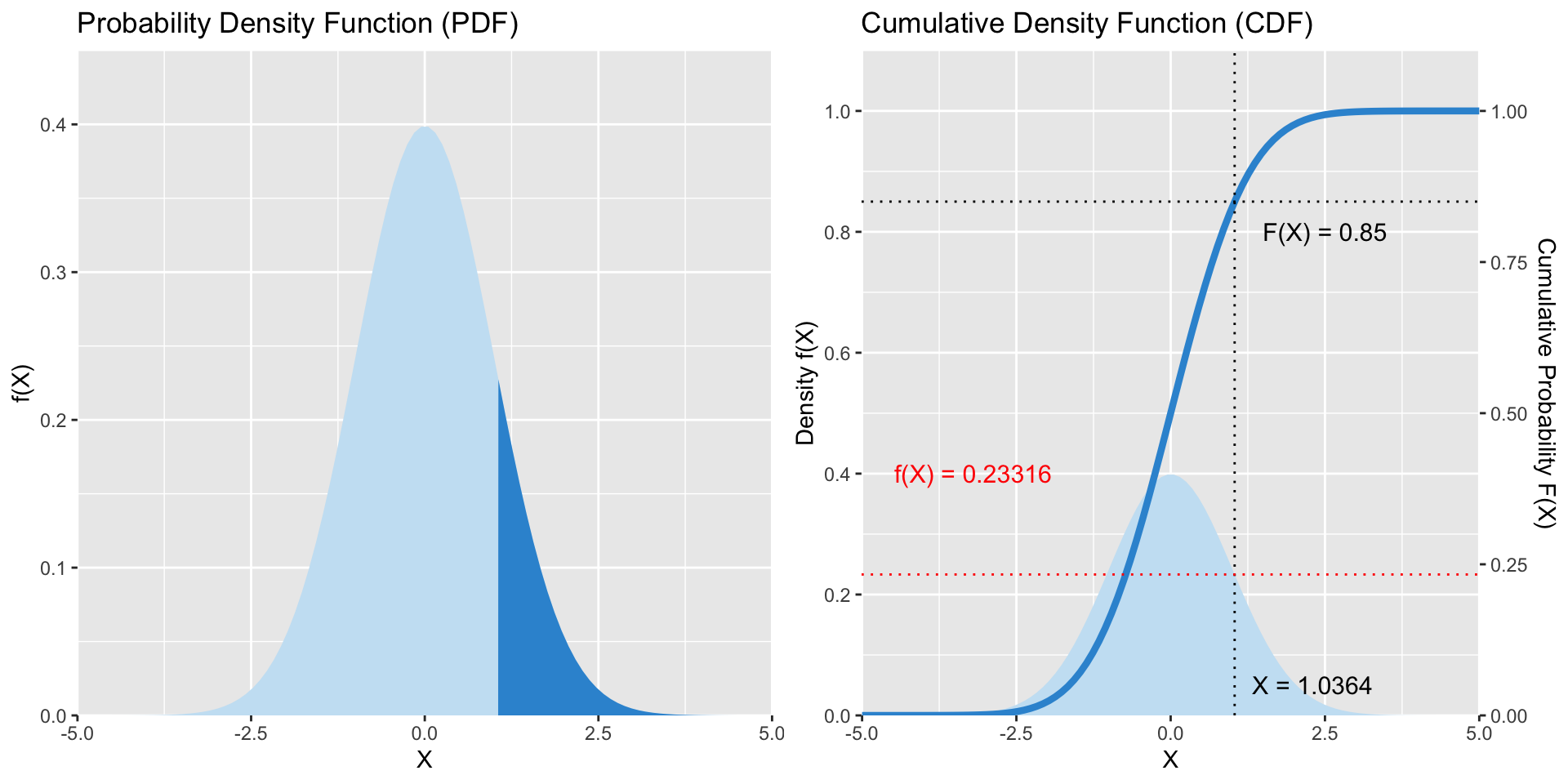
[1] 0.85[1] 1.04[1] "1.0364"[1] 0.233Der zentrale Grenzwertsatz (‘Central Limit Theorem’)
Definition
![]()
Zentraler Grenzwertsatz - zentrales Grenzwerttheorem
- Mit wachsendem Stichprobenumfang (n) nähert sich die Stichprobenkennverteilung (= Verteilung von Stichprobenkenngrößen wie Mittelwert) an die Normalverteilung, unabhängig von der Form der Populationsverteilung.
