1-Einführung in die mathematische Statistik
Data Science 2
Universität Hamburg, IMF & IZS
Sommersemester 2026
Modulübersicht
DS2 - Einführung in die Statistik und das experimentelle Design
![]()
Lernziele des Moduls
![]()
Am Ende des Semesters werden Sie …
- grundlegende Kenntnisse in den Bereichen der Wahrscheinlichkeitstheorie und Statistik haben,
- einen Überblick über verschiedene Datenverteilungen haben und in der Lage sein, auf Normalverteilung hin zu testen,
- die Konzepte der Datenerhebungen und den Zusammenhang zwischen experimentellem Design und statistischer Analyse besser verstehen,
- Hypothesen formulieren und statistische Testergebnisse hinsichtlich der Hypothesen interpretieren können und
- ein geschärftes Urteilsvermögen über geeignete und ungeeignete Methoden entwickelt haben.
Übungsabschluss | 1
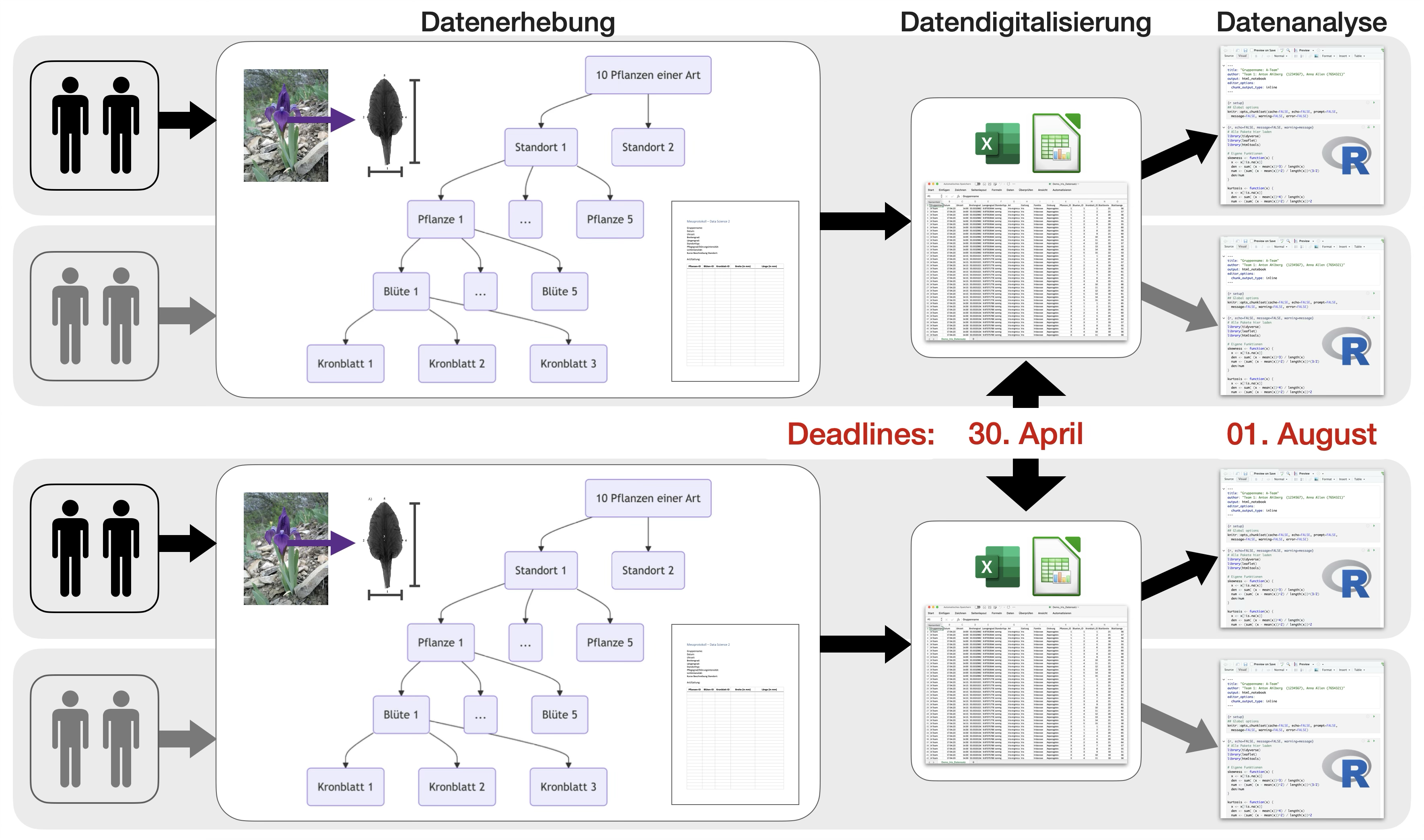
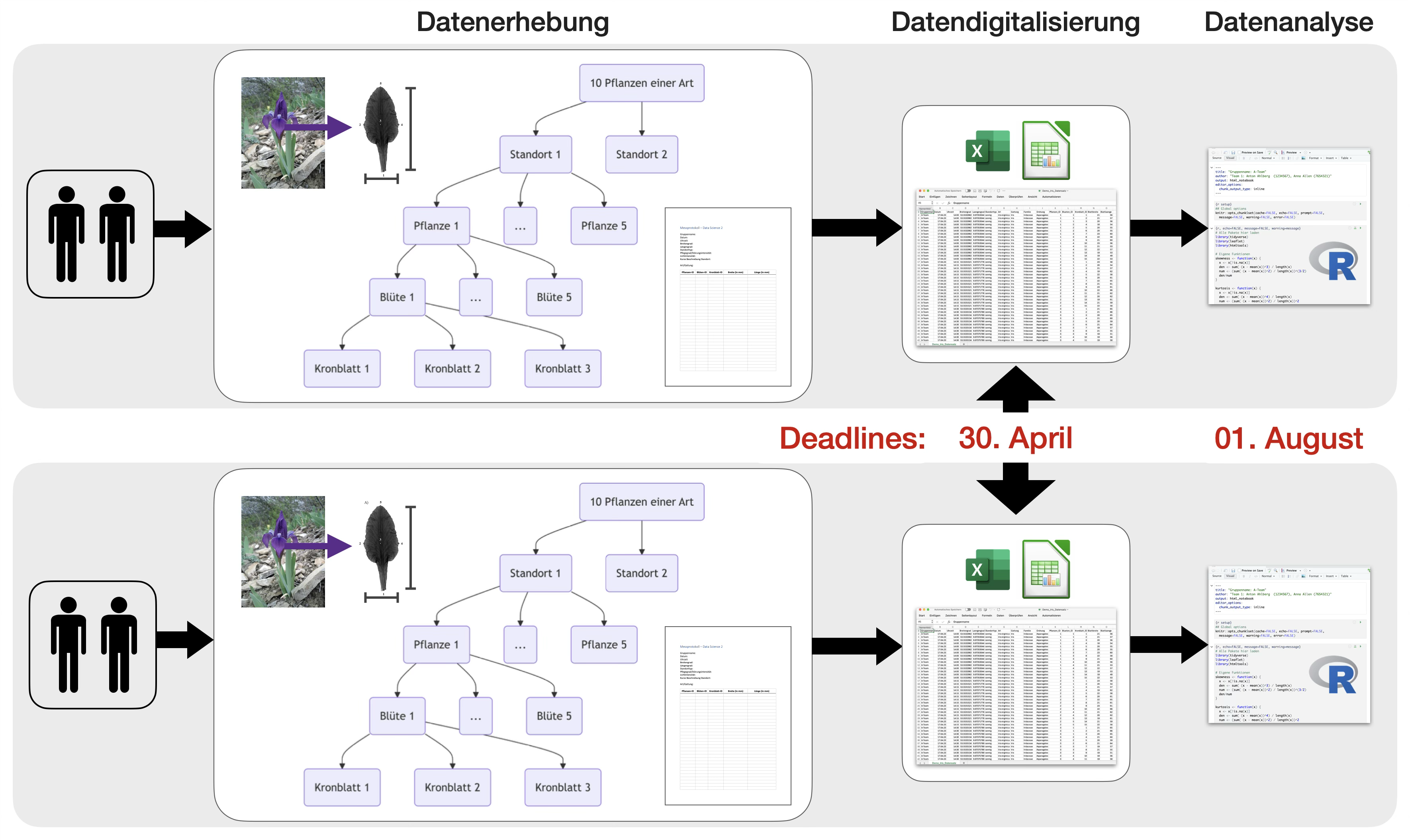
Fallstudie: Blütenallometrie

- begleitend im Semester
- im 2er-Team
Übungsabschluss | 2
Fallstudie: Blütenallometrie
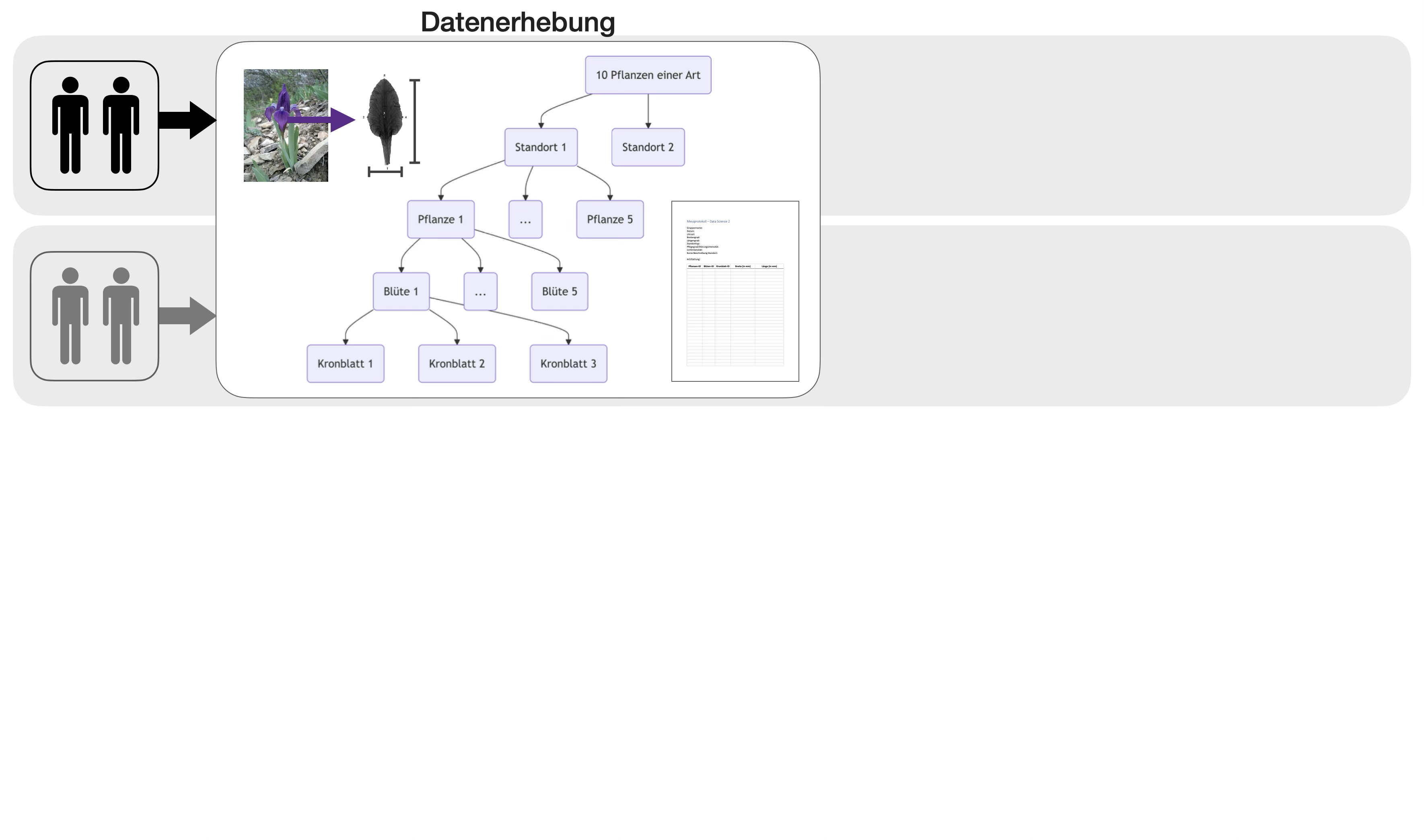
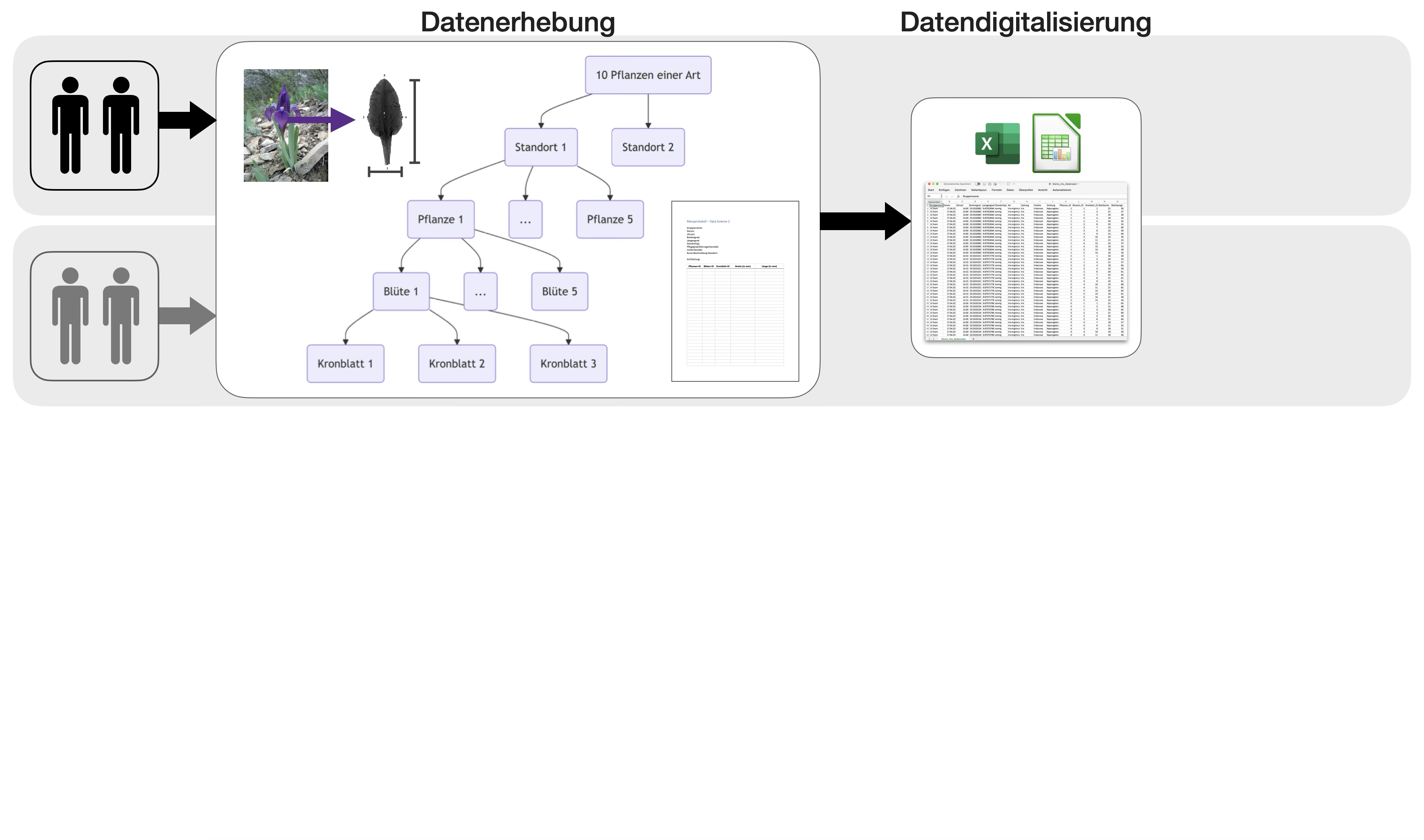
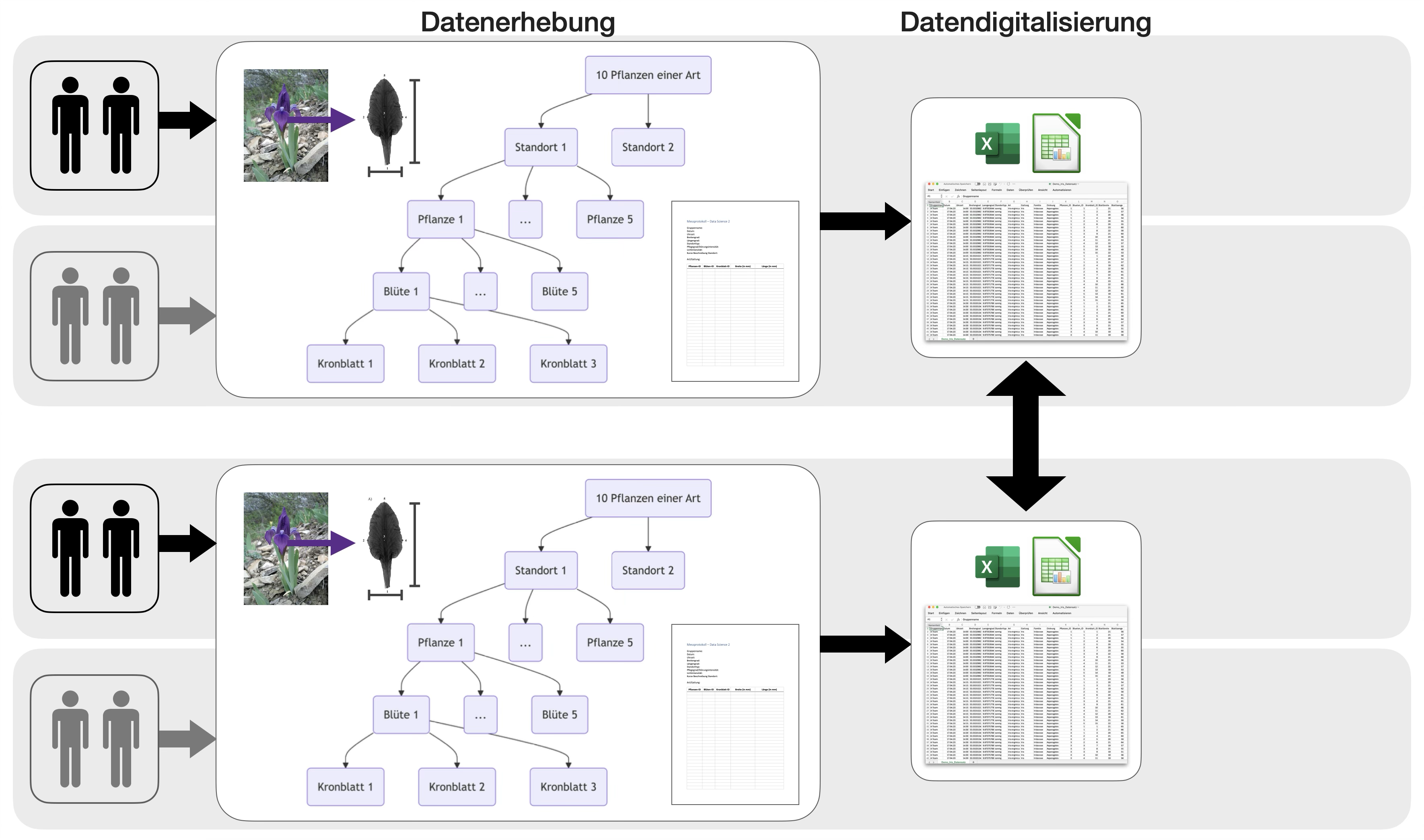
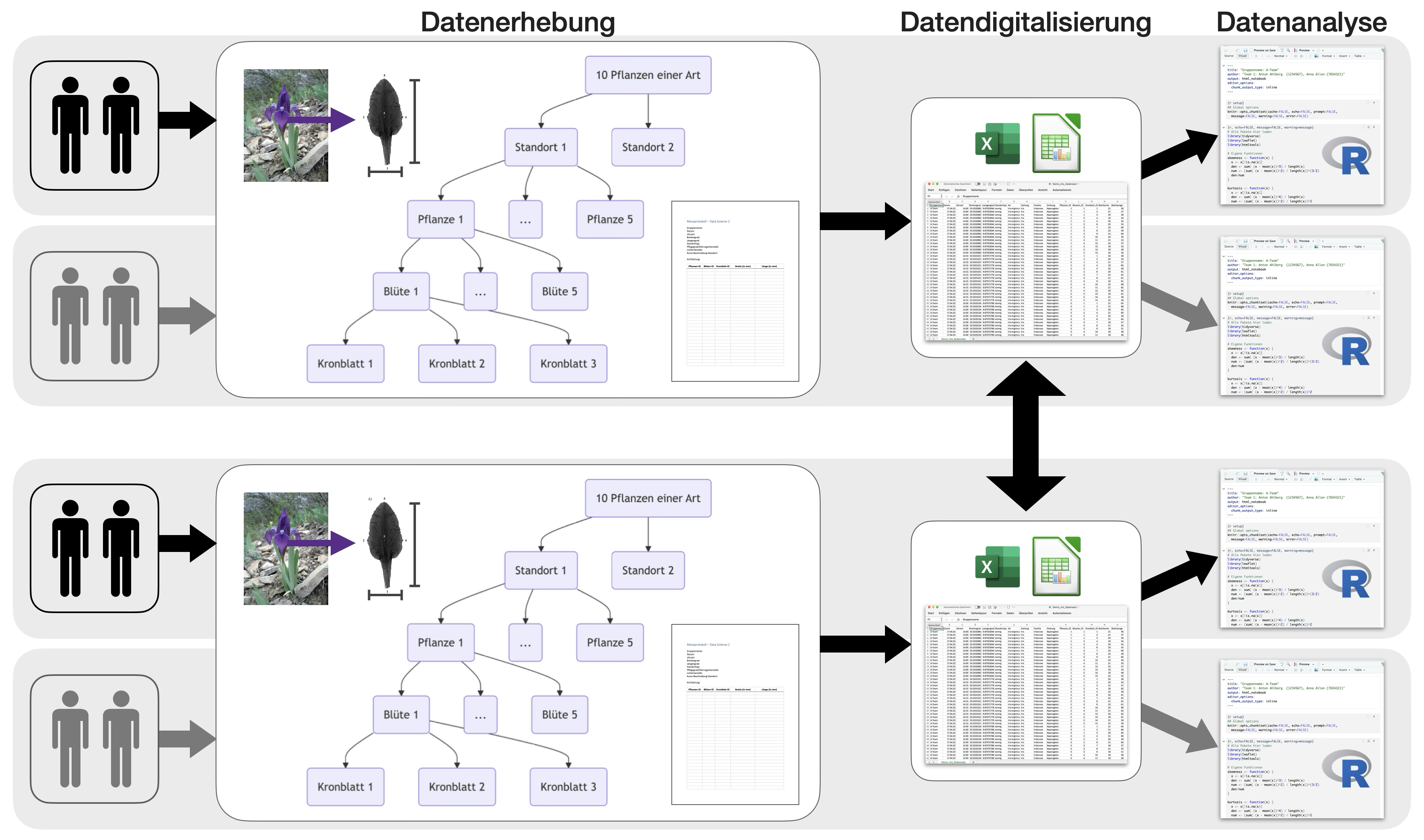
Übungsabschluss | 3
Standorteinteilung
- nach Lichtintensität: sonnig, halbschattig, schattig
- nachPflegegrad/Störungsintensität bzw. Standorttyp:

Materialien & Tools
- VL-Folien im HTML-Format
- Handbuch
- Allgeine Modulinformationen
- Formelsammlung
- Übersicht Testauswahl
- Aufgabenstellung Übungen
- Aufgabenstellung Fallstudie
- R Studio-Projektordner → ZIP-Datei zum Download
- R Notebooks
- Daten
- Vorlagen für Fallstudie
- Moodle:
- VL: PDF-Folien, Aufzeichungen
- Quizze begleitend zu den Übungen mit Lösungen
- Fallstudien: Upload Assignments
- Klausur, Klausurvorbereitendes Quiz
- Kommunikationsplattform
- RStudio Server (URL siehe Moodle)
Begleitende DSB Webseite
![]()

Was hat die Statistik mit dem experimentellen Design zu tun?
