Grundlagen in R:
Variablen und Vektoren
Data Science 1 - Programmieren & Visualisieren
Universität Hamburg, IMF
Wintersemester 2025/2026
Lernziele
![]()
Am Ende dieser VL- und Übungseinheit werden Sie
- einen ersten Eindruck für eine deskriptive statistische Analyse in R bekommen haben.
- das erste der 4 Grundelemente (Variablen) in R kennen und beherrschen.
- Datentypen abfragen und umwandeln können.
- Vektoren und Zahlenfolgen in R erstellen können.
- Vektoren indexieren und mittels Operatoren filtern können.
- den Unterschied zwischen Zuweisungs- Vergleichs- und Verknüpfungsoperatoren kennen.
Grundelement - Variablen
Variablen | Die globale Umgebung
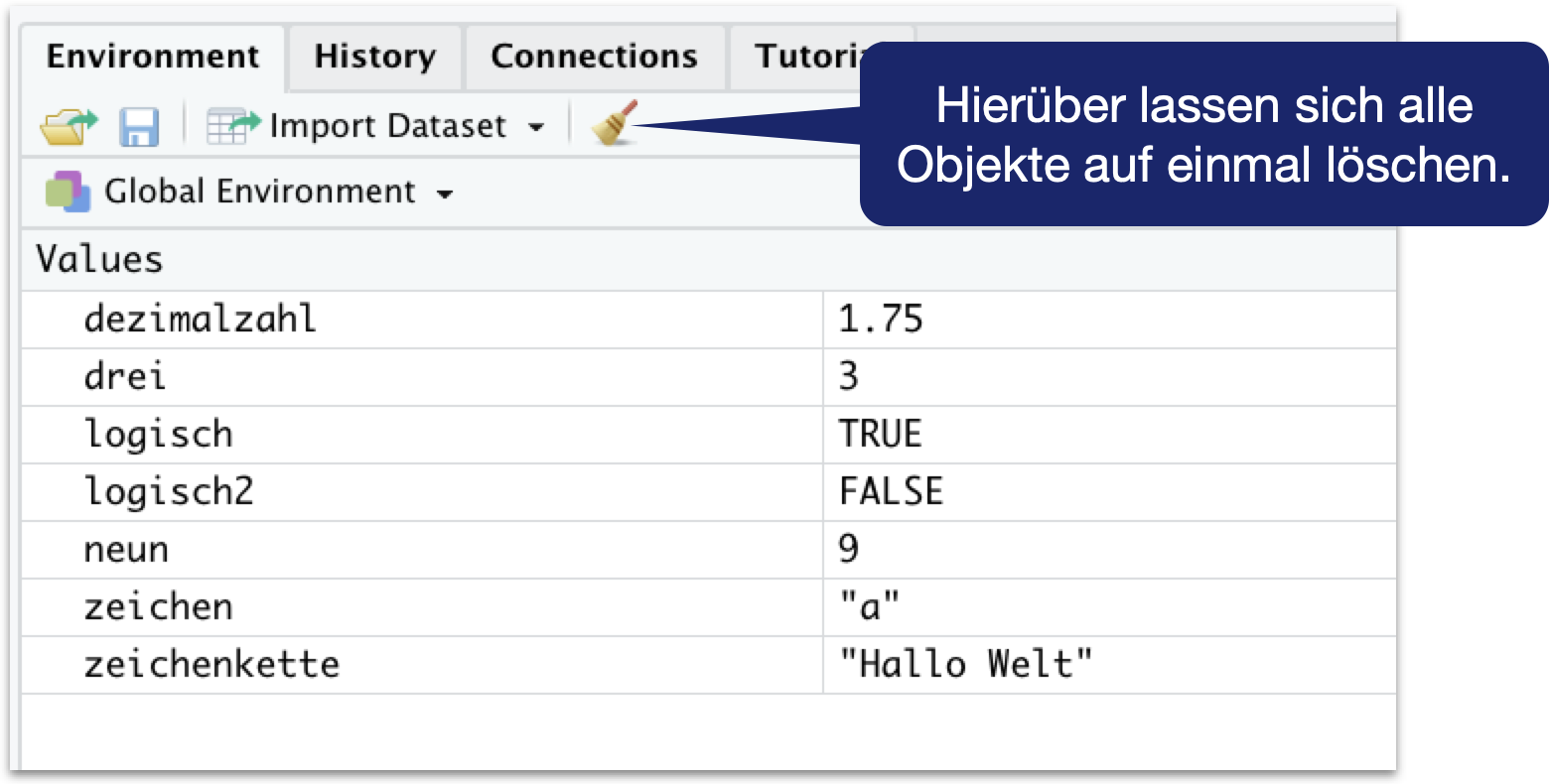
- Variablen, Objekte und Funktionen, die Sie in R generieren, erscheinen im Environment Reiter unter Global Environment.