- Die Mittelwerte von Stichproben streuen um den Mittelwert ihrer Grundgesamtheit, je größer n desto geringer die Streuung.
- Ist die Grundgesamtheit bereits normalverteilt so ist die Streuung der Mittelwerte relativ gering.
- Der Standardfehler (die Standardabweichung der Stichprobenmittelwerte) nähert sich mit hohen n der Standardabweichung der Grundgesamtheit geteilt durch die Quadratwurzel des Stichprobenumfangs.
Demonstration | Shiny App
![]()
Prüfverteilungen stetiger Variablen
Student’s t-Verteilung


Name stammt von William Sealey Gosset ab
(unter Pseudonym Student 1908 veröffentlicht).

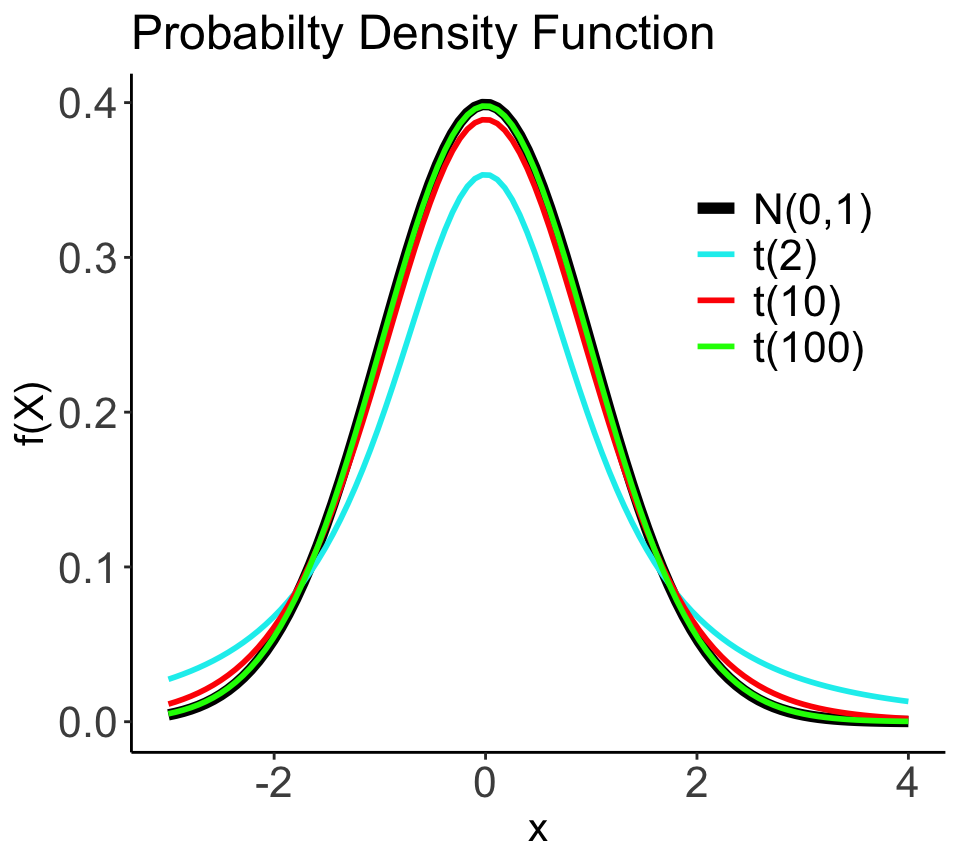
Student’s t-Verteilung | Eigenschaften
X ~ t(FG)
- Wie Standardnormalverteilung, nur etwas flacher (heavy-tailed) → kritische Werte sind hier größer!