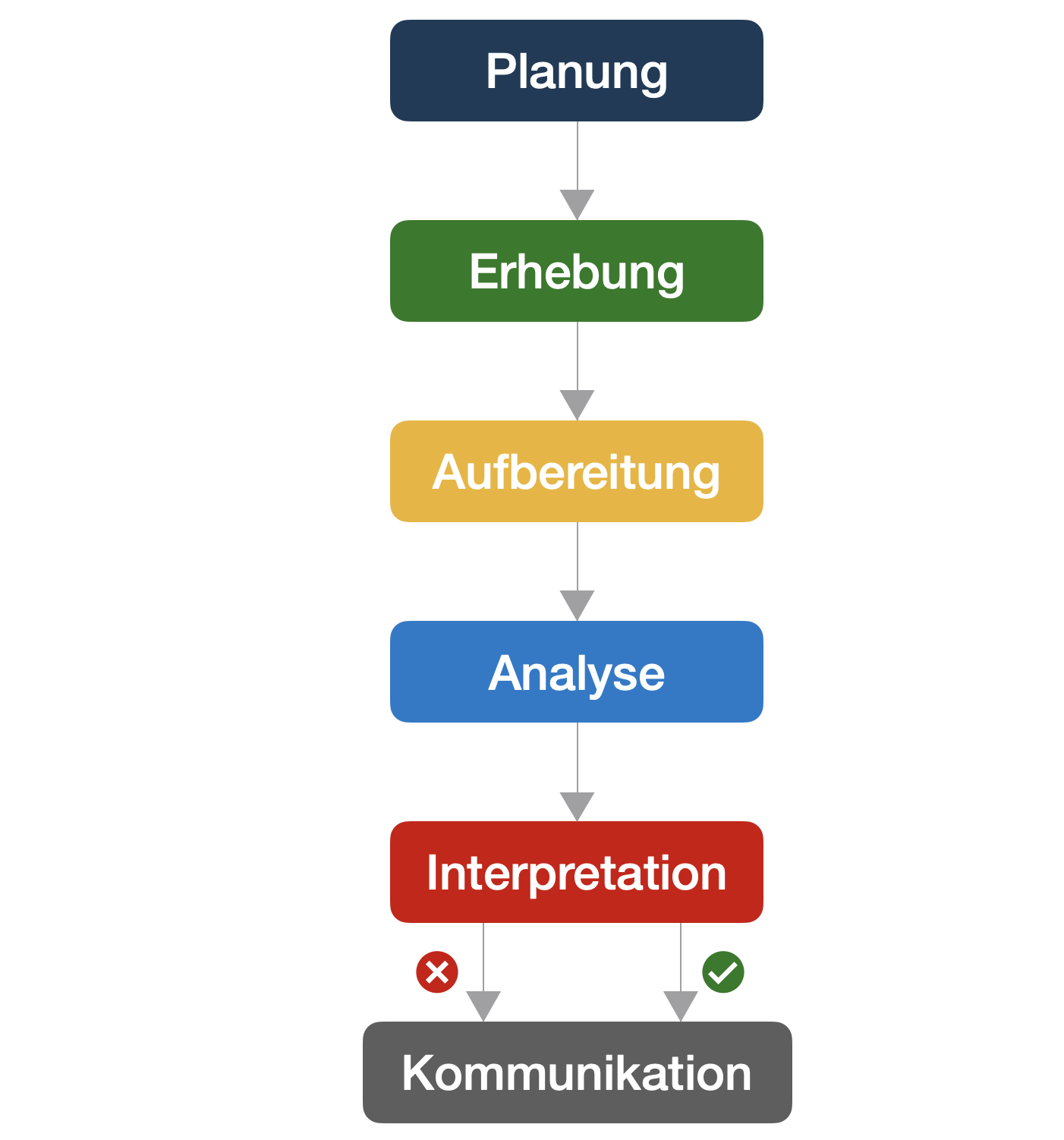
Hauptphasen der Durchführung wissenschaftlicher Studien
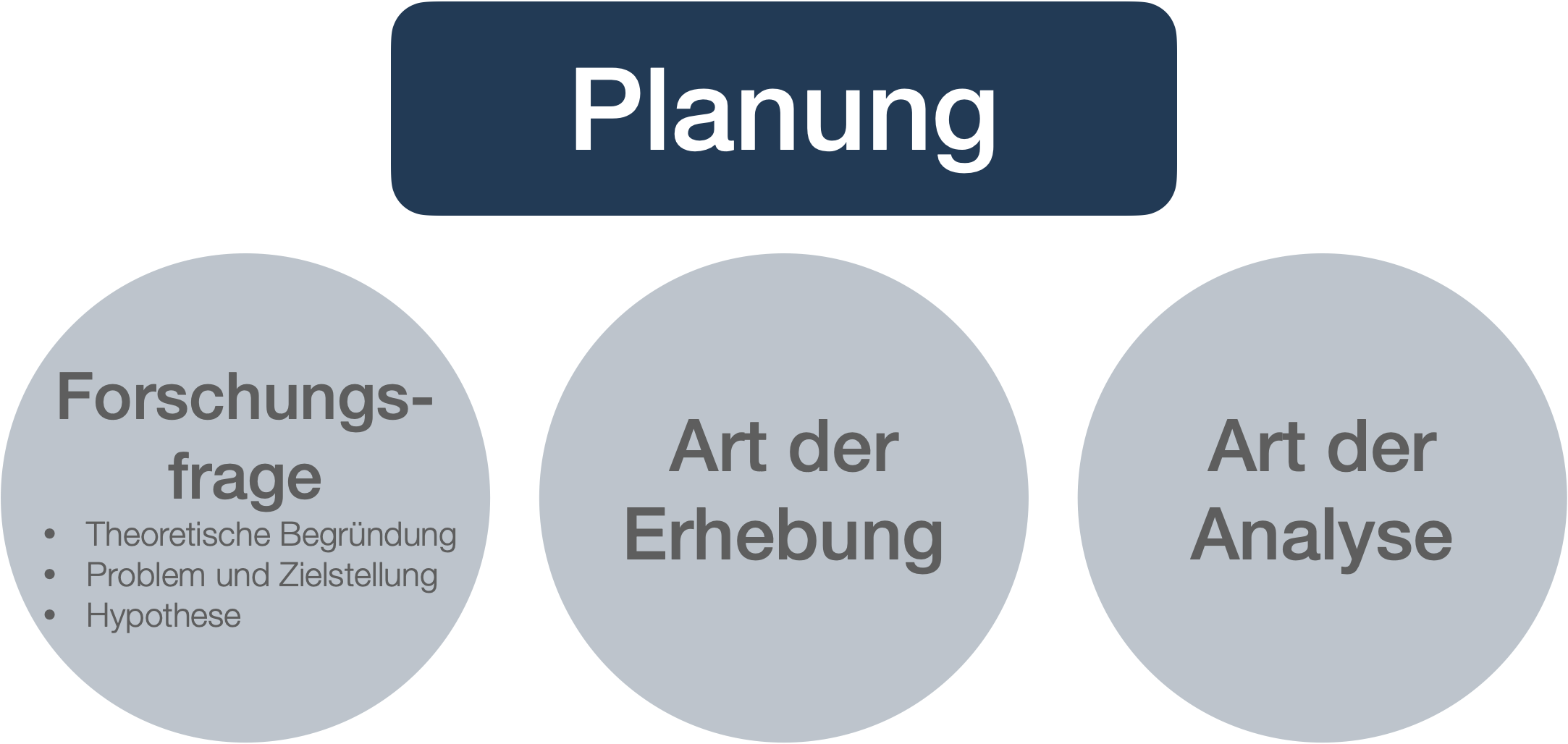
Durchführung wissenschaftlicher Studien | Phase 1
Durchführung wissenschaftlicher Studien | Phase 2
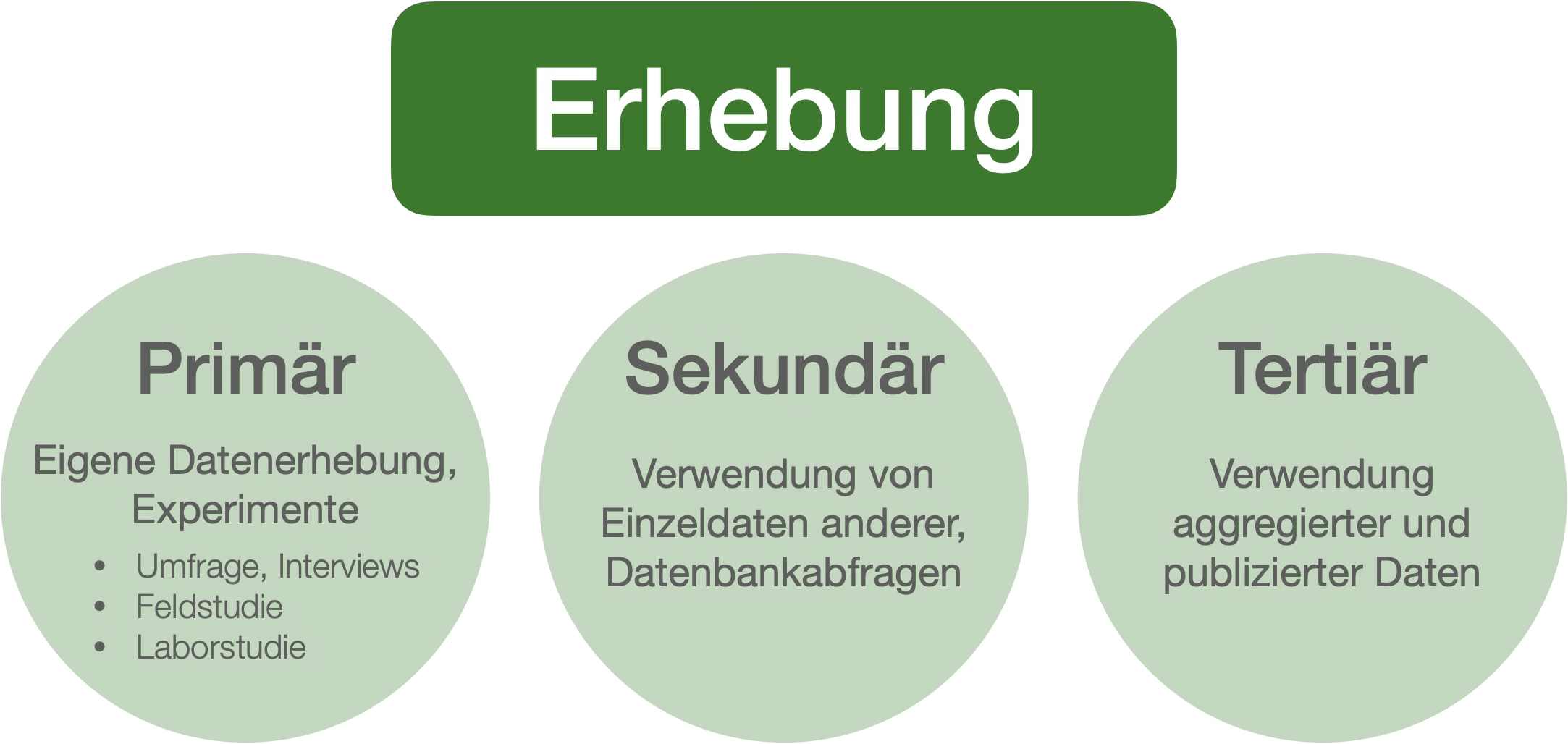
Durchführung wissenschaftlicher Studien | Phase 3
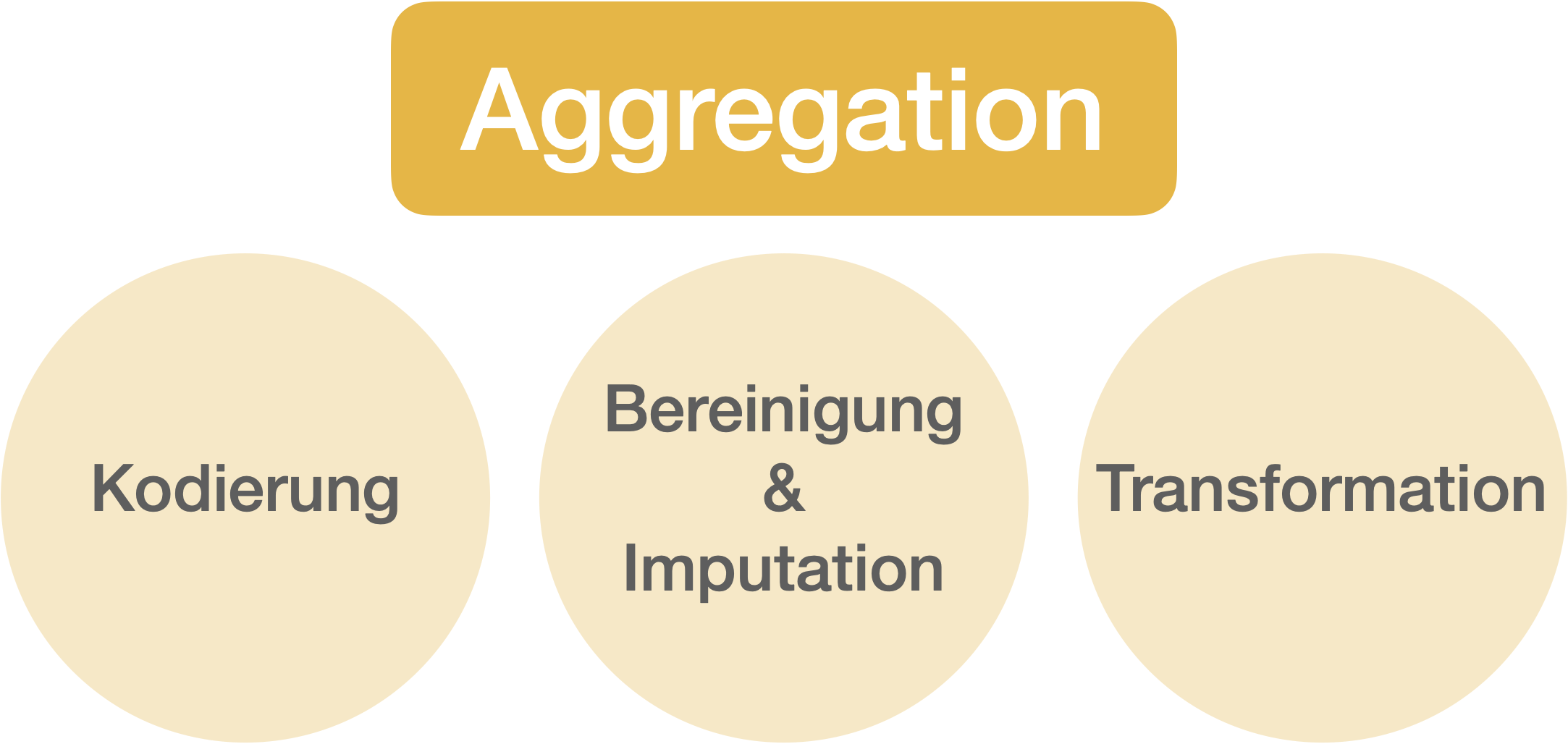
Durchführung wissenschaftlicher Studien | Phase 6

Durchführung wissenschaftlicher Studien
Ständiger Wechsel zwischen den verschiedenen Phasen
MESSENDE vs. manipulative Experimente | 1
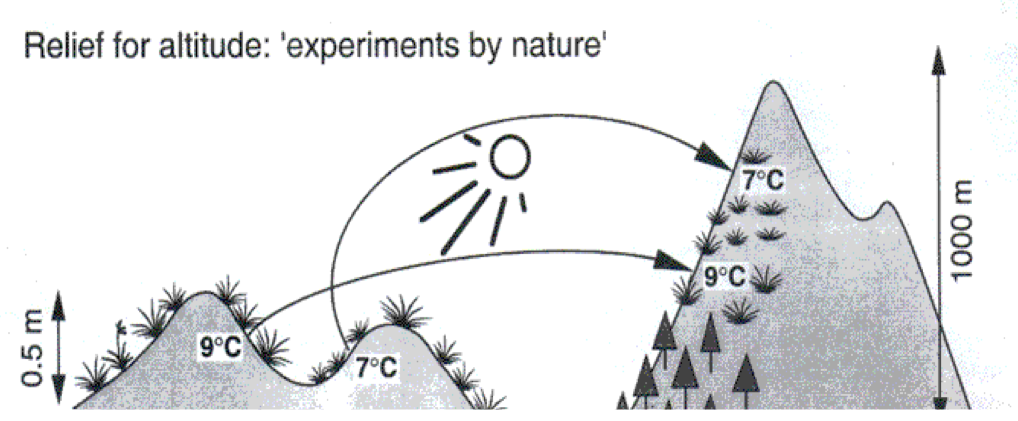
Messende (natürliche, korrelative) Experimente
- Verwendung von bereits bestehenden oder natürlich vorkommenden Behandlungsgruppen.
- Test von Hypothesen über Muster, bestehende Trends oder Beziehungen in der Natur.
- Wenig Kontrolle.
- Dazu gehören auch: Monitorings, Surveys
{kind=link}
Messende vs. MANIPULATIVE Experimente | 2
Unter Laborbedingungen

