Handhabung spezieller Datentypen
Data Science 1 - Programmieren & Visualisieren
Universität Hamburg, IMF
Wintersemester 2025/2026
Lernziele
![]()
Am Ende dieser VL- und Übungseinheit werden Sie
- Faktoren mit den entsprechenden Faktorstufen und sichtbaren Labels erstellen können.
- Funktionen kennen, um die Reihenfolge der Stufen in z.B. Grafiken zu ändern.
- wissen, wie das Datum und die Zeit von Computern behandelt wird.
- als ‘character’ interpretierte Datum- und Zeitangaben in Date und POSIXct Objekte umwandeln können.
- Datumkomponenten extrahieren können.
- wissen, wie Strings modifiziert und kombiniert werden können.
- wissen, wie Muster in Strings gefunden und ersetzt und wie Strings nach Muster aufgeteilt werden können.
- einen ersten Überblick über reguläre Ausdrücke bei der Zeichenmanipulation haben.
DSB Cheatsheet
Eine komplette Übersicht der wichtigsten Funktionen gibt es hier:

Dieses wie alle anderen DSB Cheatsheets gibt es auf Moodle und der DSB Website uham-bio.github.io/data-science/resources/cheatsheets.
Kategoriale Variablen als Faktoren
Nachteile eines Zeichenvektors
Stellen Sie sich vor, Sie haben einen Vektor vom Typ ‘character’, der Monate enthält:
Die Verwendung einer Zeichenkette für diese Variable birgt zwei Probleme:
Faktoren | levels definieren
Lösung
![]() Übergeben Sie dem Argument
Übergeben Sie dem Argument levels einen Vektor mit allen gültigen Faktorstufen in gewünschter Reihenfolge.
- Sie können hier Faktorstufen einfügen, die nicht unbedingt im zu konvertierenden Vektor sein müssen.
- Jeder Wert, der nicht im Faktorstufen-Vektor ist, wird “leise”” als NA konvertiert.
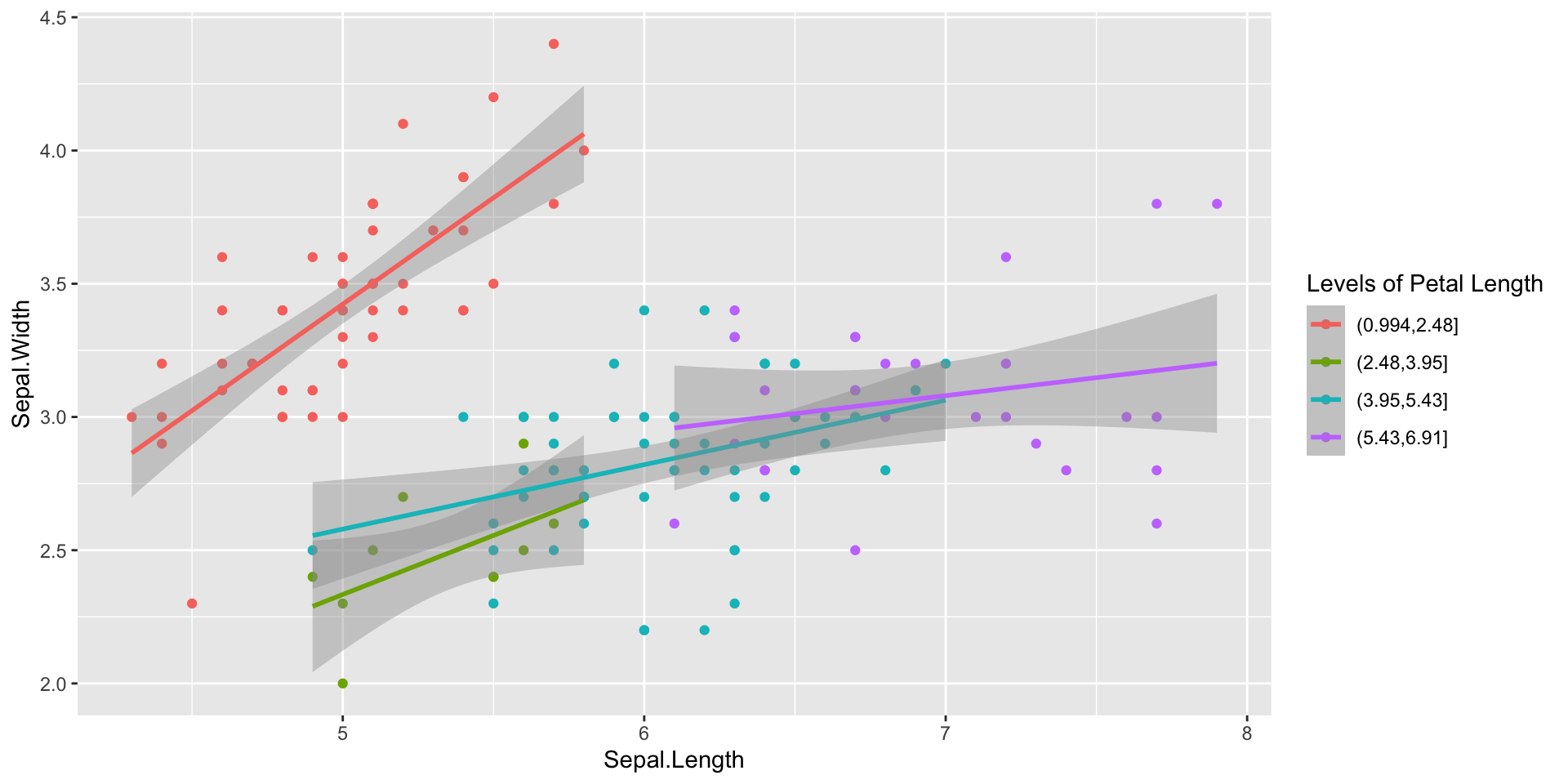
Kontinuierliche Variablen zu Faktoren | 2
Anwendungsbeispiel
Weitere Optionen mit ‘forcats’
![]()
Ein hilfreiches ‘tidyverse’ Paket für Faktoren