- 1 Parameter (=Freiheitsgrad: n-1) der die Kurvenform bestimmt → mit wachsendem FG nähert sie sich einer Standardnormalverteilung.
- Verwendung für
- Konfidenzintervalle einzelner Parameter (z.B. Mittelwerte)
- Hypothesentest (t-Tests): Lineare Regression und Vergleich zweier Gruppenmittelwerte
Student’s t-Verteilung | Simulation
Empirischer Vergleich der Z-Verteilung vs. t-Verteilung
Code
calc_z_t <- function(n = 10, rep = 1000,
mu = 10, sigma = 1) {
z <- numeric(length = rep)
t <- numeric(length = rep)
for(i in 1:rep) {
x <- rnorm(n, mean = mu, sd = sigma)
x_m <- mean(x)
x_sd <- sd(x)
# z-score
z[i] <- (x_m-mu) / (sigma/sqrt(n))
# t-score
t[i] <- (x_m-mu) / (x_sd/sqrt(n))
}
out <- list(z = z, t = t)
return(out)
}
set.seed(321)
run_3 <- calc_z_t(n = 3)
run_5 <- calc_z_t(n = 5)
run_10 <- calc_z_t(n = 10)
run_30 <- calc_z_t(n = 30)
par(mfrow = c(2,4))
hist(run_3$z, breaks = 20, xlab = "x", main = "Z (n = 2)", xlim = c(-10,10))
hist(run_5$z, breaks = 20, xlab = "x", main = "Z (n = 5)", xlim = c(-10,10))
hist(run_10$z, breaks = 20, xlab = "x", main = "Z (n = 10)", xlim = c(-10,10))
hist(run_30$z, breaks = 20, xlab = "x", main = "Z (n = 30)", xlim = c(-10,10))
hist(run_3$t, breaks = 50, xlab = "x", main = "t (n = 2)", xlim = c(-10,10))
hist(run_5$t, breaks = 20, xlab = "x", main = "t (n = 5)", xlim = c(-10,10))
hist(run_10$t, breaks = 20, xlab = "x", main = "t (n = 10)", xlim = c(-10,10))
hist(run_30$t, breaks = 20, xlab = "x", main = "t (n = 30)", xlim = c(-10,10))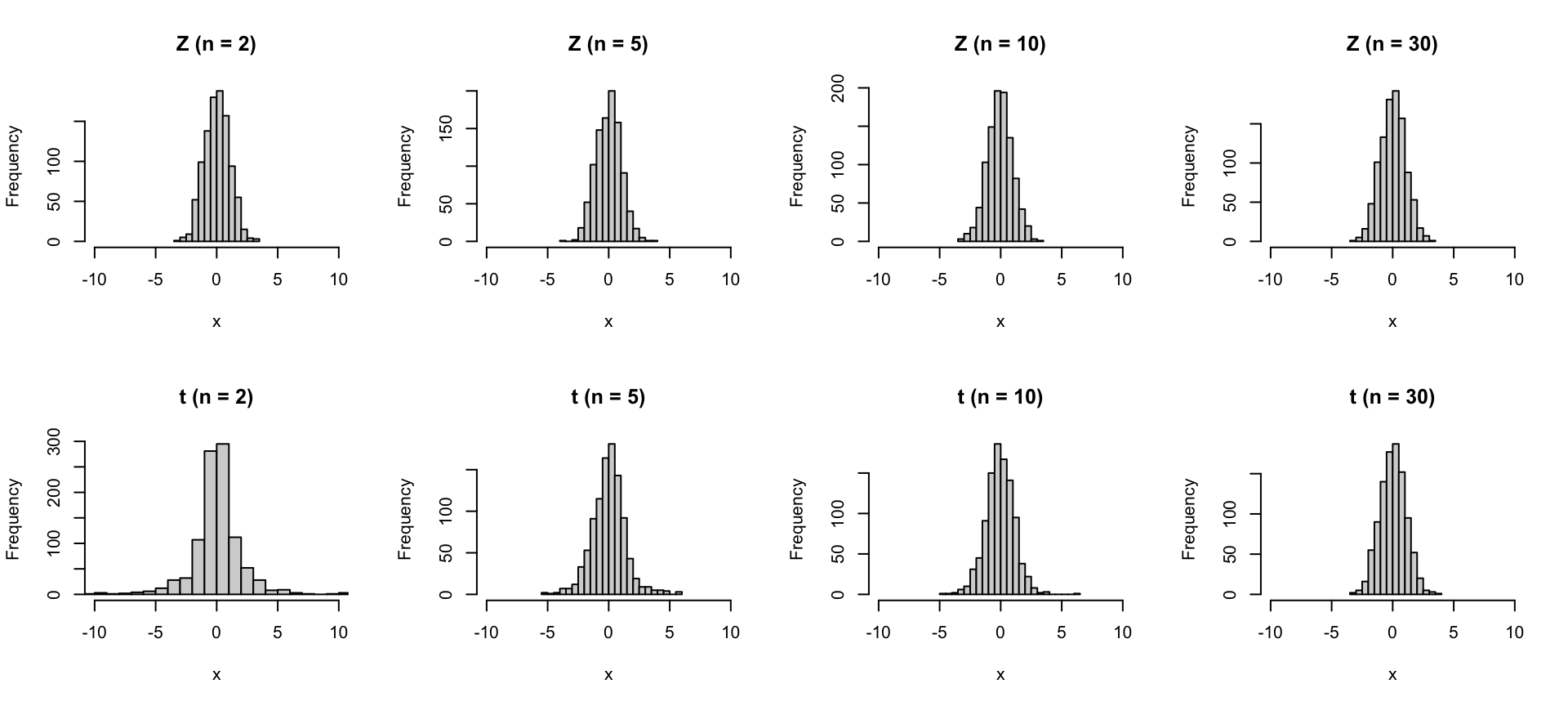
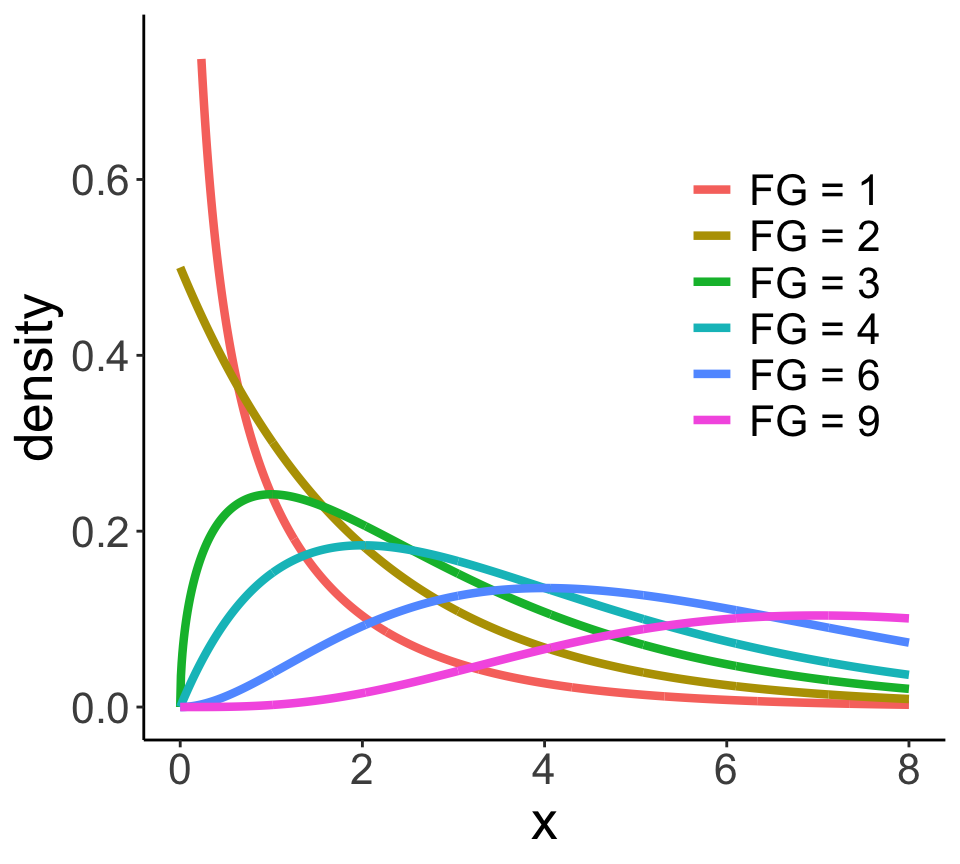
Chi-Quadrat-Verteilung
Eigenschaften
- Stetig, asymmetrisch und immer positiv.