Eines von NOAAs fischereiwissenschaftlichen Laboren zur Untersuchung der Effekte der Ozeanversauerung auf marine Organismen.
Draussen, in Mesokosmen

MEDIMEER (MEDIterranean platform for Marine Ecosystem Experimental Research) Experiment im Frühjahr 2018 in Sète, Frankreich.
‘LEARNING’ vs. ‘Confirming Experiments’ | 1
Lernende (explorative) Experimente
- Hat das Medikament toxische Nebenwirkungen (in welcher Dosis, über welchen Zeitraum, in welchem Gewebe)?
- Das Ziel ist etwas Neues zu lernen.
- Hypothese ist allgemeiner und ein statistischer Test ist weniger wichtig
- Typisches Beispiel in der Biologie: ‘High-throughput screening’ in den Omics Wissenschaften.

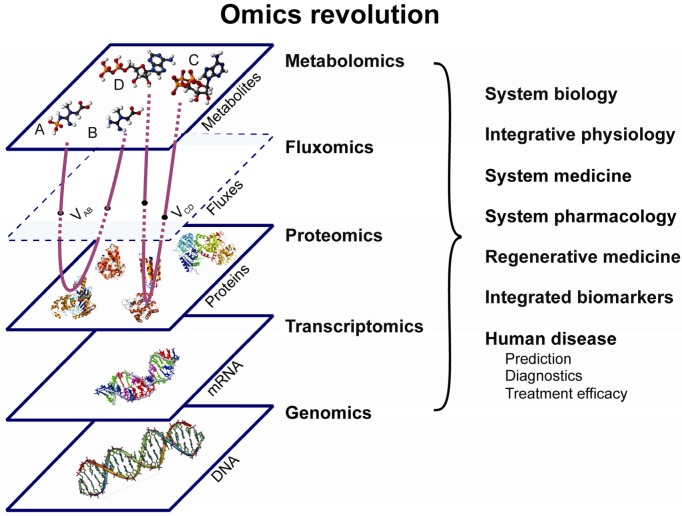
Emutlu et al. (2012): 18O-assisted dynamic metabolomics
for individualized diagnostics and treatment of human
diseases, Croat Med J 53(6): 529–534
‘Learning’ vs. ‘CONFIRMING Experiments’ | 2
Lernende (explorative) Experimente
- Hat das Medikament toxische Nebenwirkungen (in welcher Dosis, über welchen Zeitraum, in welchem Gewebe)?