- Manuelle Ordnung der Faktorstufen:
fct_relevel() - Ordnung der Stufen entsprechend
- ihrer ersten Erscheinung im Datensatz:
fct_inorder() - ihrer Häufigkeit:
fct_infreq()
- ihrer ersten Erscheinung im Datensatz:
- Umgedrehte Reihenfolge der Faktorstufen:
fct_rev() - Sortierung entlang einer anderen Variable:
fct_reorder() - Zusammenlegung von Faktorstufen in manuell definierte Gruppen:
fct_collapse()
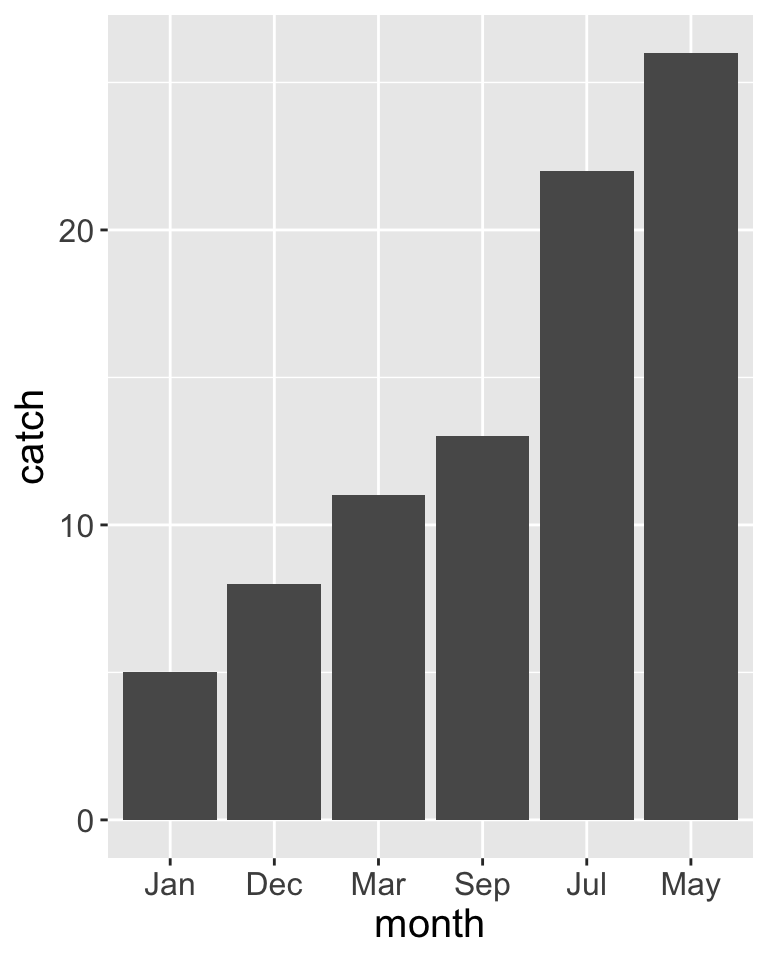
Weitere Optionen mit ‘forcats’ | Demo
Code
p <- bshydro15 |> ggplot() +
guides(x = guide_axis(angle = 45)) +
theme(text = element_text(size = 16))
p1 <- p + geom_bar(aes(month)) + ggtitle("Standardeinstellung")
p2 <- p + geom_bar(aes(fct_rev(month))) + ggtitle("fct_rev()")
p3 <- p + geom_bar(aes(fct_infreq(month))) + ggtitle("fct_infreq()")
p4 <- p + geom_bar(aes(fct_collapse(
month,
q1 = c("Jan", "Feb", "Mar"),
q2 = c("Apr", "May", "Jun"),
q3 = c("Jul", "Aug", "Sep"),
q4 = c("Oct", "Nov", "Dec")
))) +
xlab("annual quarter") +
ggtitle("fct_collapse()")
gridExtra::grid.arrange(p1,p2,p3,p4, nrow=2)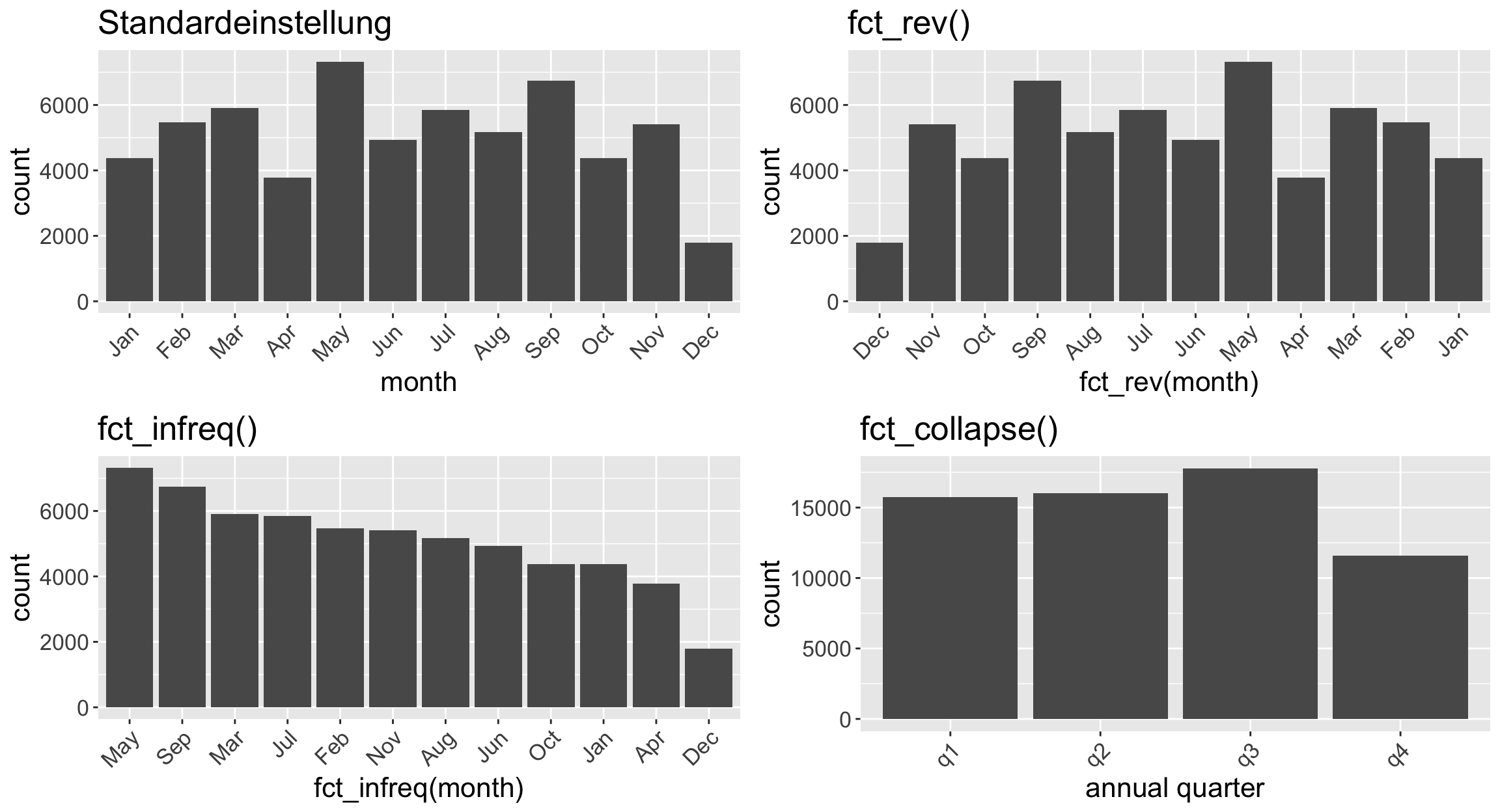
Your turn …
![]()
Quiz 1-2 | Faktoren
![]()
![]()
Q1
Q2
Der Umgang mit Datum und Zeit
Zeit ist nicht gleich Zeit
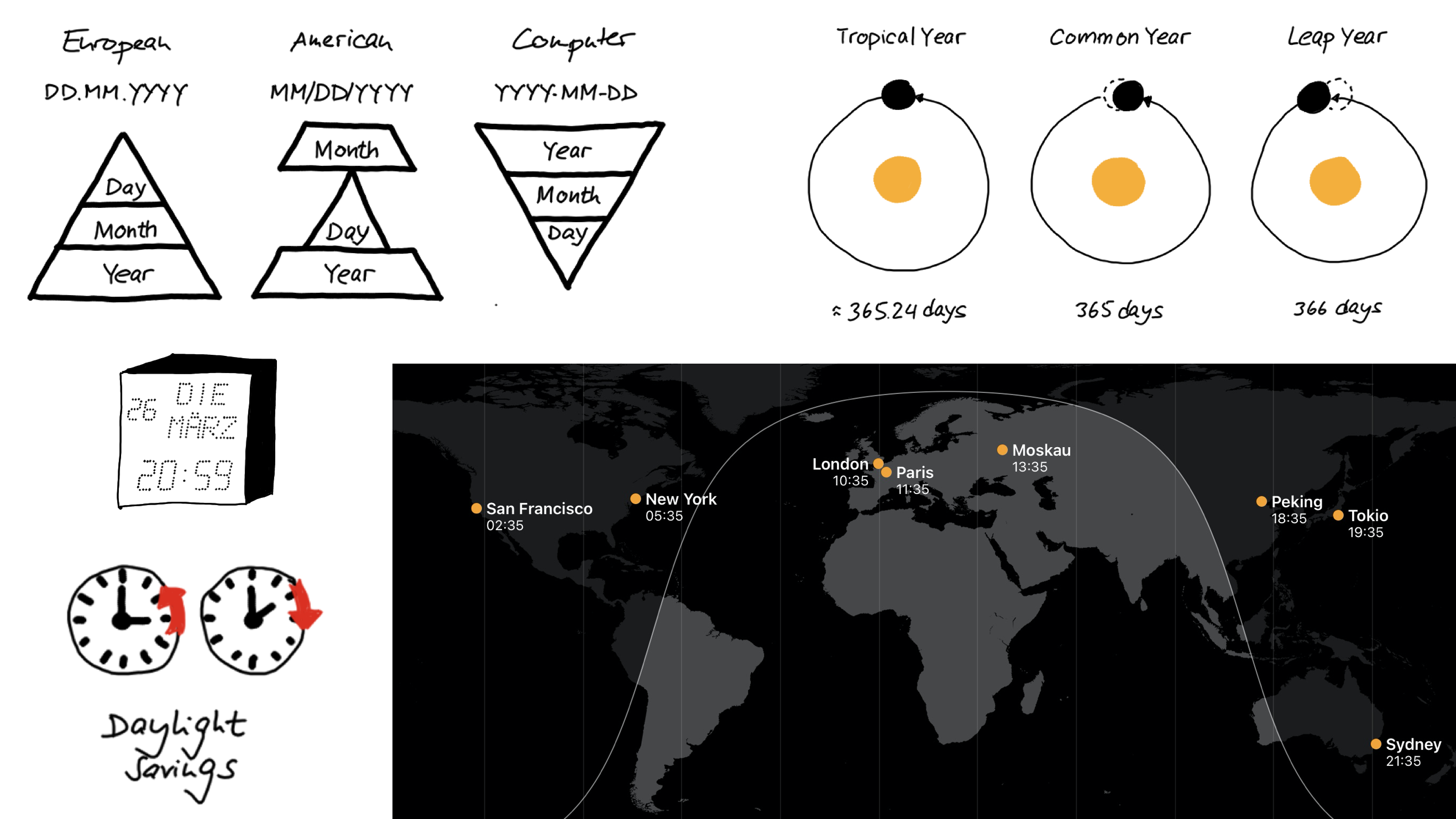
Das ‘lubridate’ Paket
![]()
- Variablen mit Datum- und Zeitangaben werden beim Import oft nicht automatisch erkannt.
- Die explizite Definition des Datentyps (
DateoderPOSIXct) ist aber nützlich, um einzelne Zeitkomponenten später zu extrahieren (z.B. Monat, Jahr, etc.).
Definition des Datums (Date Objekte)
![]()
6 Funktionen zur Auswahl
- Abhängig von der Reihenfolge der Datumskomponenten gibt es folgende Funktionen:
ymd(),ydm(),mdy(),myd(),dmy(),dym()
- Die Reihenfolge ist entscheidend, das Format wird automatisch erkannt.