- 1 Parameter (=Freiheitsgrad: n-1) der die Kurvenform bestimmt.
- Mittelwert = Anzahl an Freiheitsgraden (n-1), die Varianz = 2*(n-1)
- Verwendung bei
- Schätzung von Verteilungsparametern (z.B. Varianz)
- Beschreibung der Summe unabhängiger quadrierter standardnormalverteilter Zufallsvariablen
- Zum Testen
- der Unterschiede zwischen Grundgesamtheiten und Probenvarianzen
- zwischen theoretischen und beobachteten Verteilungen (\chi^2-Test als Anpassungstest)
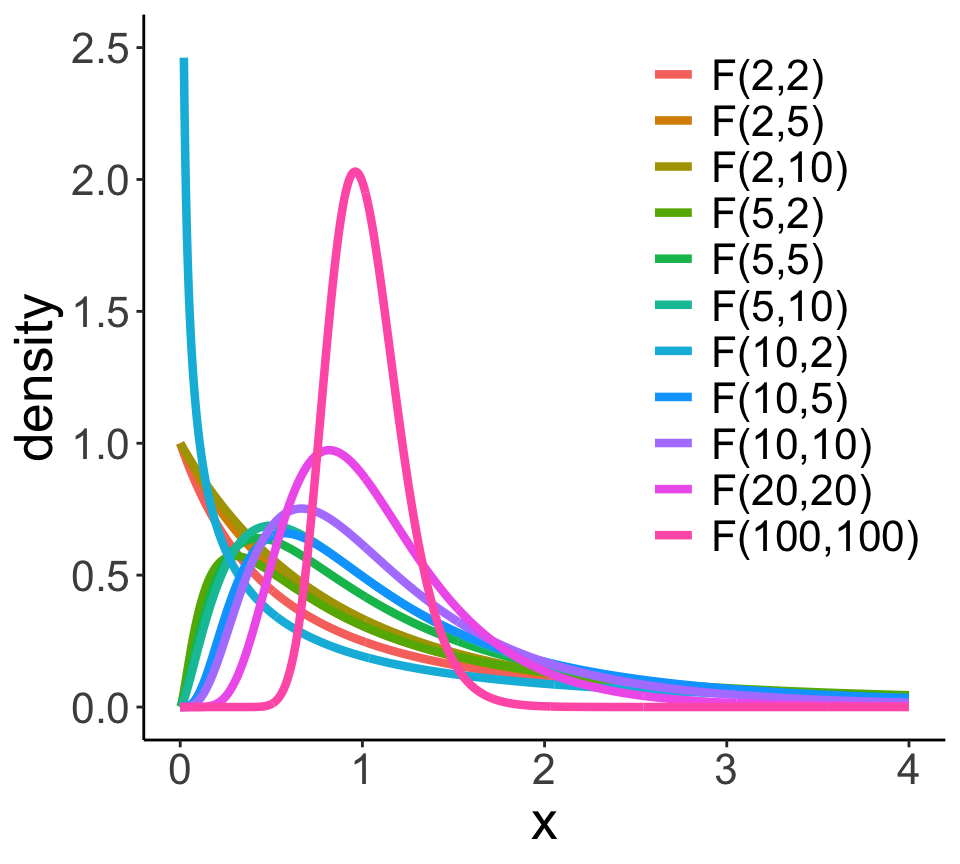
Fishers F-Verteilung
X ~ F(FG1, FG2)
- Verhältnis von zwei χ2-Verteilungen (z. B. zwei Varianzen)
- Wird zum Testen von Varianzverhältnissen in linearen Modellen verwendet.