- Das Ziel ist etwas neues zu lernen.
- Hypothese ist allgemeiner und ein statistischer Test ist weniger wichtig.
- Typisches Beispiel in der Biologie: ‘High-throughput screening’ in den Omics Wissenschaften.
Bestätigende Experimente
- Erhöht sich die Kreatinkonzentration im Blut, wenn 5 mg/kg des Arzneimittels einmal täglich über 5 Tage verabreicht werden?
- Basieren oft auf lernenden Experimenten.
- Spezifische Hypothesen werden getestet, bei denen häufig die Effektstärke wichtig ist.
Mathematische Statistik

Einführung | Statistik als Teil der Stochastik
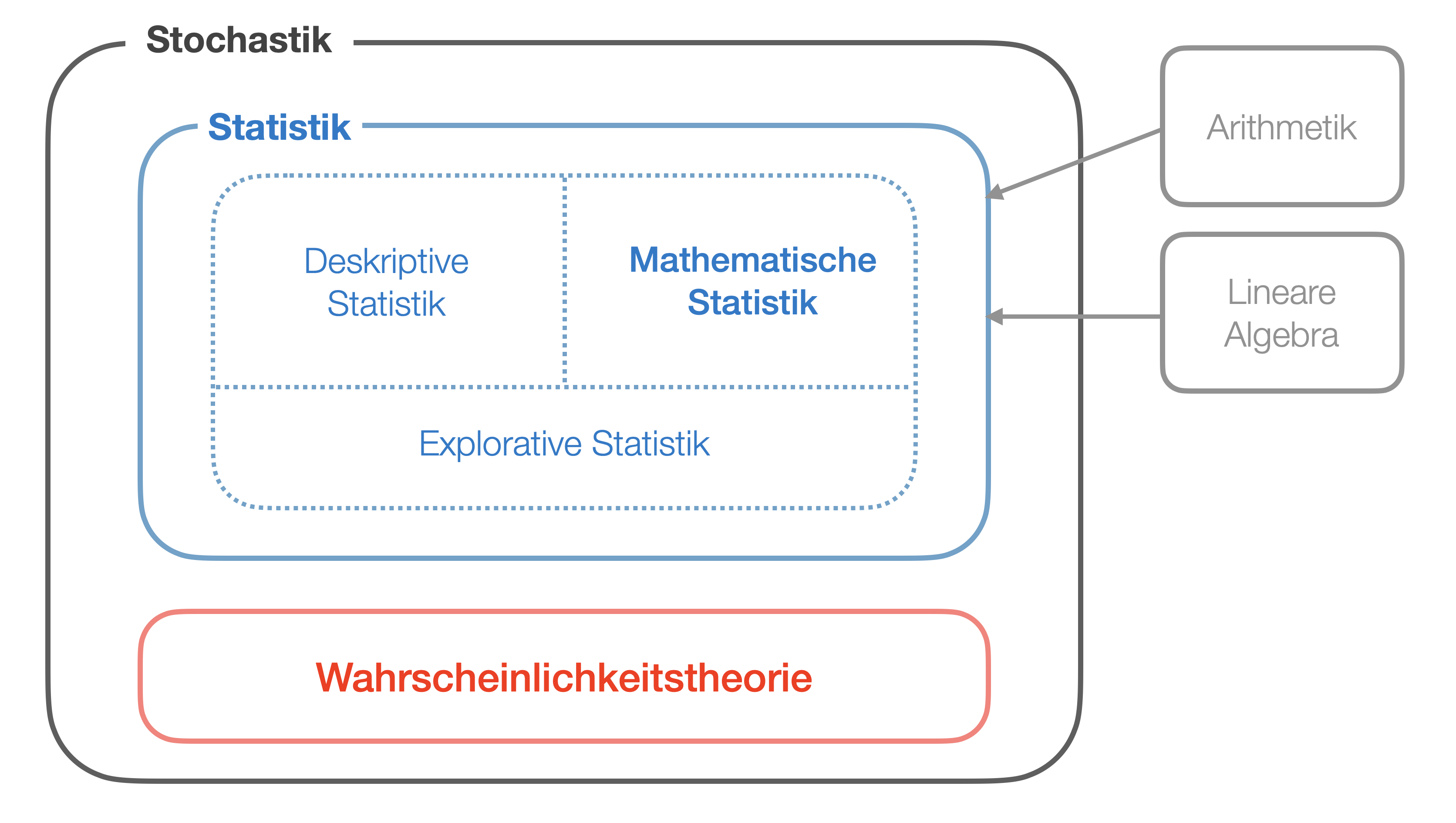
Die Statistik ist ein Teilgebiet der reinen Mathematik und betrachtet das Sammeln, die Analyse, die Präsentation und Interpretation von Daten. Sie stellt somit die theoretische Grundlage aller empirischen Forschung dar.
Anstoß zur Wahrscheinlichkeitsrechnung
.. gaben vor allem Glücksspiele Anfang des 17. Jhd.

Bildquelle Roulettespieler: Wikipedia (CC0 Lizenz)
{kind=link}
2 Historische Aufgaben aus der Kombinatorik
Die Aufgabe von Galileo Galilei

Um 1615 sollen italienische Spieler (in einigen Quellen heißt es auch der Fürst von Toskana) Galilei folgende Frage gestellt haben, welche eine viel diskutierte, Jahrhunderte alte Aufgabe darstellte:
Wie groß sind die Wahrscheinlichkeiten, mit 3 Würfeln eine Summe von 9 oder 10 zu erhalten?
Die damaligen Theoretiker behaupteten, dass beide Summen gleich wahrscheinlich seien. Aus ihrer Erfahrung wussten allerdings die Glücksspieler, dass die 10 häufiger als die 9 autritt.
Das De-Méré-Paradoxon

Als eigentliche Geburtsstunde der mathematischen Wahrscheinlichkeitsrechnung gilt das Jahr 1654. Chevalier de Meré, ein Philosoph und Literat am Hofe Ludwigs des XIV, wandte sich mit folgendem Problem an den bekannten Mathematiker Blaise Pascal:
Was ist wahrscheinlicher, in vier Würfen eines einzelnen Würfels mindestens eine ‘6’ zu würfeln ODER in 24 Würfen eines Würfelpaars mindestens eine ‘Doppelsechs’ zu erzielen?
Auch dieses Problem war damals schon viele Jahrhunderte alt. Allerdings waren die früheren Lösungen falsch.
>250 Jahre Statistik | 1
Bevölkerungsstatistik (~19 Jhd.)

- Volkszählungen älteste bekannte Anwendungen der Statistik (erste Volkszählung 1801).
- Bürokratisches Sammeln großer Datenmengen über Bevölkerung → viktorianische Statistiker System entwickelt zur Erfassung von Daten zur Volksgesundheit → führte zu politischen Reformen und Entstehung ‘Public Health Act’;
- Bevölkerungsstatistiker Auffassung, dass statistische Variation Fehlerquelle sei, die man abschaffen müsste; Fokus hier auf Durchschnittswerte (Idee der perfekten Mitte, Lehre des Determinismus).
- Darwins Theorie der biologischen Variation schuf Rahmen für Konzeption neuer statistischer Methoden; Fokus verlagert sich auf die Varianz.
Bildquelle zur Geschichte der Statistik: Magnello & van Loon (2013)
>250 Jahre Statistik | 2
Mathematische Statistik (Ende 19./Anfang 20. Jhd.)
- Mathematische Statistik entstand aus der mathematischen Wahrscheinlichkeitstheorie durch Werke von Bernoulli, Laplace, Gauß und DeMoivre.
- Teilaspekte von Kontinentaleuropa ausgehend, aber meiste von Briten entwickelt. Z.B.