- Die Funktionen können auf einzelne Zeichenketten oder ganze Vektoren angewendet werden.
Beispiele
ymd("2021-11-17") # YEAR-MONTH-DAY[1] "2021-11-17"mdy("Nov 17th, 2021") # MONTH-DAY-YEAR[1] "2021-11-17"dmy("17-Nov-2021") # DAY-MONTH-YEAR[1] "2021-11-17"x <- c("17-Nov-2021", "20-Nov-2021")
dmy(x)[1] "2021-11-17" "2021-11-20"Definition von Datum/Zeit (POSIXct)
![]()
6 x 3 Möglichkeiten
Kombinieren Sie einfach eine der 6 Datumfunktionen (ymd(), ydm(), mdy(), myd(), dmy(), dym()) mit:
_hwenn Sie nur die Stunde haben_hmwenn Sie Stunde und Minuten haben_hmsfür Stunde-Minute-Sekunde (hour:min:sec)
Beispiele
# Datum mit HOUR
mdy_h("Nov 17th, 2021 13")[1] "2021-11-17 13:00:00 UTC"# Datum mit HOUR-MIN
mdy_hm("11/17/2021 12:11")[1] "2021-11-17 12:11:00 UTC"# Datum mit HOUR-MIN-SEC
ymd_hms("2021-11-17 12:11:59")[1] "2021-11-17 12:11:59 UTC"Spezifikation der Zeitzone
![]()
Ist die Zeitzone nicht UTC (‘default’), spezifizieren Sie das tz Argument:
[1] "2021-11-17 12:11:00 CET" [1] "Africa/Abidjan" "Africa/Accra"
[3] "Africa/Addis_Ababa" "Africa/Algiers"
[5] "Africa/Asmara" "Africa/Asmera"
[7] "Africa/Bamako" "Africa/Bangui"
[9] "Africa/Banjul" "Africa/Bissau"
[11] "Africa/Blantyre" "Africa/Brazzaville"
[13] "Africa/Bujumbura" "Africa/Cairo"
[15] "Africa/Casablanca" "Africa/Ceuta"
[17] "Africa/Conakry" "Africa/Dakar"
[19] "Africa/Dar_es_Salaam" "Africa/Djibouti"
[21] "Africa/Douala" "Africa/El_Aaiun"
[23] "Africa/Freetown" "Africa/Gaborone"
[25] "Africa/Harare" "Africa/Johannesburg"
[27] "Africa/Juba" "Africa/Kampala"
[29] "Africa/Khartoum" "Africa/Kigali"
[31] "Africa/Kinshasa" "Africa/Lagos"
[33] "Africa/Libreville" "Africa/Lome"
[35] "Africa/Luanda" "Africa/Lubumbashi"
[37] "Africa/Lusaka" "Africa/Malabo"
[39] "Africa/Maputo" "Africa/Maseru"
[41] "Africa/Mbabane" "Africa/Mogadishu"
[43] "Africa/Monrovia" "Africa/Nairobi"
[45] "Africa/Ndjamena" "Africa/Niamey"
[47] "Africa/Nouakchott" "Africa/Ouagadougou"
[49] "Africa/Porto-Novo" "Africa/Sao_Tome"
[51] "Africa/Timbuktu" "Africa/Tripoli"
[53] "Africa/Tunis" "Africa/Windhoek"
[55] "America/Adak" "America/Anchorage"
[57] "America/Anguilla" "America/Antigua"
[59] "America/Araguaina" "America/Argentina/Buenos_Aires"
[61] "America/Argentina/Catamarca" "America/Argentina/ComodRivadavia"
[63] "America/Argentina/Cordoba" "America/Argentina/Jujuy"
[65] "America/Argentina/La_Rioja" "America/Argentina/Mendoza"
[67] "America/Argentina/Rio_Gallegos" "America/Argentina/Salta"
[69] "America/Argentina/San_Juan" "America/Argentina/San_Luis"
[71] "America/Argentina/Tucuman" "America/Argentina/Ushuaia"
[73] "America/Aruba" "America/Asuncion"
[75] "America/Atikokan" "America/Atka"
[77] "America/Bahia" "America/Bahia_Banderas"
[79] "America/Barbados" "America/Belem"
[81] "America/Belize" "America/Blanc-Sablon"
[83] "America/Boa_Vista" "America/Bogota"
[85] "America/Boise" "America/Buenos_Aires"
[87] "America/Cambridge_Bay" "America/Campo_Grande"
[89] "America/Cancun" "America/Caracas"
[91] "America/Catamarca" "America/Cayenne"
[93] "America/Cayman" "America/Chicago"
[95] "America/Chihuahua" "America/Ciudad_Juarez"
[97] "America/Coral_Harbour" "America/Cordoba"
[99] "America/Costa_Rica" "America/Coyhaique"
[101] "America/Creston" "America/Cuiaba"
[103] "America/Curacao" "America/Danmarkshavn"
[105] "America/Dawson" "America/Dawson_Creek"
[107] "America/Denver" "America/Detroit"
[109] "America/Dominica" "America/Edmonton"
[111] "America/Eirunepe" "America/El_Salvador"
[113] "America/Ensenada" "America/Fort_Nelson"
[115] "America/Fort_Wayne" "America/Fortaleza"
[117] "America/Glace_Bay" "America/Godthab"
[119] "America/Goose_Bay" "America/Grand_Turk"
[121] "America/Grenada" "America/Guadeloupe"
[123] "America/Guatemala" "America/Guayaquil"
[125] "America/Guyana" "America/Halifax"
[127] "America/Havana" "America/Hermosillo"
[129] "America/Indiana/Indianapolis" "America/Indiana/Knox"
[131] "America/Indiana/Marengo" "America/Indiana/Petersburg"
[133] "America/Indiana/Tell_City" "America/Indiana/Vevay"
[135] "America/Indiana/Vincennes" "America/Indiana/Winamac"
[137] "America/Indianapolis" "America/Inuvik"
[139] "America/Iqaluit" "America/Jamaica"
[141] "America/Jujuy" "America/Juneau"
[143] "America/Kentucky/Louisville" "America/Kentucky/Monticello"
[145] "America/Knox_IN" "America/Kralendijk"
[147] "America/La_Paz" "America/Lima"
[149] "America/Los_Angeles" "America/Louisville"
[151] "America/Lower_Princes" "America/Maceio"
[153] "America/Managua" "America/Manaus"
[155] "America/Marigot" "America/Martinique"
[157] "America/Matamoros" "America/Mazatlan"
[159] "America/Mendoza" "America/Menominee"
[161] "America/Merida" "America/Metlakatla"
[163] "America/Mexico_City" "America/Miquelon"
[165] "America/Moncton" "America/Monterrey"
[167] "America/Montevideo" "America/Montreal"
[169] "America/Montserrat" "America/Nassau"
[171] "America/New_York" "America/Nipigon"
[173] "America/Nome" "America/Noronha"
[175] "America/North_Dakota/Beulah" "America/North_Dakota/Center"
[177] "America/North_Dakota/New_Salem" "America/Nuuk"
[179] "America/Ojinaga" "America/Panama"
[181] "America/Pangnirtung" "America/Paramaribo"
[183] "America/Phoenix" "America/Port_of_Spain"
[185] "America/Port-au-Prince" "America/Porto_Acre"
[187] "America/Porto_Velho" "America/Puerto_Rico"
[189] "America/Punta_Arenas" "America/Rainy_River"
[191] "America/Rankin_Inlet" "America/Recife"
[193] "America/Regina" "America/Resolute"
[195] "America/Rio_Branco" "America/Rosario"
[197] "America/Santa_Isabel" "America/Santarem"
[199] "America/Santiago" "America/Santo_Domingo"
[201] "America/Sao_Paulo" "America/Scoresbysund"
[203] "America/Shiprock" "America/Sitka"
[205] "America/St_Barthelemy" "America/St_Johns"
[207] "America/St_Kitts" "America/St_Lucia"
[209] "America/St_Thomas" "America/St_Vincent"
[211] "America/Swift_Current" "America/Tegucigalpa"
[213] "America/Thule" "America/Thunder_Bay"
[215] "America/Tijuana" "America/Toronto"
[217] "America/Tortola" "America/Vancouver"
[219] "America/Virgin" "America/Whitehorse"
[221] "America/Winnipeg" "America/Yakutat"
[223] "America/Yellowknife" "Antarctica/Casey"
[225] "Antarctica/Davis" "Antarctica/DumontDUrville"
[227] "Antarctica/Macquarie" "Antarctica/Mawson"
[229] "Antarctica/McMurdo" "Antarctica/Palmer"
[231] "Antarctica/Rothera" "Antarctica/South_Pole"
[233] "Antarctica/Syowa" "Antarctica/Troll"
[235] "Antarctica/Vostok" "Arctic/Longyearbyen"
[237] "Asia/Aden" "Asia/Almaty"
[239] "Asia/Amman" "Asia/Anadyr"
[241] "Asia/Aqtau" "Asia/Aqtobe"
[243] "Asia/Ashgabat" "Asia/Ashkhabad"
[245] "Asia/Atyrau" "Asia/Baghdad"
[247] "Asia/Bahrain" "Asia/Baku"
[249] "Asia/Bangkok" "Asia/Barnaul"
[251] "Asia/Beirut" "Asia/Bishkek"
[253] "Asia/Brunei" "Asia/Calcutta"