- Besitzt 2 unabhängige Freiheitsgrade als Parameter
- Auch hier gilt, je nach Freiheitsgraden (d.h. Stichprobengröße) ist die Form der Kurve unterschiedlich.
Your turn …
![]()
Quiz 1 | Fragen
![]()
Nutzen Sie die Shiny App auf der nächsten Folie um folgende drei Fragen zu beantworten:
1. Normalverteilung
2. t-Verteilung
2. F-Verteilung
Quiz 2 | Zum Ausprobieren in R
![]()
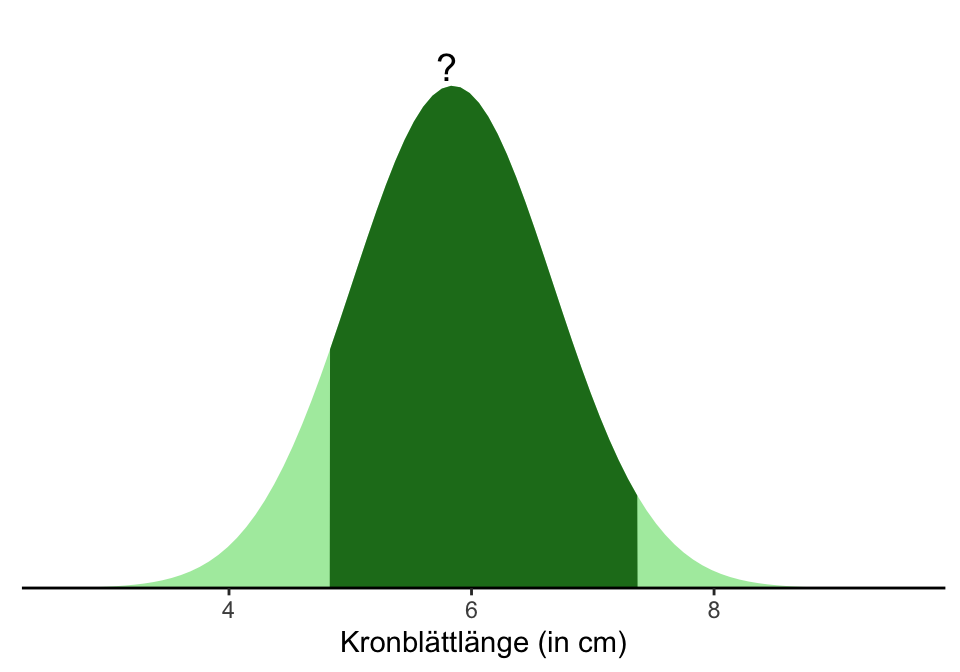
Wie hoch ist die Wahrscheinlichkeit, dass eine zufällig ausgewählte Blume aus dem iris Datensatz eine Kronblattlänge zwischen 4.8 und 7.4cm hat? Wir suchen also
