



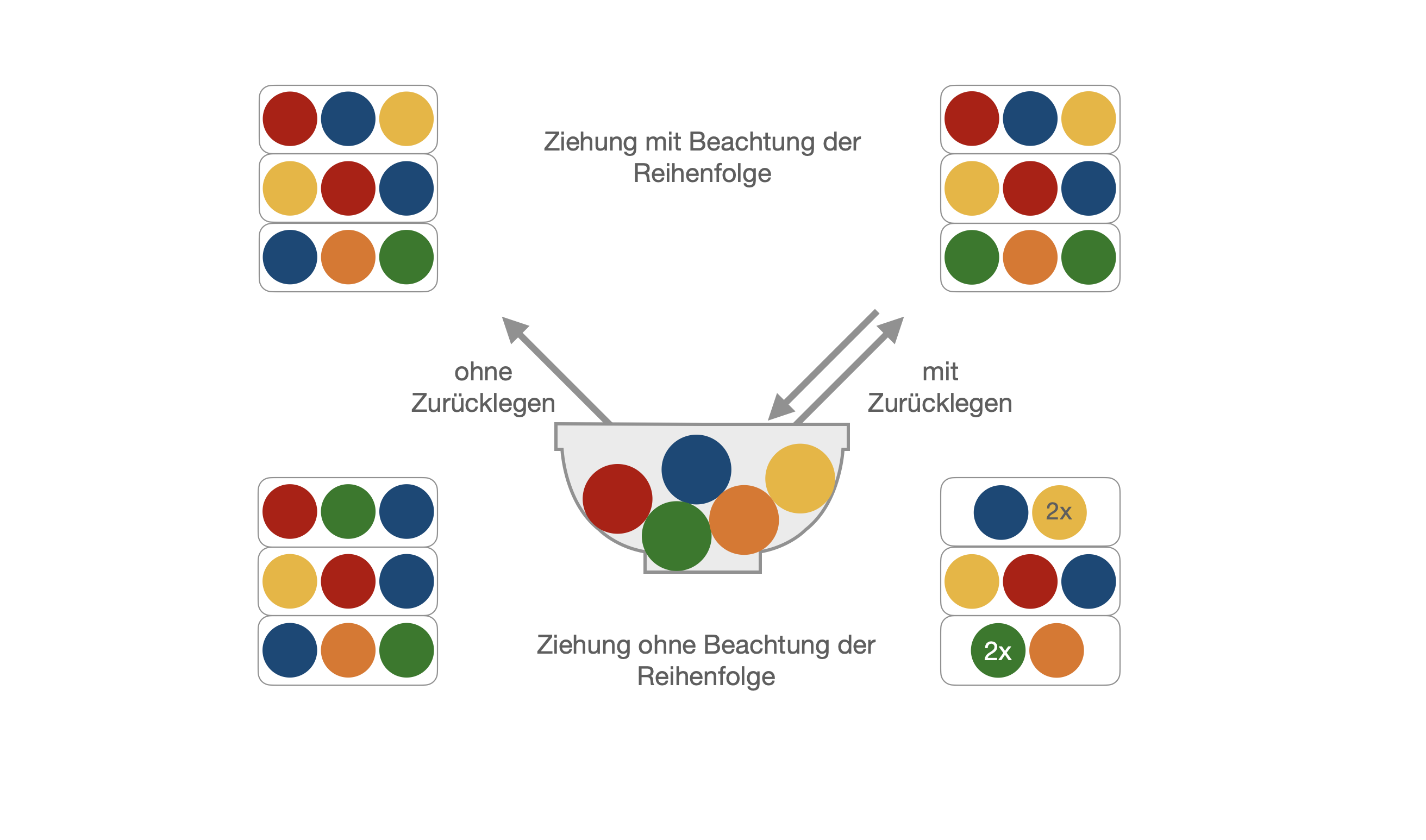
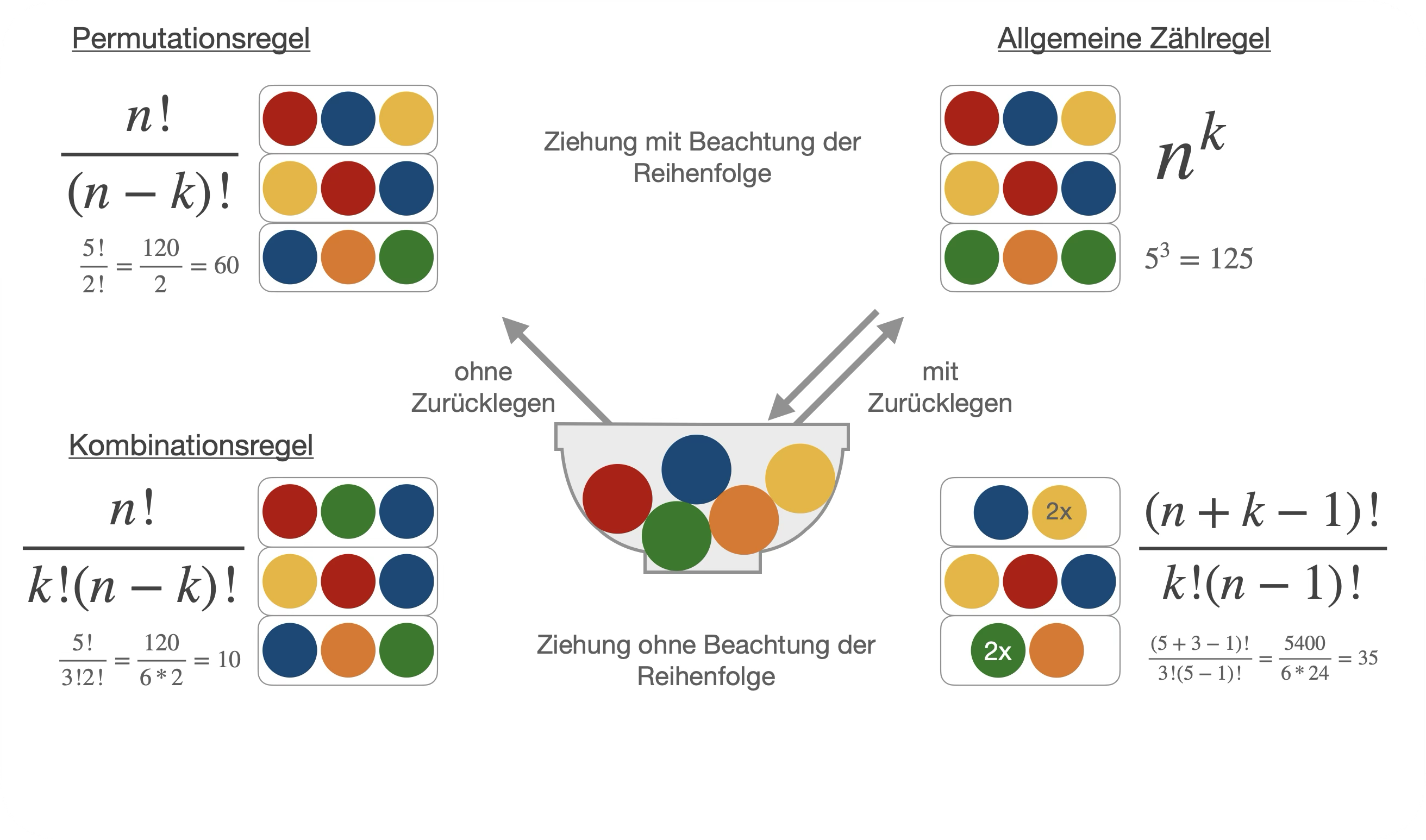
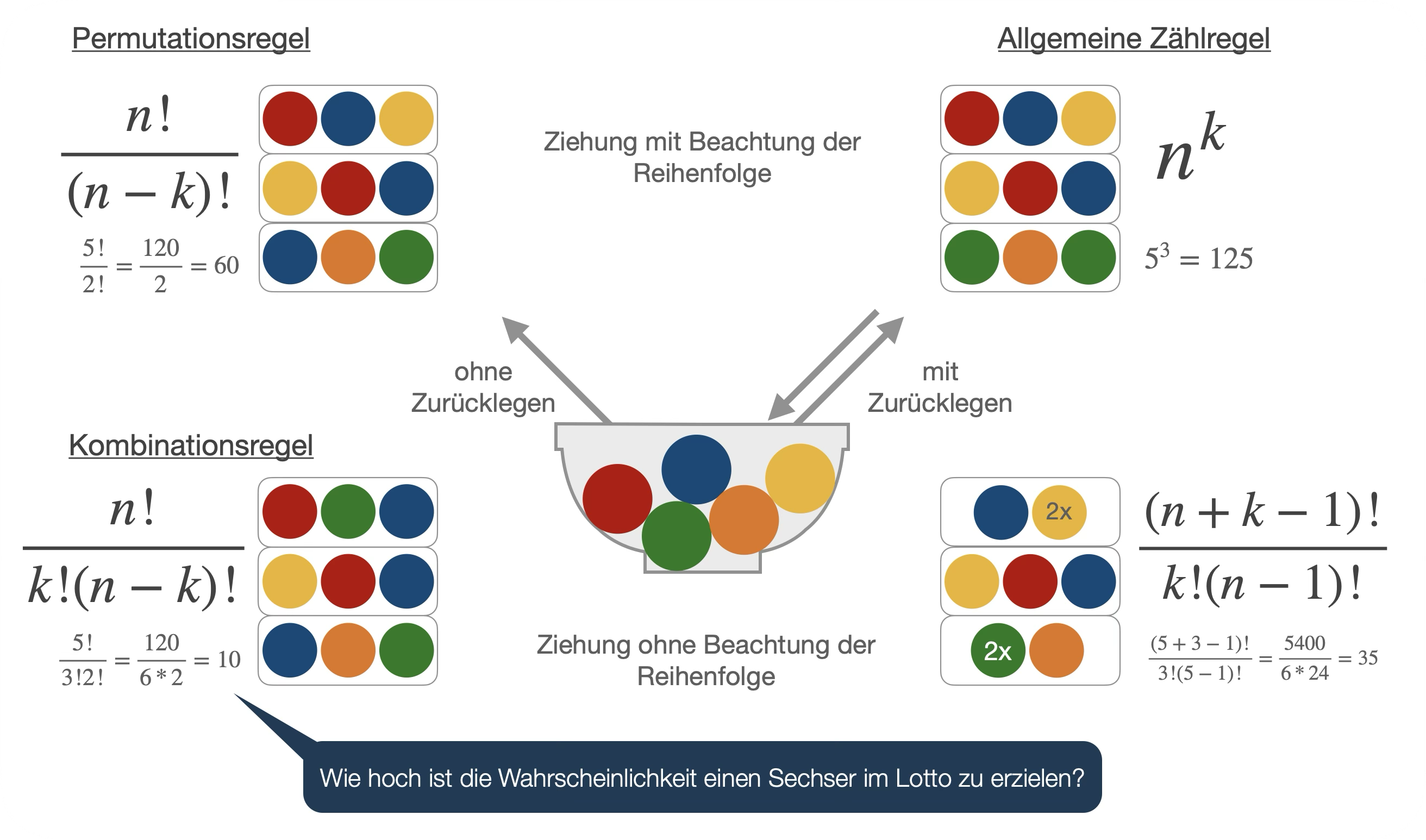


Funktion