[255] "Asia/Chita" "Asia/Choibalsan"
[257] "Asia/Chongqing" "Asia/Chungking"
[259] "Asia/Colombo" "Asia/Dacca"
[261] "Asia/Damascus" "Asia/Dhaka"
[263] "Asia/Dili" "Asia/Dubai"
[265] "Asia/Dushanbe" "Asia/Famagusta"
[267] "Asia/Gaza" "Asia/Harbin"
[269] "Asia/Hebron" "Asia/Ho_Chi_Minh"
[271] "Asia/Hong_Kong" "Asia/Hovd"
[273] "Asia/Irkutsk" "Asia/Istanbul"
[275] "Asia/Jakarta" "Asia/Jayapura"
[277] "Asia/Jerusalem" "Asia/Kabul"
[279] "Asia/Kamchatka" "Asia/Karachi"
[281] "Asia/Kashgar" "Asia/Kathmandu"
[283] "Asia/Katmandu" "Asia/Khandyga"
[285] "Asia/Kolkata" "Asia/Krasnoyarsk"
[287] "Asia/Kuala_Lumpur" "Asia/Kuching"
[289] "Asia/Kuwait" "Asia/Macao"
[291] "Asia/Macau" "Asia/Magadan"
[293] "Asia/Makassar" "Asia/Manila"
[295] "Asia/Muscat" "Asia/Nicosia"
[297] "Asia/Novokuznetsk" "Asia/Novosibirsk"
[299] "Asia/Omsk" "Asia/Oral"
[301] "Asia/Phnom_Penh" "Asia/Pontianak"
[303] "Asia/Pyongyang" "Asia/Qatar"
[305] "Asia/Qostanay" "Asia/Qyzylorda"
[307] "Asia/Rangoon" "Asia/Riyadh"
[309] "Asia/Saigon" "Asia/Sakhalin"
[311] "Asia/Samarkand" "Asia/Seoul"
[313] "Asia/Shanghai" "Asia/Singapore"
[315] "Asia/Srednekolymsk" "Asia/Taipei"
[317] "Asia/Tashkent" "Asia/Tbilisi"
[319] "Asia/Tehran" "Asia/Tel_Aviv"
[321] "Asia/Thimbu" "Asia/Thimphu"
[323] "Asia/Tokyo" "Asia/Tomsk"
[325] "Asia/Ujung_Pandang" "Asia/Ulaanbaatar"
[327] "Asia/Ulan_Bator" "Asia/Urumqi"
[329] "Asia/Ust-Nera" "Asia/Vientiane"
[331] "Asia/Vladivostok" "Asia/Yakutsk"
[333] "Asia/Yangon" "Asia/Yekaterinburg"
[335] "Asia/Yerevan" "Atlantic/Azores"
[337] "Atlantic/Bermuda" "Atlantic/Canary"
[339] "Atlantic/Cape_Verde" "Atlantic/Faeroe"
[341] "Atlantic/Faroe" "Atlantic/Jan_Mayen"
[343] "Atlantic/Madeira" "Atlantic/Reykjavik"
[345] "Atlantic/South_Georgia" "Atlantic/St_Helena"
[347] "Atlantic/Stanley" "Australia/ACT"
[349] "Australia/Adelaide" "Australia/Brisbane"
[351] "Australia/Broken_Hill" "Australia/Canberra"
[353] "Australia/Currie" "Australia/Darwin"
[355] "Australia/Eucla" "Australia/Hobart"
[357] "Australia/LHI" "Australia/Lindeman"
[359] "Australia/Lord_Howe" "Australia/Melbourne"
[361] "Australia/North" "Australia/NSW"
[363] "Australia/Perth" "Australia/Queensland"
[365] "Australia/South" "Australia/Sydney"
[367] "Australia/Tasmania" "Australia/Victoria"
[369] "Australia/West" "Australia/Yancowinna"
[371] "Brazil/Acre" "Brazil/DeNoronha"
[373] "Brazil/East" "Brazil/West"
[375] "Canada/Atlantic" "Canada/Central"
[377] "Canada/Eastern" "Canada/Mountain"
[379] "Canada/Newfoundland" "Canada/Pacific"
[381] "Canada/Saskatchewan" "Canada/Yukon"
[383] "CET" "Chile/Continental"
[385] "Chile/EasterIsland" "CST6CDT"
[387] "Cuba" "EET"
[389] "Egypt" "Eire"
[391] "EST" "EST5EDT"
[393] "Etc/GMT" "Etc/GMT-0"
[395] "Etc/GMT-1" "Etc/GMT-10"
[397] "Etc/GMT-11" "Etc/GMT-12"
[399] "Etc/GMT-13" "Etc/GMT-14"
[401] "Etc/GMT-2" "Etc/GMT-3"
[403] "Etc/GMT-4" "Etc/GMT-5"
[405] "Etc/GMT-6" "Etc/GMT-7"
[407] "Etc/GMT-8" "Etc/GMT-9"
[409] "Etc/GMT+0" "Etc/GMT+1"
[411] "Etc/GMT+10" "Etc/GMT+11"
[413] "Etc/GMT+12" "Etc/GMT+2"
[415] "Etc/GMT+3" "Etc/GMT+4"
[417] "Etc/GMT+5" "Etc/GMT+6"
[419] "Etc/GMT+7" "Etc/GMT+8"
[421] "Etc/GMT+9" "Etc/GMT0"
[423] "Etc/Greenwich" "Etc/UCT"
[425] "Etc/Universal" "Etc/UTC"
[427] "Etc/Zulu" "Europe/Amsterdam"
[429] "Europe/Andorra" "Europe/Astrakhan"
[431] "Europe/Athens" "Europe/Belfast"
[433] "Europe/Belgrade" "Europe/Berlin"
[435] "Europe/Bratislava" "Europe/Brussels"
[437] "Europe/Bucharest" "Europe/Budapest"
[439] "Europe/Busingen" "Europe/Chisinau"
[441] "Europe/Copenhagen" "Europe/Dublin"
[443] "Europe/Gibraltar" "Europe/Guernsey"
[445] "Europe/Helsinki" "Europe/Isle_of_Man"
[447] "Europe/Istanbul" "Europe/Jersey"
[449] "Europe/Kaliningrad" "Europe/Kiev"
[451] "Europe/Kirov" "Europe/Kyiv"
[453] "Europe/Lisbon" "Europe/Ljubljana"
[455] "Europe/London" "Europe/Luxembourg"
[457] "Europe/Madrid" "Europe/Malta"
[459] "Europe/Mariehamn" "Europe/Minsk"
[461] "Europe/Monaco" "Europe/Moscow"
[463] "Europe/Nicosia" "Europe/Oslo"
[465] "Europe/Paris" "Europe/Podgorica"
[467] "Europe/Prague" "Europe/Riga"
[469] "Europe/Rome" "Europe/Samara"
[471] "Europe/San_Marino" "Europe/Sarajevo"
[473] "Europe/Saratov" "Europe/Simferopol"
[475] "Europe/Skopje" "Europe/Sofia"
[477] "Europe/Stockholm" "Europe/Tallinn"
[479] "Europe/Tirane" "Europe/Tiraspol"
[481] "Europe/Ulyanovsk" "Europe/Uzhgorod"
[483] "Europe/Vaduz" "Europe/Vatican"
[485] "Europe/Vienna" "Europe/Vilnius"
[487] "Europe/Volgograd" "Europe/Warsaw"
[489] "Europe/Zagreb" "Europe/Zaporozhye"
[491] "Europe/Zurich" "Factory"
[493] "GB" "GB-Eire"
[495] "GMT" "GMT-0"
[497] "GMT+0" "GMT0"
[499] "Greenwich" "Hongkong"
[501] "HST" "Iceland"
[503] "Indian/Antananarivo" "Indian/Chagos"
[505] "Indian/Christmas" "Indian/Cocos"
[507] "Indian/Comoro" "Indian/Kerguelen"
[509] "Indian/Mahe" "Indian/Maldives"
[511] "Indian/Mauritius" "Indian/Mayotte"
[513] "Indian/Reunion" "Iran"
[515] "Israel" "Jamaica"
[517] "Japan" "Kwajalein"
[519] "Libya" "MET"
[521] "Mexico/BajaNorte" "Mexico/BajaSur"
[523] "Mexico/General" "MST"
[525] "MST7MDT" "Navajo"
[527] "NZ" "NZ-CHAT"
[529] "Pacific/Apia" "Pacific/Auckland"
[531] "Pacific/Bougainville" "Pacific/Chatham"
[533] "Pacific/Chuuk" "Pacific/Easter"
[535] "Pacific/Efate" "Pacific/Enderbury"
[537] "Pacific/Fakaofo" "Pacific/Fiji"
[539] "Pacific/Funafuti" "Pacific/Galapagos"
[541] "Pacific/Gambier" "Pacific/Guadalcanal"
[543] "Pacific/Guam" "Pacific/Honolulu"
[545] "Pacific/Johnston" "Pacific/Kanton"
[547] "Pacific/Kiritimati" "Pacific/Kosrae"
[549] "Pacific/Kwajalein" "Pacific/Majuro"
[551] "Pacific/Marquesas" "Pacific/Midway"
[553] "Pacific/Nauru" "Pacific/Niue"
[555] "Pacific/Norfolk" "Pacific/Noumea"
[557] "Pacific/Pago_Pago" "Pacific/Palau"
[559] "Pacific/Pitcairn" "Pacific/Pohnpei"
[561] "Pacific/Ponape" "Pacific/Port_Moresby"
[563] "Pacific/Rarotonga" "Pacific/Saipan"
[565] "Pacific/Samoa" "Pacific/Tahiti"
[567] "Pacific/Tarawa" "Pacific/Tongatapu"
[569] "Pacific/Truk" "Pacific/Wake"
[571] "Pacific/Wallis" "Pacific/Yap"
[573] "Poland" "Portugal"
[575] "PRC" "PST8PDT"
[577] "ROC" "ROK"
[579] "Singapore" "Turkey"
[581] "UCT" "Universal"
[583] "US/Alaska" "US/Aleutian"
[585] "US/Arizona" "US/Central"
[587] "US/East-Indiana" "US/Eastern"
[589] "US/Hawaii" "US/Indiana-Starke"
[591] "US/Michigan" "US/Mountain"
[593] "US/Pacific" "US/Samoa"
[595] "UTC" "W-SU"
[597] "WET" "Zulu"
attr(,"Version")
[1] "2025c"Wechseln zwischen den Formaten
![]()
Sie können zwischen beiden Formaten mit Hilfe von as_date() und as_datetime() wechseln (es kann aber sein, dass Informationen verloren gehen):
Datumskomponenten extrahieren
![]()
- Für Aggregationszwecke ist es häufig hilfreich individuelle Komponenten zu extrahieren.