P(4.8 < X \leq 7.4)= \int_{4.8}^{7.4} f_X(x)dx = P(X \leq 7.4) - P(X \leq 4.8)
{kind=link}
Übungsaufgaben
![]()
Vorbereitungsaufgabe für Übungstag 2
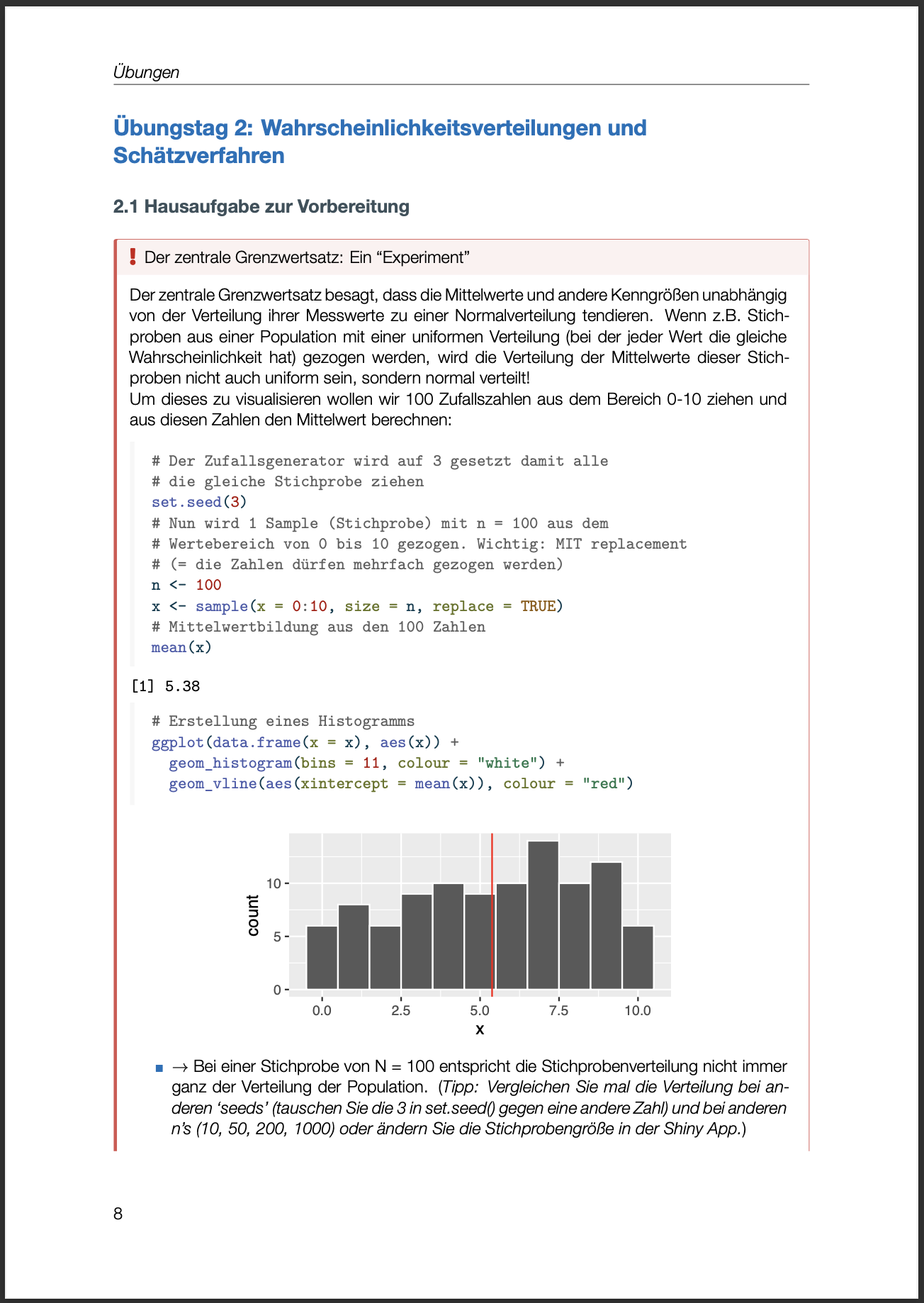
Was ist zu tun?
Eigene Simulationen zum zentralen Grenzwertsatz mithilfe der Shiny App durchführen → teaching-stats/clt/sample-means/
Wichtig
Moodle-Quiz VOR der nächsten Übung ausfüllen!
Abschlussquiz
![]()
Bei weiteren Fragen: saskia.otto(at)uni-hamburg.de

Diese Arbeit is lizenziert unter einer Creative Commons Attribution-ShareAlike 4.0 International License mit Ausnahme der entliehenen und mit Quellenangabe versehenen Abbildungen.