- Die globale Umgebung ist der erste Ort des Suchverzeichnisses von R und stellt Ihren aktuellen Arbeitsbereich dar.
- Dieser Arbeitsbereich wird mit jedem Schließen von R/RStudio gelöscht (es sei denn Sie verwenden ein RStudio Projekt und speichern es explizit).
Your turn …
![]()
Quiz 1 | Zuweisungen
![]()
Quiz 2 | Zuweisungen
![]()
Quiz 3 | Datentypen
![]()
Bevor auf my_value in Zeile 2 zugegriffen werden kann, muss das Skalar erstmal definiert werden. Dies geschieht mit dem Zuweisungsoperator (<-).
Anschl. muss eine Funktion aufgerufen werden, die einen logischen Wert zurückgibt. Dies kann nur eine der is.xxx Funktionen sein. Welchen Datentyp könnte ‘A1’ haben?
Die einfachste Struktur: Vektoren
Your turn …
![]()
Quiz 4 | Vektoren erstellen
![]()
Quiz 5 | Vektoren erstellen
![]()
Vektorregeln
4. Indexierung | Über die Position 1
![]()
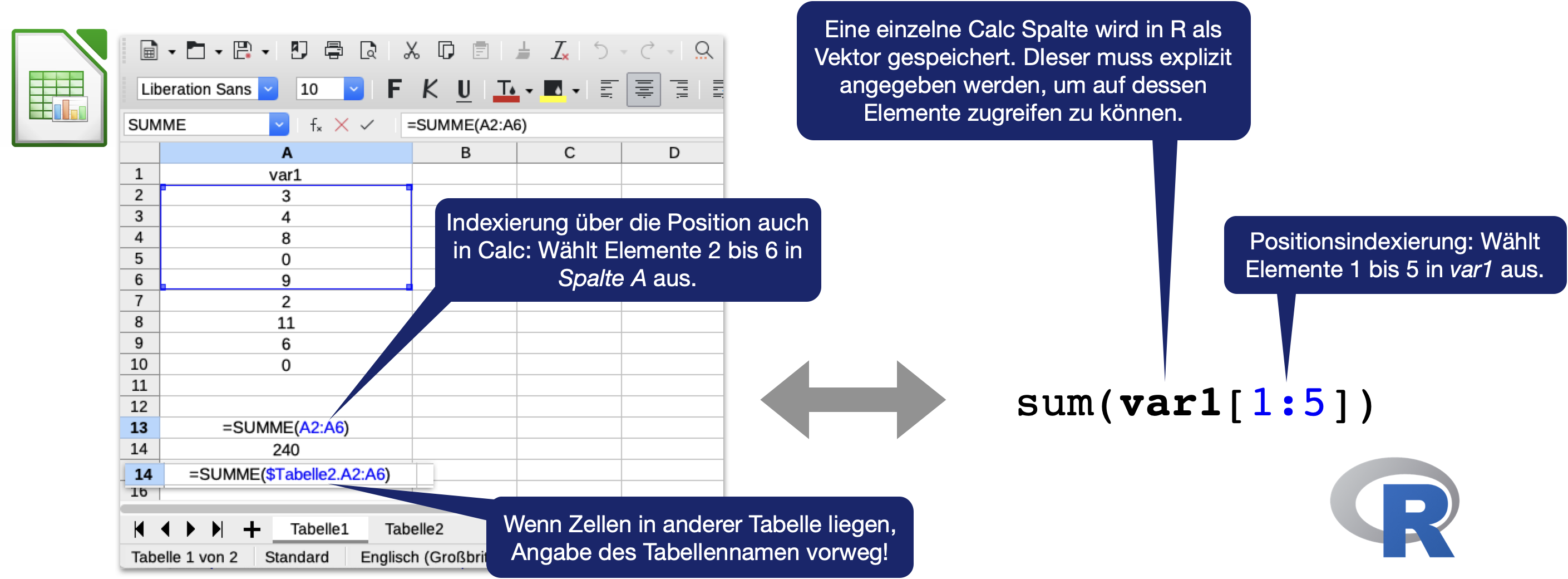
Die Positionsangabe erfolgt über eine Ganzzahl oder einen numerischen Vektor mit Ganzzahlen. Der Index startet immer mit 1.
[1] "zwei"[1] "eins" "drei" "vier" "fünf"[1] "fünf" "eins" "drei"[1] "zwei" "vier"[1] "eins" "zwei" "drei"[1] "drei" "zwei" "eins"[1] "eins" "eins" "zwei" "zwei" "drei" "drei" "drei" "drei"4. Indexierung | Über die Position 2
Calc vs. R
Your turn …
![]()
Quiz 6 | ‘Coercion’-Regel
![]()
Quiz 7 | Recycling-Regel
![]()
Quiz 8 | Indexierung
![]()
Ein Vektor x enthält 20 verschiedene Elemente.