- ‘lubridate’ hat folgende Helferfunktionen (alle haben einfach den Namen der Komponente, die extrahiert werden soll):
Your turn …
![]()
Quiz 3-5 | Datum & Zeit
![]()
![]()
Q3
Folgender Vektor des Datentyp ‘POSIXcl’ soll in den Datentyp ‘Date’ umgewandelt werden:
Q4
Folgender tibble enthält mehrere Datum- bzw. Datum/Zeit-Variablen, die aber alle als ‘character’ Datentyp vorliegen:
# A tibble: 10 × 5
x1 x2 x3 x4 x5
<chr> <chr> <chr> <chr> <chr>
1 2015-07-26 2015/26/07 Jul 26, 2015 2015-07-26 18:16:00 26.07.2015T18:16
2 2015-07-03 2015/03/07 Jul 03, 2015 2015-07-03 16:42:00 03.07.2015T16:42
3 2015-09-01 2015/01/09 Sep 01, 2015 2015-09-01 04:45:00 01.09.2015T04:45
4 2015-06-03 2015/03/06 Mar 03, 2015 2015-06-03 08:08:00 03.06.2015T08:08
5 2015-10-15 2015/15/10 Oct 15, 2015 2015-10-15 21:05:00 15.10.2015T21:05
6 2015-10-01 2015/01/10 Oct 01, 2015 2015-10-01 10:38:00 01.10.2015T10:38
7 2015-03-14 2015/14/03 Mar 14, 2015 2015-03-14 05:55:00 14.03.2015T05:55
8 2015-02-25 2015/25/02 Jun 25, 2015 2015-02-25 08:12:00 25.02.2015T08:12
9 2015-06-03 2015/03/06 Sep 03, 2015 2015-06-03 11:09:00 03.06.2015T11:09
10 2015-09-14 2015/14/09 Jul 14, 2015 2015-09-14 05:38:00 14.09.2015T05:38# A tibble: 10 × 5
x1 x2 x3 x4 x5
<date> <date> <date> <dttm> <dttm>
1 2015-07-26 2015-07-26 2015-07-26 2015-07-26 18:16:00 2015-07-26 18:16:00
2 2015-07-03 2015-07-03 2015-07-03 2015-07-03 16:42:00 2015-07-03 16:42:00
3 2015-09-01 2015-09-01 2015-09-01 2015-09-01 04:45:00 2015-09-01 04:45:00
4 2015-06-03 2015-06-03 2015-03-03 2015-06-03 08:08:00 2015-06-03 08:08:00
5 2015-10-15 2015-10-15 2015-10-15 2015-10-15 21:05:00 2015-10-15 21:05:00
6 2015-10-01 2015-10-01 2015-10-01 2015-10-01 10:38:00 2015-10-01 10:38:00
7 2015-03-14 2015-03-14 2015-03-14 2015-03-14 05:55:00 2015-03-14 05:55:00
8 2015-02-25 2015-02-25 2015-06-25 2015-02-25 08:12:00 2015-02-25 08:12:00
9 2015-06-03 2015-06-03 2015-09-03 2015-06-03 11:09:00 2015-06-03 11:09:00
10 2015-09-14 2015-09-14 2015-07-14 2015-09-14 05:38:00 2015-09-14 05:38:00Q5
Aus der Spalte x4 sollen nun folgende Komponenten extrahiert werden: Jahr, Monat, Monatstag, Stunde
# A tibble: 10 × 4
Jahr Monat Monatstag Stunde
<dbl> <dbl> <int> <int>
1 2015 7 26 18
2 2015 7 3 16
3 2015 9 1 4
4 2015 6 3 8
5 2015 10 15 21
6 2015 10 1 10
7 2015 3 14 5
8 2015 2 25 8
9 2015 6 3 11
10 2015 9 14 5Strings
Manipulation von Zeichenketten | 1
![]() Auch wenn Sie keine aufwendige Textanalyse vorhaben, kann es für Sie hilfreich sein Wissen über die Handhabung und Verarbeitung von Zeichenketten in R zu haben!
Auch wenn Sie keine aufwendige Textanalyse vorhaben, kann es für Sie hilfreich sein Wissen über die Handhabung und Verarbeitung von Zeichenketten in R zu haben!
Ein weiteres ‘tidyverse’ Paket
![]()
In ‘stringr’
- starten alle Funktionen mit
str_, so dass Sie schnell die entsprechende Funktion von der ‘dropdown’ Liste in RStudio auswählen können. - sind Argumentnamen (und deren Position) konsistent.
- behandeln alle Funktionen NA’s und Zeichen mit einer Länge von Null (““) entsprechend.
- entspricht die Struktur des Outputs jeder Funktion der Struktur des Inputs anderer Funktionen.
Strings modifizieren | 1
![]()
Schreibweise ändern
str_to_lower()
→ Umwandlung zu Kleinbuchstabenstr_to_upper()
→ Umwandlung zu Großbuchstabenstr_to_sentence()
→ erster Buchstabe großstr_to_title()
→ Anfangsbuchstabe jedes Wortes groß
[1] "the difference" "between stupidity" "and genius is that"
[4] "genius has its limits."[1] "THE DIFFERENCE" "BETWEEN STUPIDITY" "AND GENIUS IS THAT"
[4] "GENIUS HAS ITS LIMITS."[1] "The difference" "Between stupidity" "And genius is that"
[4] "Genius has its limits."[1] "The Difference" "Between Stupidity" "And Genius Is That"
[4] "Genius Has Its Limits."Strings modifizieren | 2
![]()
Anwendungsbeispiel
Strings modifizieren | 3
![]()
Leerzeichen entfernen
str_trim()→ Entfernt ‘white space’ am Anfang und Ende einer Zeichenkette.
'data.frame': 34 obs. of 3 variables:
$ station : chr "ER1 " "ER2 " "ER3 " "ER4 " ...
$ zinc : chr "BACK " "HIGH " "HIGH " "MEDIUM " ...