- Francis Galton (Vetter von Charles Darwin): Begründer der Biometrie, entwickelte Grundlagen der Regression und Korrelation
- Karl Pearson: arbeitete \chi^2-Verteilung aus, entwickelte parametrischen Korrelationskoeffizienten
- Ronald A Fisher: entwickelte Grundlagen der Varianzanalyse, Planung von Experimenten, Zufallsanordnungen
Bildquelle zur Geschichte der Statistik: Magnello & van Loon (2013)
Teilgebiet 1 der Statistik
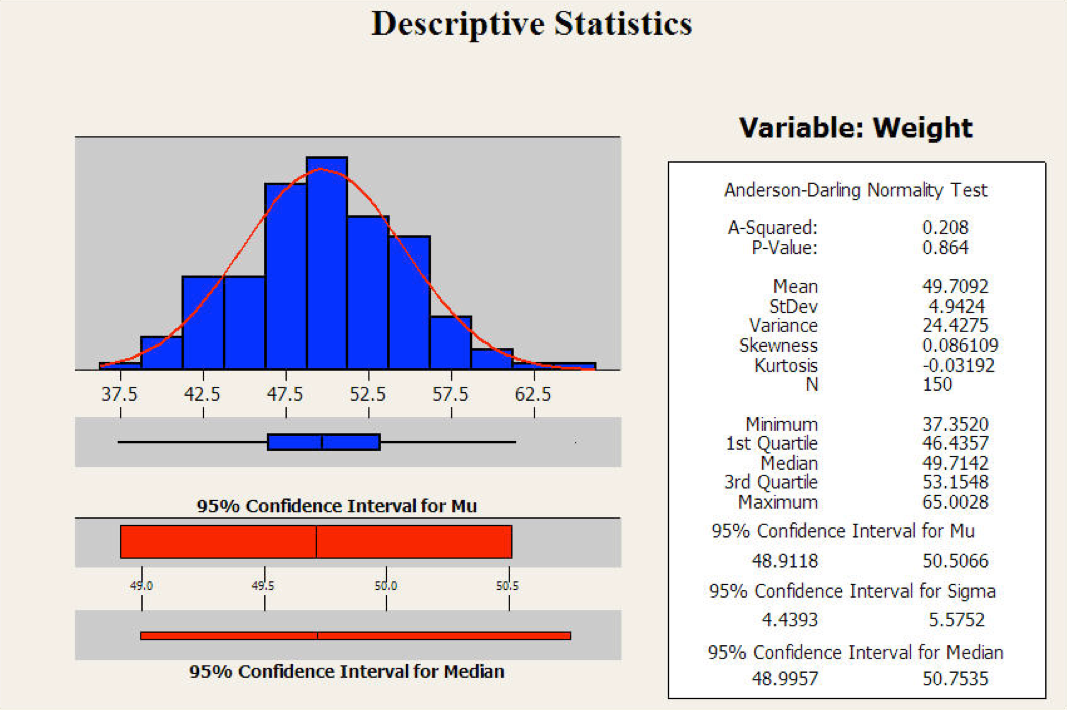
Deskriptive Statistik
- = beschreibende, empirische Statistik
- Vorliegende Daten werden in geeigneter Weise beschrieben, aufbereitet und zusammengefasst.
- Hauptaufgabe der Statistikämter, Alltagsgebrauch
- 2 Methoden:
- Grafisch (Histogramm, Säulendiagramm) → Aussage über die Verteilung der Werte
- Numerisch (Mittelwert, Varianz) → Aussage über Zentriertheit und Streuung
Teilgebiet 2 der Statistik
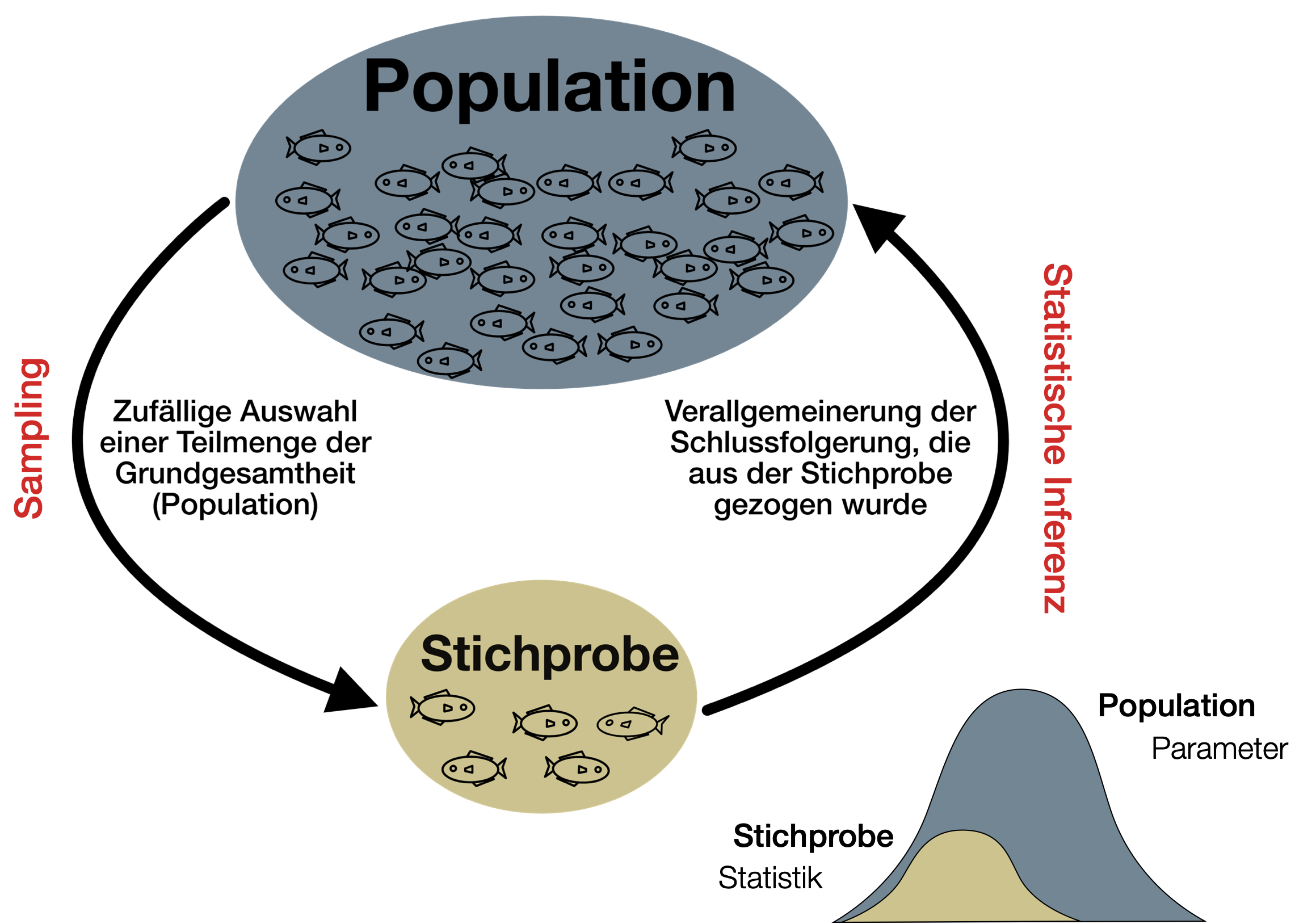
Mathematische Statistik
- = induktive, schließende Statistik, Inferenzstatistik
- Eigenschaften einer Grundgesamtheit werden aus Daten einer Stichprobe abgeleitet.