calc_prob <- function(n = 100) {
# Erstellung leerer Vektoren
true9<- vector("logical", n)
true10 <- vector("logical", n)
# Schleife
for (i in 1:n) {
# '3-maliges Würfel'
sum3 <- sum(sample(1:6,3,replace = T))
# Ist die Summe 9 oder 10?
true9[i] <- ifelse(sum3 == 9, T, F)
true10[i] <- ifelse(sum3 == 10, T, F)
}
# Ausgabevektor: Anzahl Summe 9 bzw. 10
out <- c(
prob9 = round(sum(true9)/n, 4),
prob10 = round(sum(true10)/n, 4)
)
return(out)
}
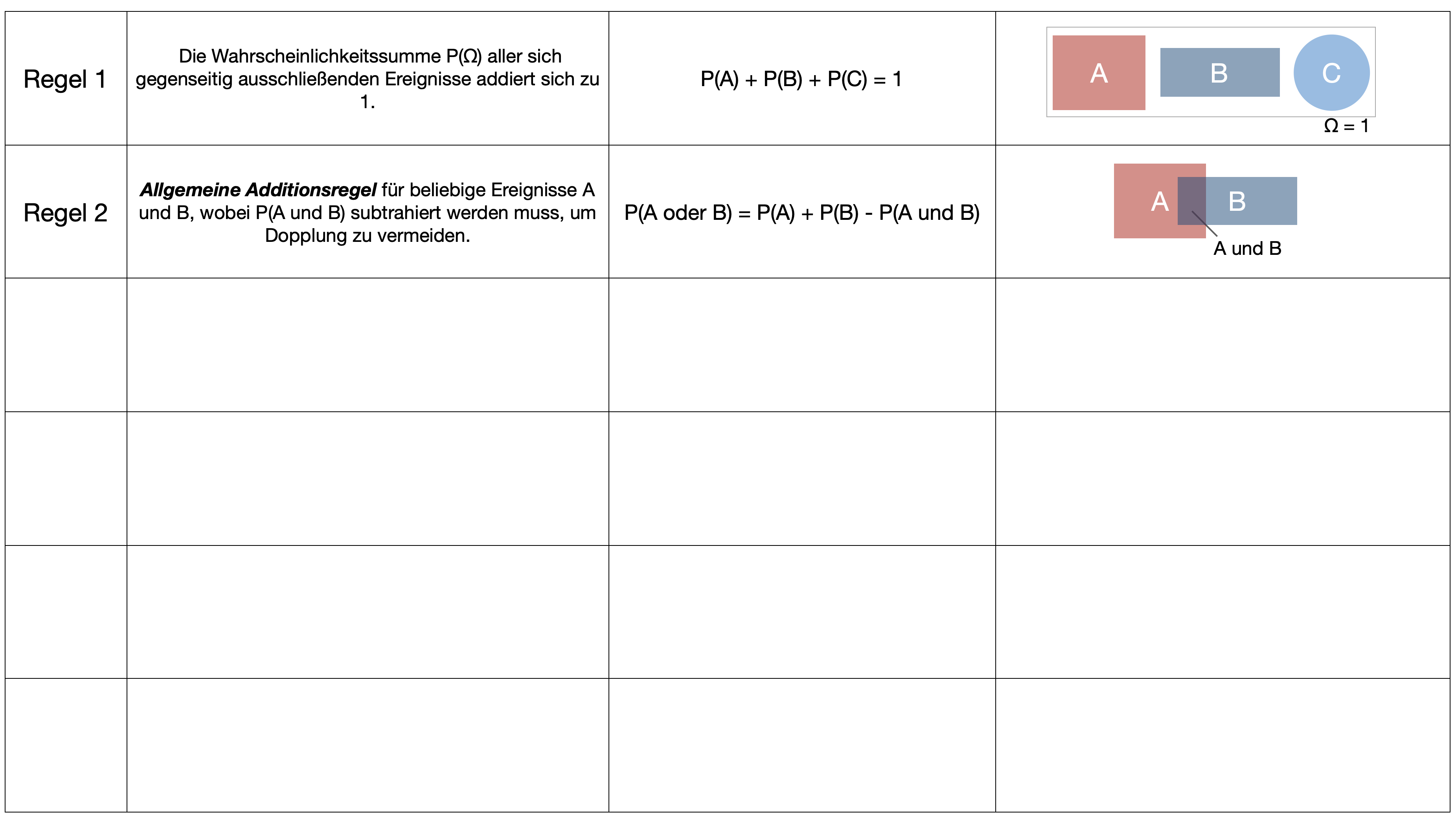
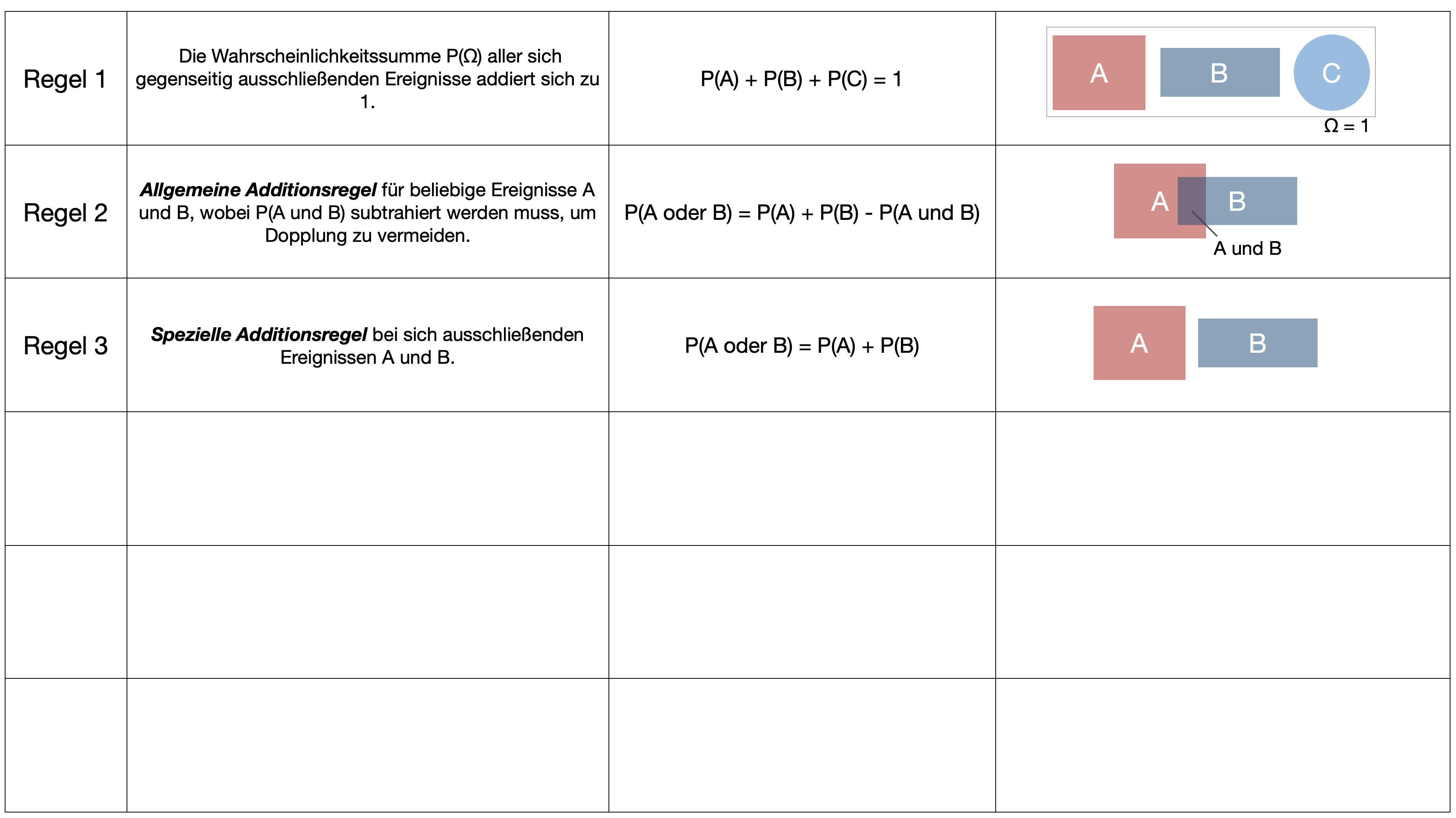
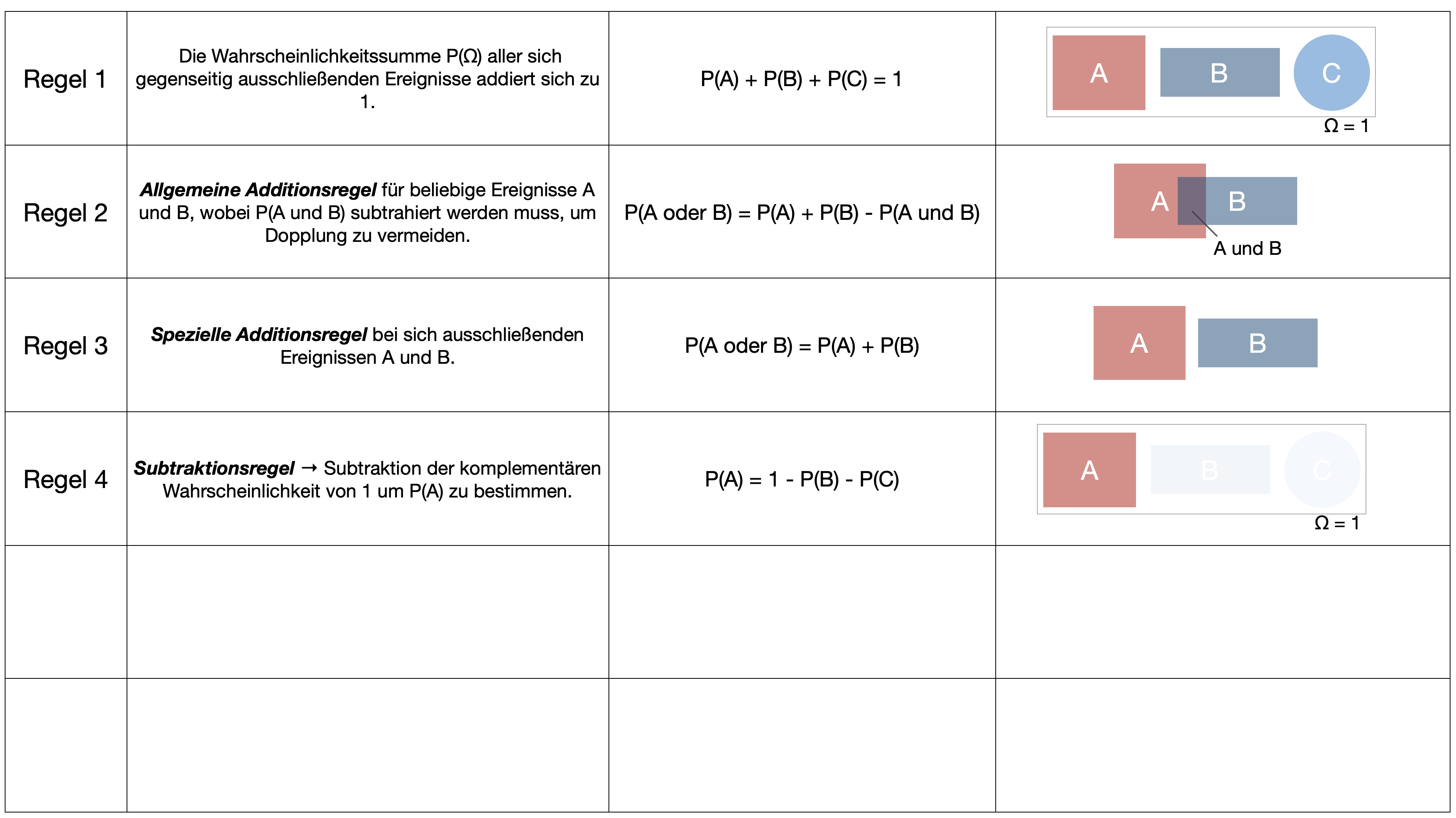