$ diversity: num 2.27 1.25 1.15 1.62 1.7 0.63 2.05 1.98 1.04 2.19 ...[1] "BACK " "HIGH " "MEDIUM " "LOW "[1] "BACK" "HIGH" "MEDIUM" "LOW" Strings kombinieren & nach Position auswählen
![]()
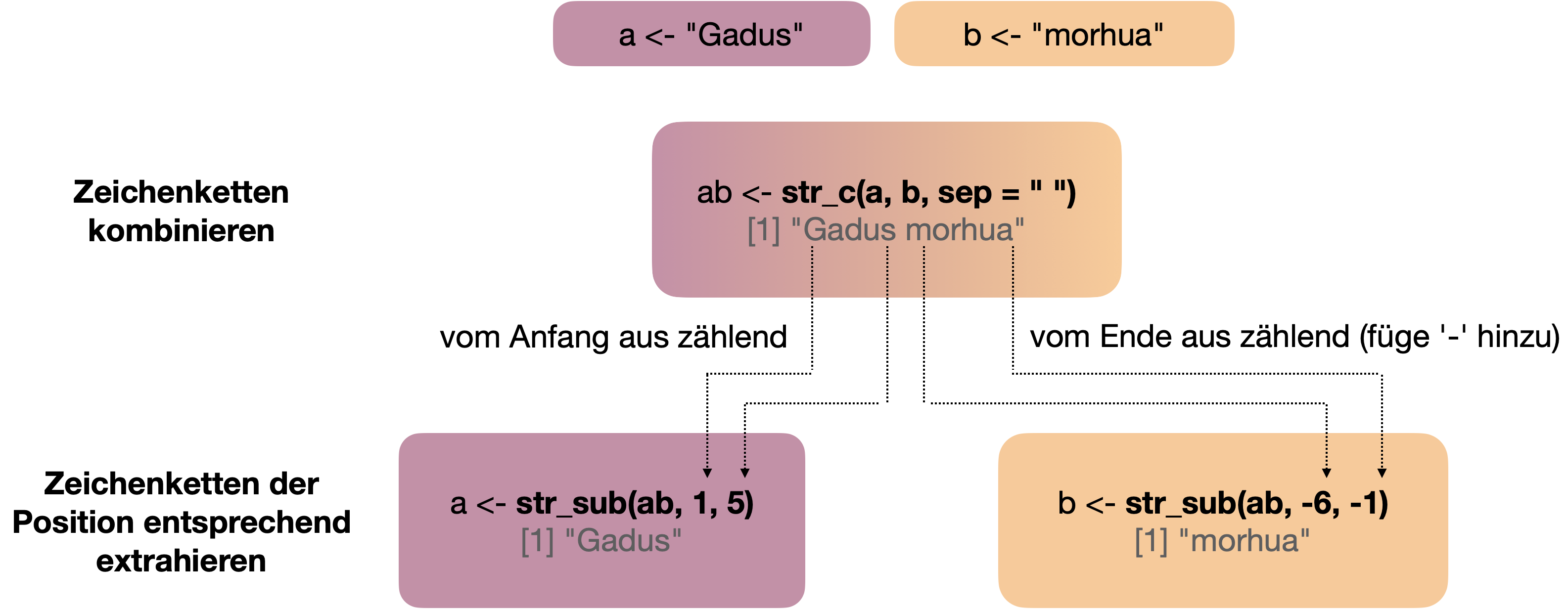
Strings kombinieren | 1
![]()
str_c(..., sep = "", collapse = NULL)→ Fügt 2 oder mehr Skalare oder Vektoren (egal welcher Datentyp!) elementweise zu einem einzigen Zeichenvektor bzw. Zeichenkette (!) zusammen.- sep → Optionales Trennzeichen zwischen den einzelnen zu verkettenden Elementen.
- collapse → Trennzeichen zwischen den Elementen des Output Vektors unter weiterer Verkettung zu einem einzigen string.
[1] "A + B"[1] "The difference between stupidity and genius is that genius has its limits."[1] "A.1, B.2, C.3"Strings kombinieren | 2
![]()
Anwendungsbeispiel 1
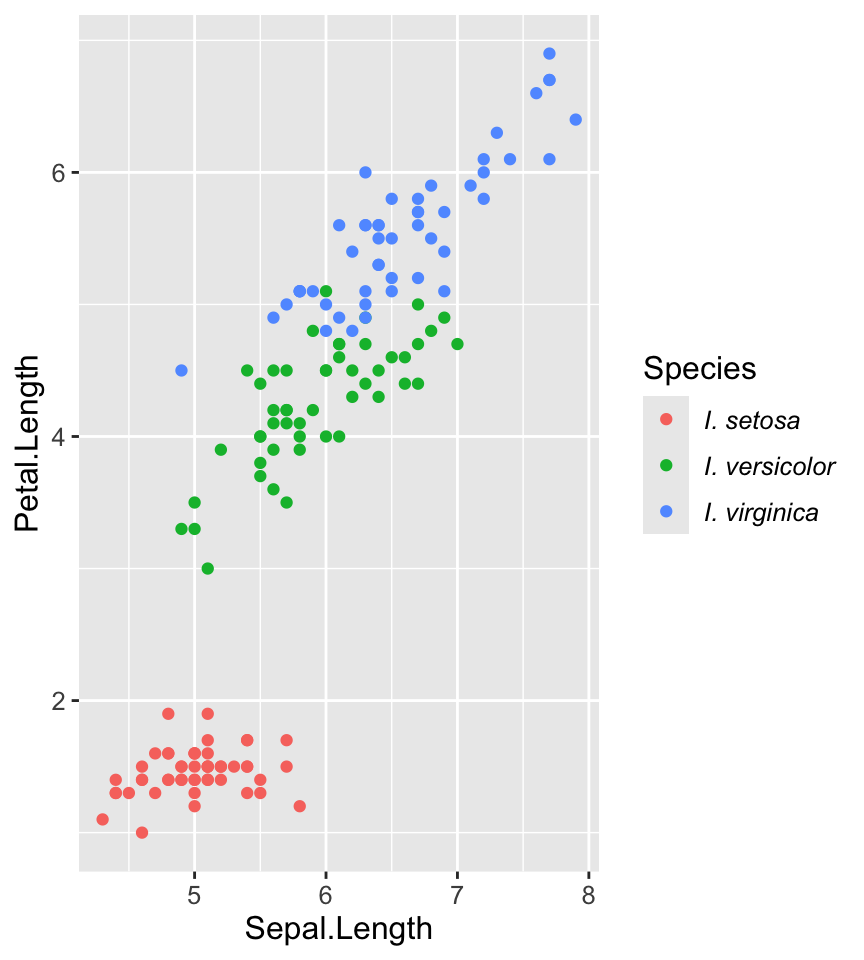
Strings kombinieren | 3
![]()
Anwendungsbeispiel 2
Deskriptive Statistiktabelle
iris |> mutate(
Species = str_c("Iris ", Species)) |>
group_by(Species) |>
summarise(
slm = round(mean(Sepal.Length), 1),
sls = round(sd(Sepal.Length), 2),
slms = str_c(slm, sls, sep=" ± ")
) |>
select(Species, slms) |>
knitr::kable(
col.names = c("Species",
"Mean Sepal Length (± st.dev)")
) # erstellt Tabellen in LaTeX, HTML| Species | Mean Sepal Length (± st.dev) |