- Grundlage der Schätz-und Testverfahren ist die Wahrscheinlichkeitstheorie → Inferenzen sind nie sicher und werden als Wahrscheinlichkeiten ausgedrückt
- Schätzverfahren (estimation): Berechnung von Stichprobenstatistik und Wertebereich indem Populationsparameter mit bestimmter Wahrscheinlichkeit vermutet wird (Konfidenzintervall)
- Testverfahren (hypothesis-testing): setzt eine zu testende Hypothese voraus
- schließt im weiteren auch Prognosen (forecasts/predictions) ein
Übungsaufgaben
![]()
Vorbereitungen (VOR 1. Übung)
Downloads von Handbuch und Projektordner
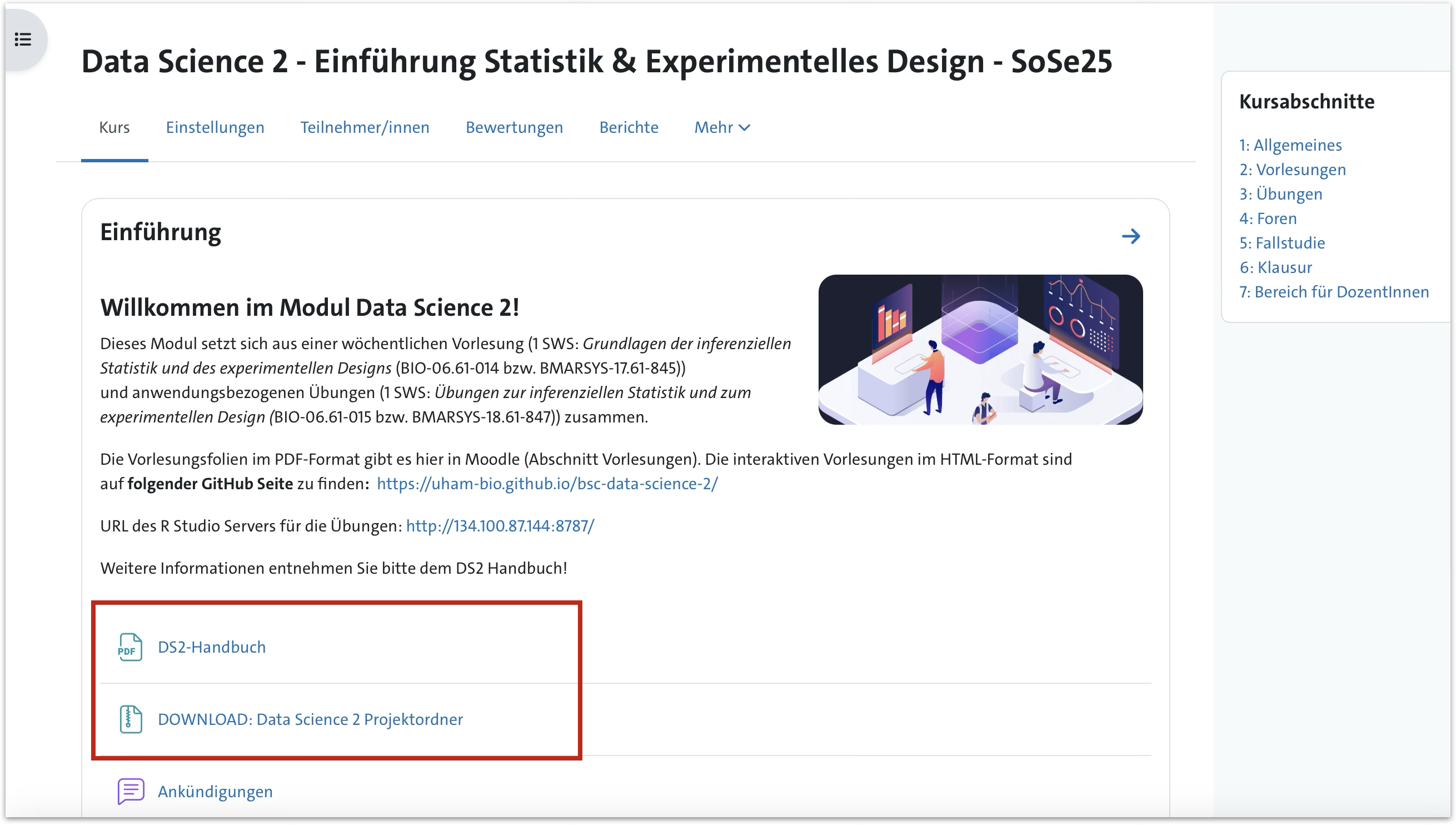
Fallstudie
- Lesen Sie die Aufgabenbeschreibung durch.
- Bilden Sie 2er-Teams und überlegen Sie sich,
- mit welchem anderen 2er-Team Sie zusammenarbeiten wollen.
- welche Art und welche Standorte Sie beproben wollen (welche Fragestellung).
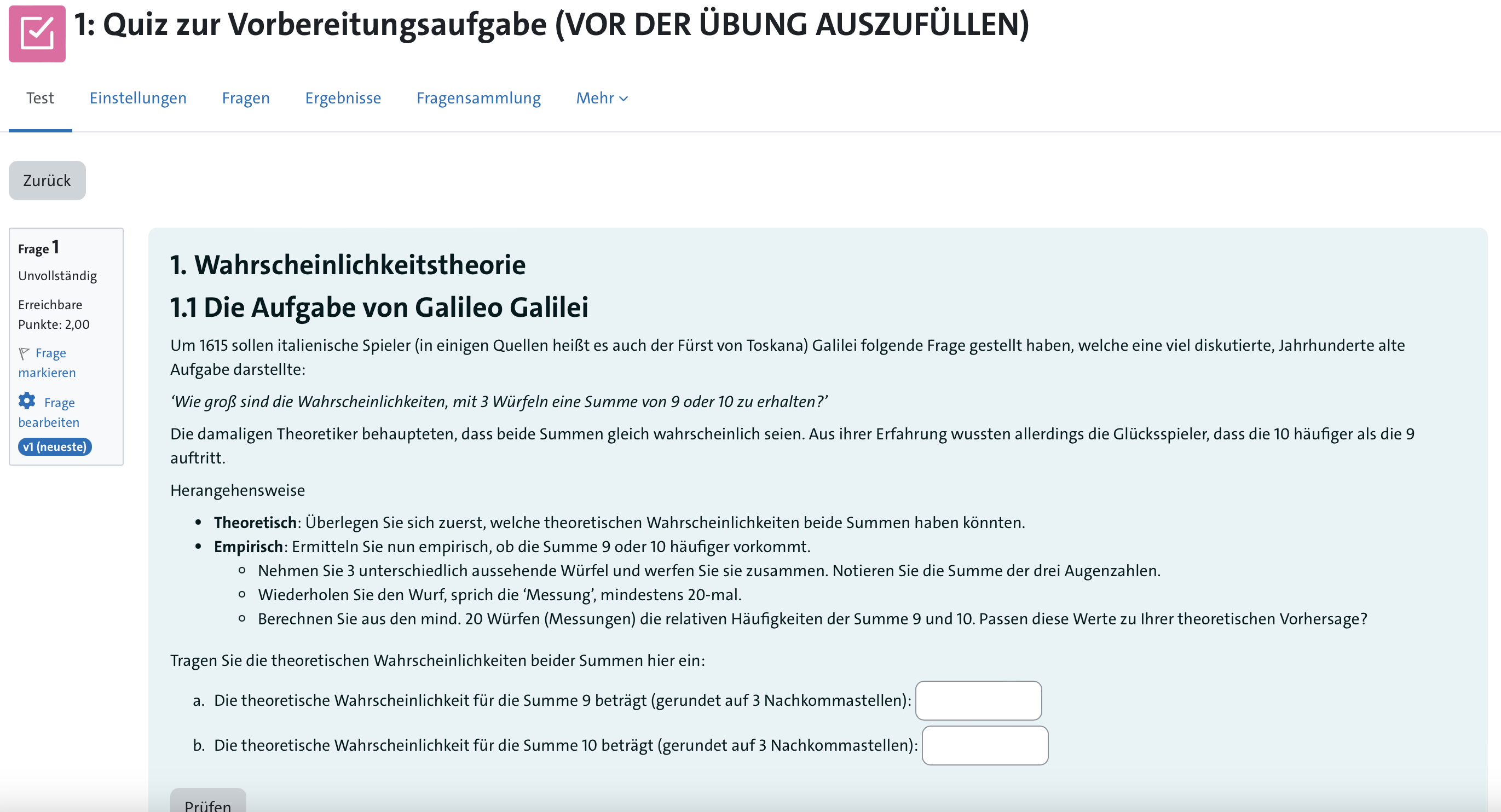
Aufgabe 1: Die Aufgabe von Galileo Galilei
Wie groß sind die Wahrscheinlichkeiten, mit 3 Würfeln eine Summe von 9 oder 10 zu erhalten?
Herangehensweise
- Theoretisch: Überlege Dir zuerst welche theoretischen Wahrscheinlichkeiten beide Summen haben könnten.
- Empirisch: Nun ermittle empirisch, ob die Summe 9 oder 10 häufiger vorkommt.
- Nimm 3 unterschiedlich aussehende Würfel und werfe sie zusammen. Notiere Dir die Summe der drei Augenzahlen.
- Wiederhole den Wurf, sprich die ‘Messung’, mindestens 20-mal.
- Berechne aus den mind. 20 Würfen (Messungen) die relativen Häufigkeiten der Summe 9 und 10. Passen diese Werte zu Deiner theoretischen Vorhersage?
{kind=link}
Aufgabe 2: Die Aufgaben des Chevalier de Meré
Was ist wahrscheinlicher, in vier Würfen eines einzelnen Würfels mindestens eine ‘6’ zu würfeln (Variante A) ODER in 24 Würfen eines Würfelpaars mindestens eine ‘Doppelsechs’ zu erzielen (Variante B)?
Herangehensweise
- Theoretisch: Überlege Dir zuerst welche theoretischen Wahrscheinlichkeiten beide Varianten haben könnten.
- Empirisch: Nun ermittle empirisch, ob die Variante A oder B häufiger vorkommt.
- Führe Variante A und B getrennt durch und notiere Dir die Gesamtaugenzahl bei jedem Wurf (= Messung).
- Wiederhole jede Messung mindestens 20-mal.
- Berechne aus den mind. 20 Messungen die relativen Häufigkeiten der ‘6’ (Variante A) und der ‘Doppelsechs’ (Variante B). Passen diese Werte zu Deiner theoretischen Vorhersage?
{kind=link}
Moodle-Quiz
Abschlussquiz
![]()
Bei weiteren Fragen: saskia.otto(at)uni-hamburg.de

Diese Arbeit is lizenziert unter einer Creative Commons Attribution-ShareAlike 4.0 International License mit Ausnahme der entliehenen und mit Quellenangabe versehenen Abbildungen.