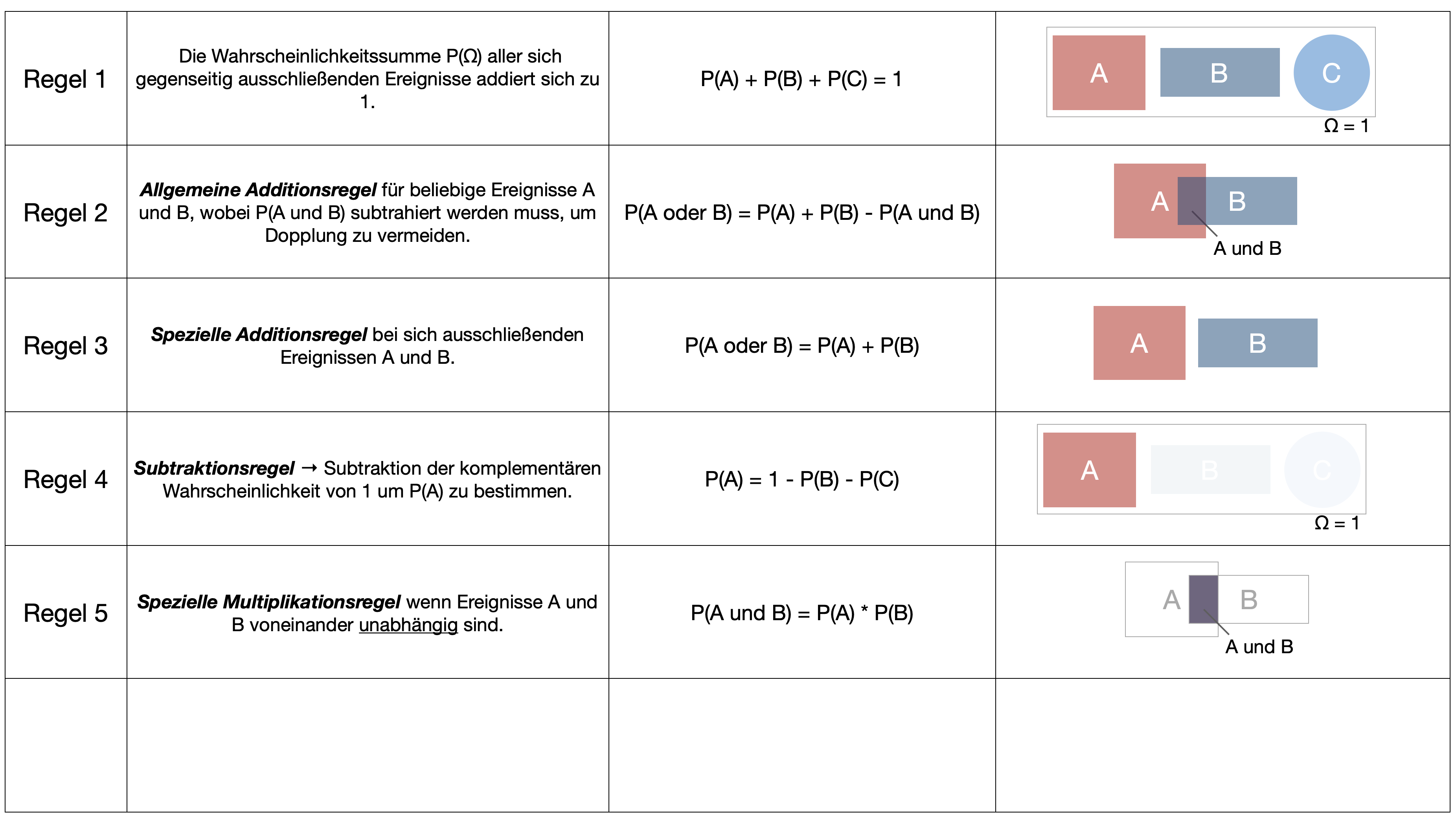
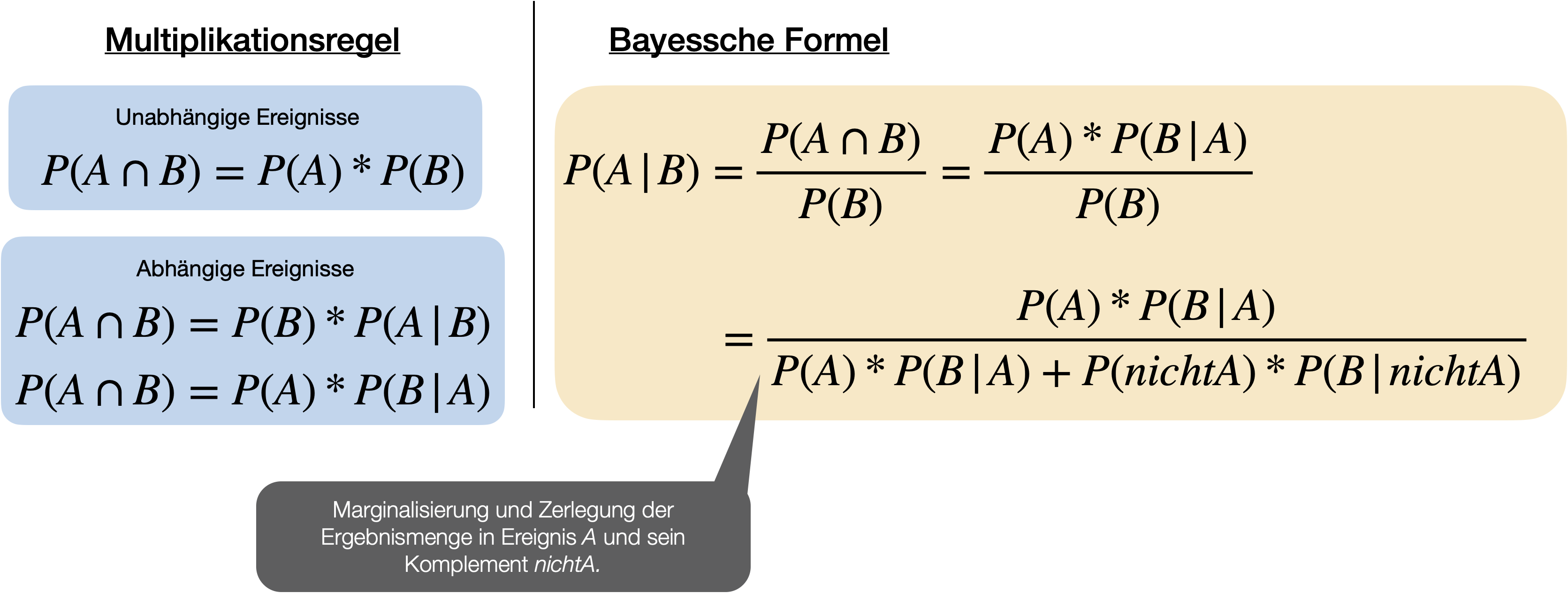

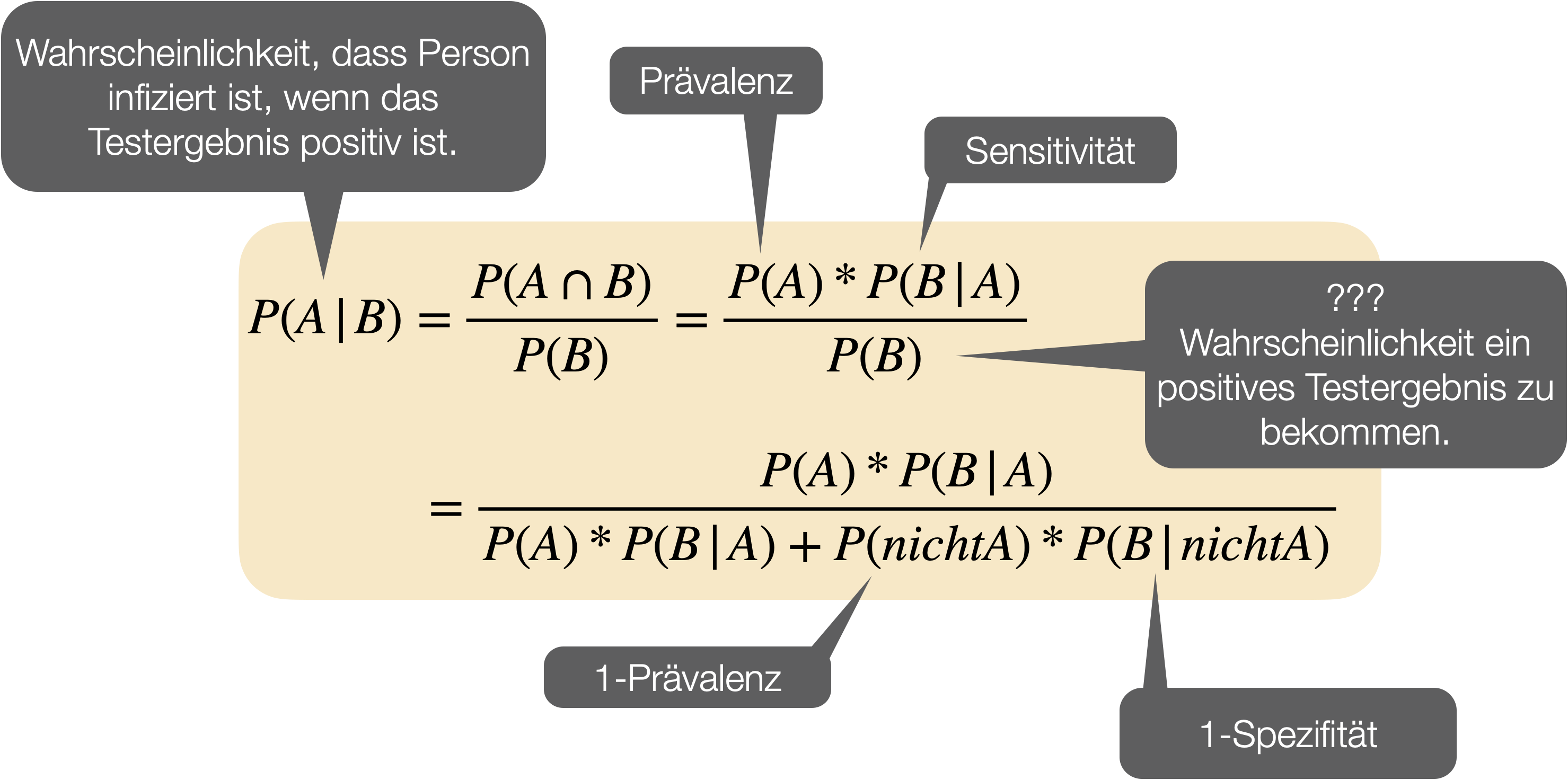
 …gehört zu den wichtigsten Sätzen der Wahrscheinlichkeitsrechnung und wurde vom englischen Mathematiker Thomas Bayes entwickelt und 1763 in
…gehört zu den wichtigsten Sätzen der Wahrscheinlichkeitsrechnung und wurde vom englischen Mathematiker Thomas Bayes entwickelt und 1763 in 

{kind=link}
{kind=link}