|---|---|
| Iris setosa | 5 ± 0.35 |
| Iris versicolor | 5.9 ± 0.52 |
| Iris virginica | 6.6 ± 0.64 |
Nach Position auswählen/ersetzen | 1
![]()
str_sub(string, start, end)→ Extrahiert und ersetzt Teilzeichenketten aus einem Zeichenvektor.- start → Optionale Position des ersten Zeichens der zu extrahierenden Teilzeichenketten.
- end → Optionale Position des letzten Zeichens. Negative Werte zählen von hinten.
Nach Position auswählen/ersetzen | 2
![]()
Anwendungsbeispiele
Muster in Zeichenketten
![]()
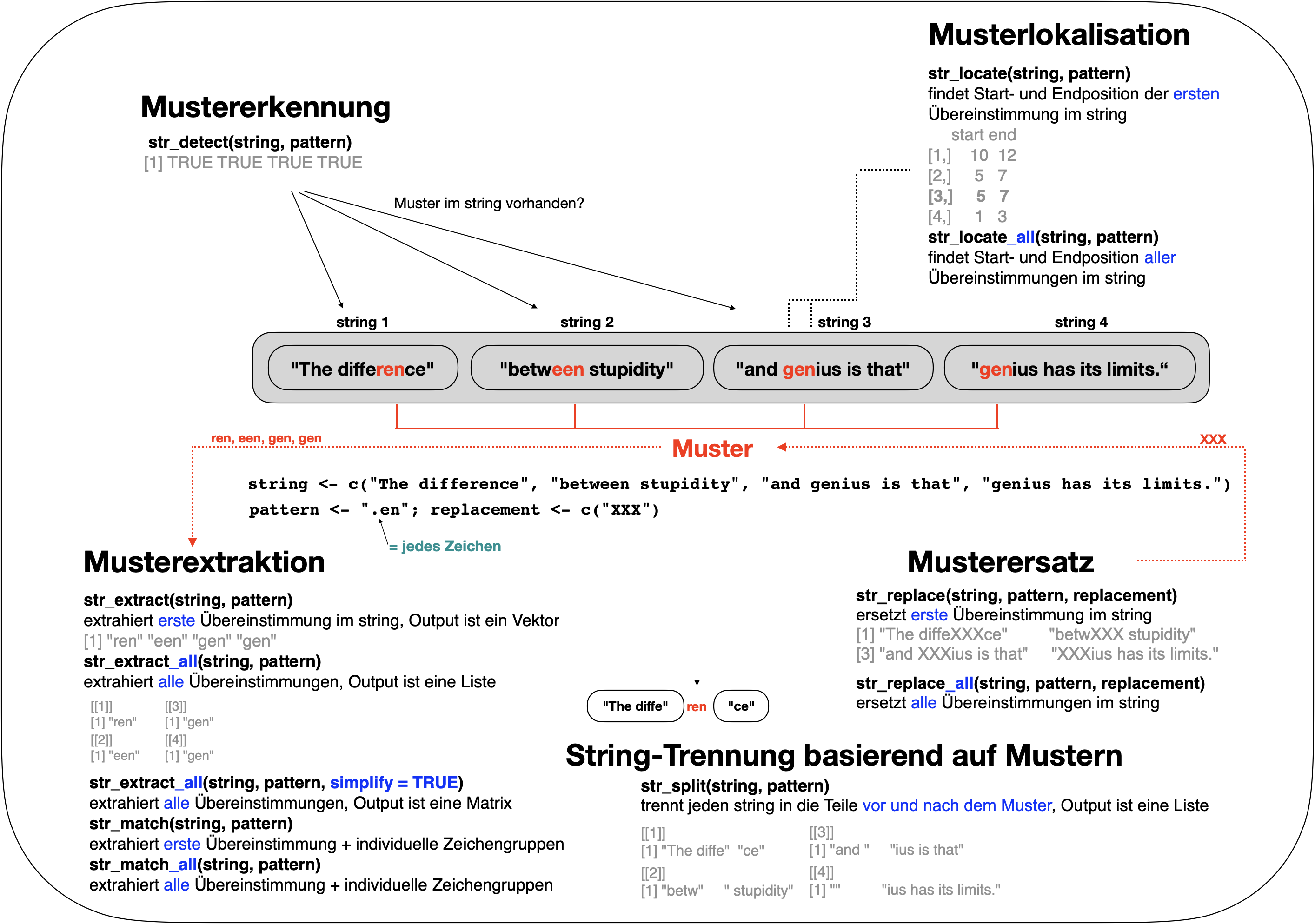
Muster finden | str_detect()
![]()
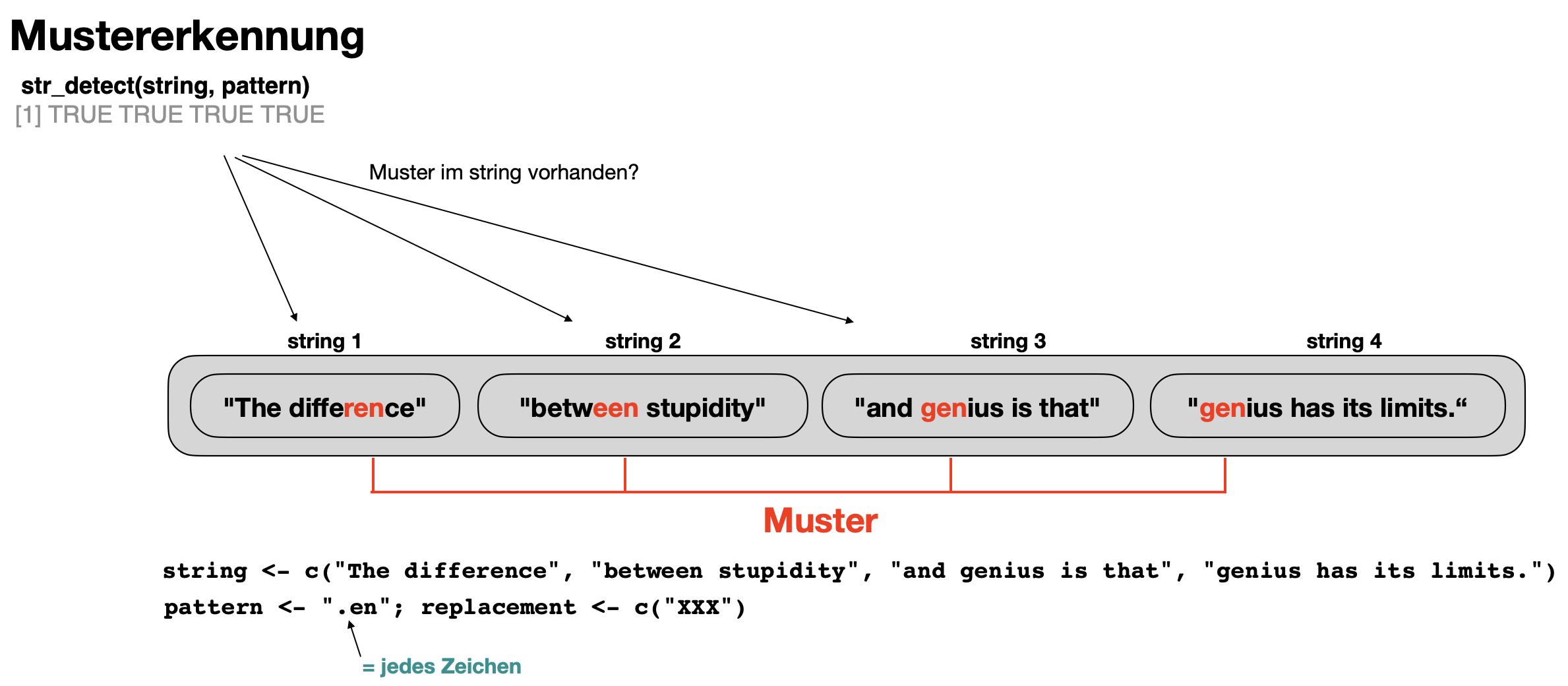
str_detect(string, pattern)→ Identifiziert Zeichenketten, die ein bestimmtes Muster haben, und gibt einen logischen Vektor zurück.
Überblick der regulären Ausdrücke
- Einige der Funktionen benötigen reguläre Ausdrücke (‘regex’ oder ‘regexpr’), die eine kurze und prägnante Sprache zur Beschreibung von Mustern in Zeichenketten sind.
- Um mehr über ‘regex’ zu lernen, empfehle ich die Webseite www.regular-expressions.info, welche viele Beispiele und Tutorials für Einsteiger und Fortgeschrittene bereitstellt.
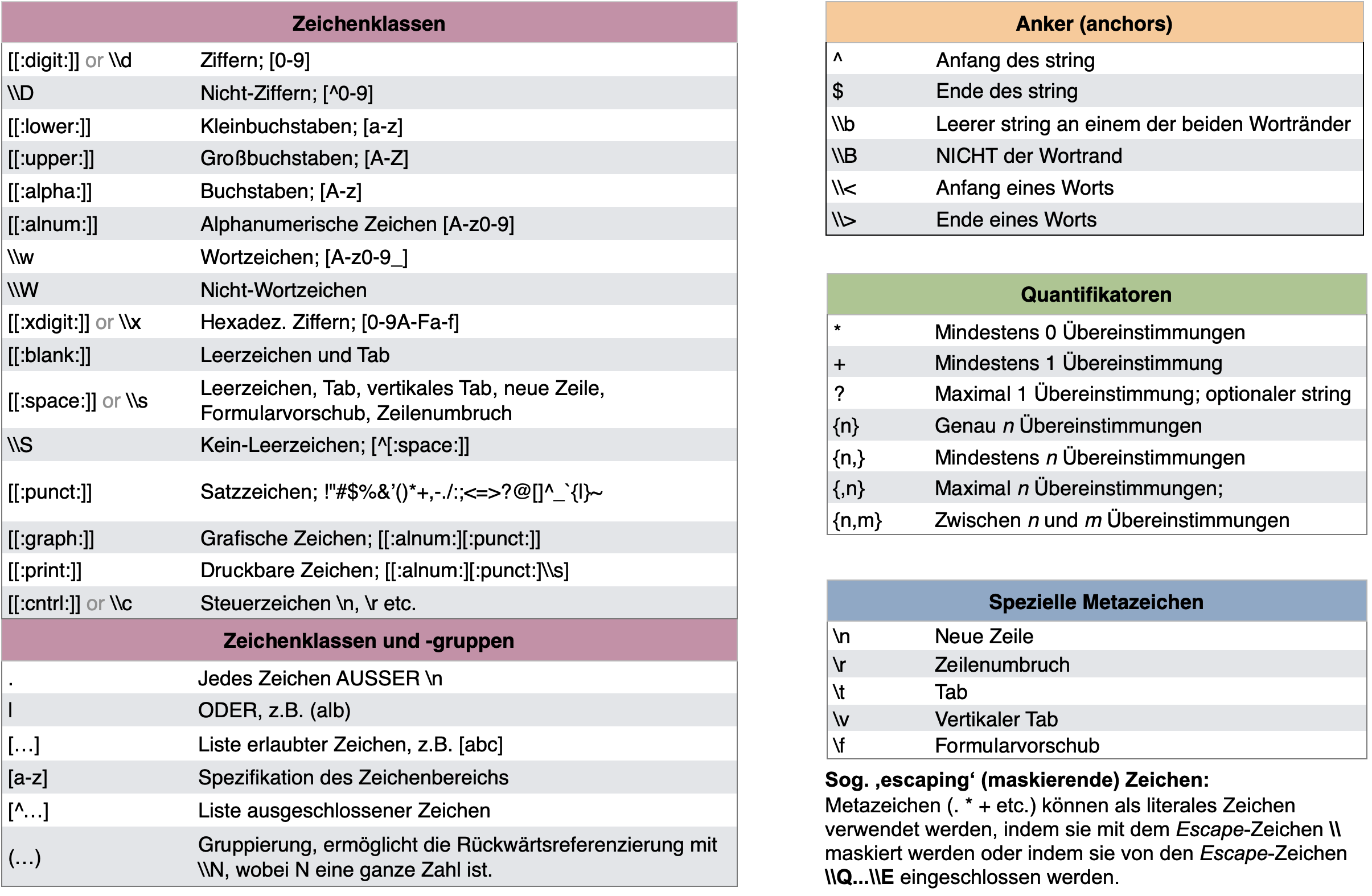
Adaptiert vom RegEx cheatsheet von Ian Kopacka.
Muster austauschen | str_replace()
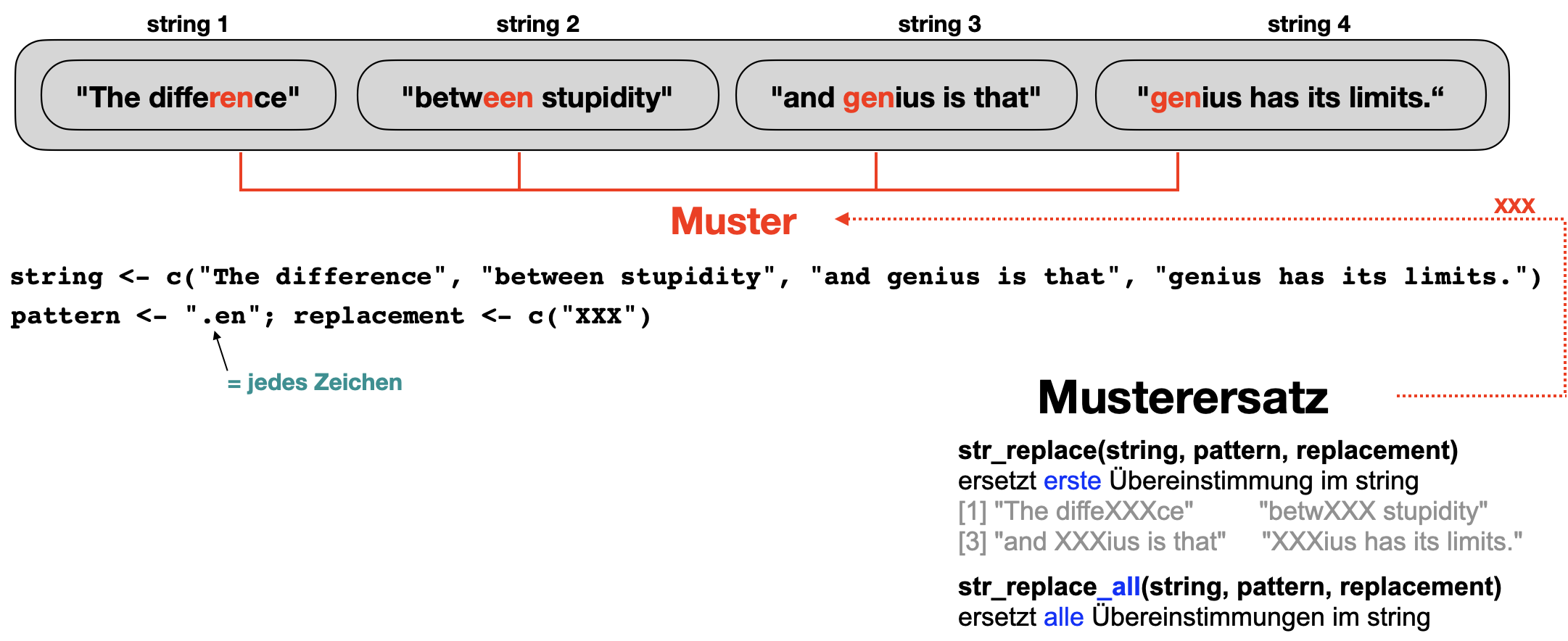
Nach Muster aufteilen | 1
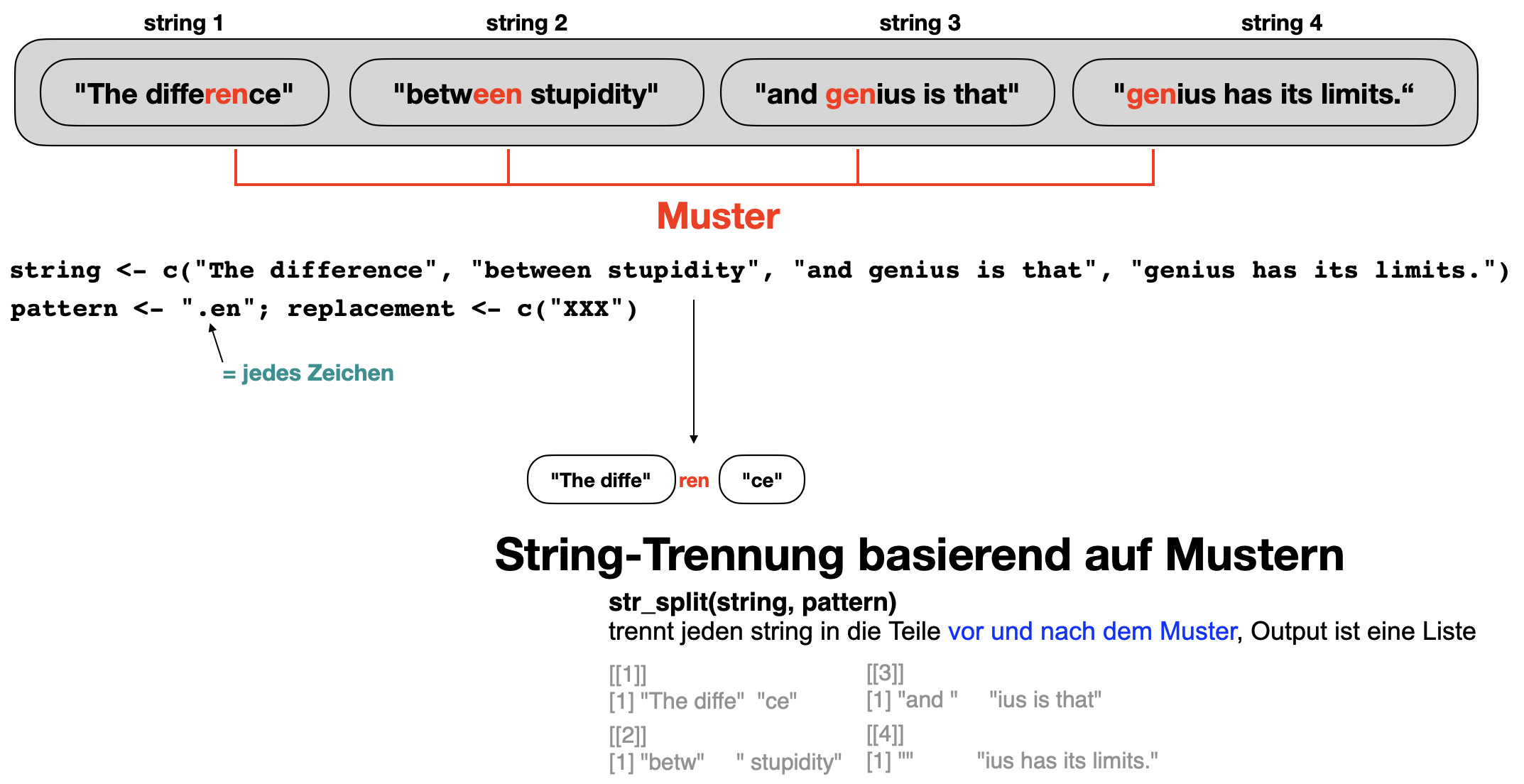
Your turn …
![]()
Quiz 6-8 | Strings
![]()
![]()
Q6
[1] "Placement in the"
[2] "genus is provisional pending"
[3] "the discovery of juvenile specimens."Q7
Q8
Übungsaufgabe
Optionale swirl-Lektionen zur Vertiefung
![]()
Kurs DS1-05-Handling spezieller Datentypen
- L01-Faktoren
- L02-Faktoren_und_das_forcats_Paket
- L03-Datum_und_Zeit_in_R
- L04-Datum_Zeit_und_das_lubridate_Paket
- L05-Grundfunktionen_zur_Textmanipulation
- L06-Zeichenketten_und_das_stringr_Paket
- L07-Textmanipulation_und_regulaere_Ausdruecke
Übungsskripte
![]()
- Schauen Sie sich das VL-begleitende R Skript an und experimentieren Sie mit den Einstellungen: DS1_W13_Vorlesungsskript_Handhabung_spezieller_Datentypen.R
Fallstudie

Sie sind jetzt so weit, …
- ..probieren Sie doch einige der Funktionen zu Faktoren und Zeichenkettenmanipulation in Ihrer Fallstudie aus.
Wie fühlen Sie sich jetzt…?

Total konfus?

Dann empfehle ich Ihnen:
- Lesen Sie Kapitel 15 über Faktoren in ‘R for Data Science’.
- Um mehr über die Funktionen zu lernen, die ‘lubridate’ bietet, lesen Sie die Vignette oder Kapitel 16 in ‘R for Data Science’.
- Kapitel 14 über strings ist lesenswert und mit guten Übungen versehen, um reguläre Ausdrücke zu üben; ebenso die Webseite https://www.regular-expressions.info.
- Sehen Sie sich auch die Posit/RStudio Cheatsheets an, um einen Überblick über die Funktionen zu bekommen:
Total gelangweilt?

Dann testen Sie doch Ihr Wissen in folgendem Abschlussquiz…
Abschlussquiz
![]()
Bei weiteren Fragen: saskia.otto(at)uni-hamburg.de

Diese Arbeit is lizenziert unter einer Creative Commons Attribution-ShareAlike 4.0 International License mit Ausnahme der entliehenen und mit Quellenangabe versehenen Abbildungen.