Operatoren
Nützliche Operatoren für Abfragen
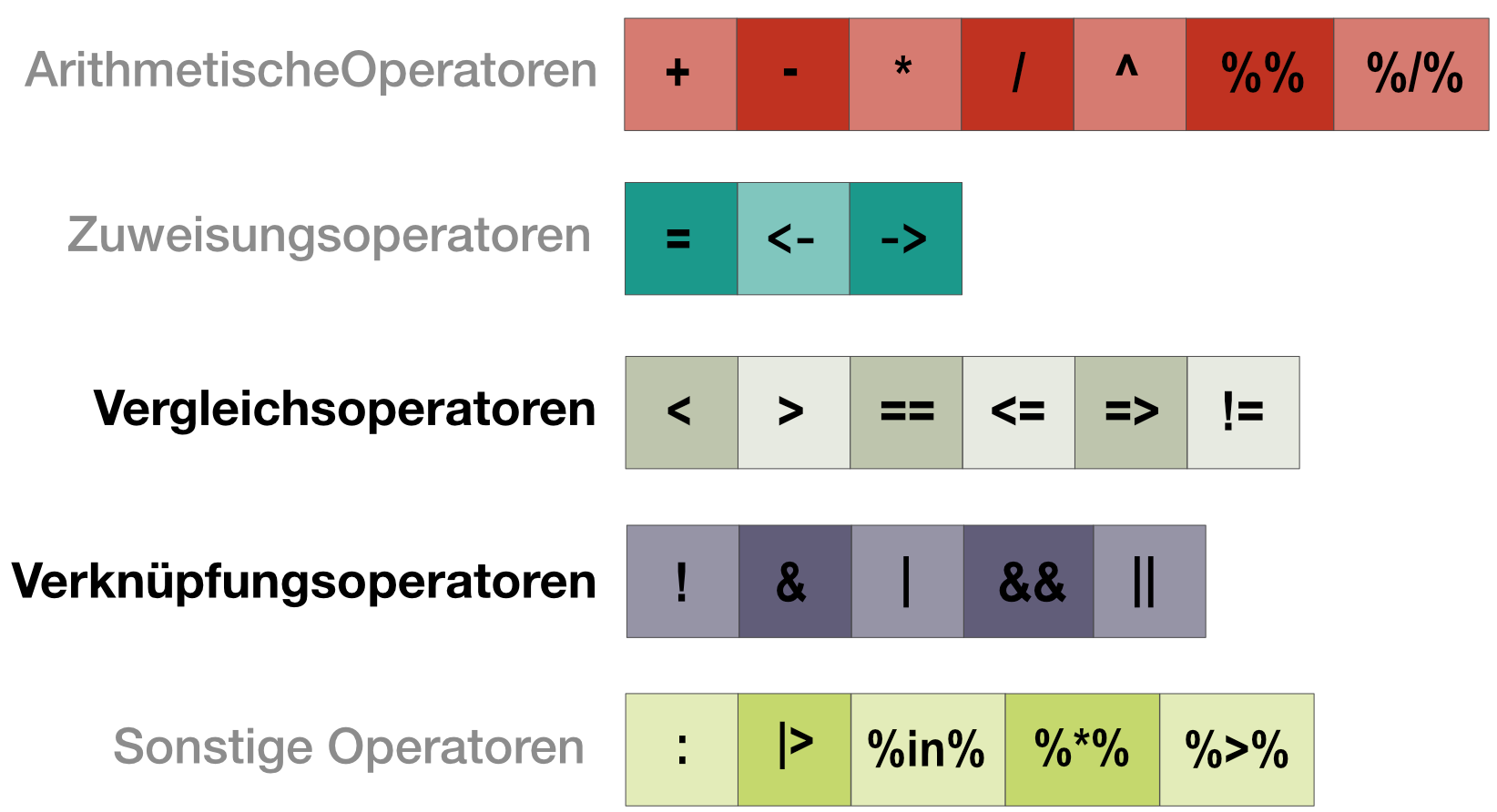
Vergleichs- und Verknüpfungsoperatoren geben immer einen logischen Wert (TRUE oder FALSE) zurück.
Vergleichsoperatoren
Im Englischen ‘relational operators’

| Operator | Anwendung | Beschreibung |
|---|---|---|
| < | a < b | a ist KLEINER als b |
| > | a > b | a ist GRÖSSER als b |
| == | a == b | a ist GLEICH wie b |
| <= | a <= b | a ist KLEINER als oder GLEICH wie b |
| >= | a >= b | a ist GRÖSSER als oder GLEICH wie b |
| != | a!=b | a ist NICHT GLEICH wie b |
Verknüpfungsoperatoren
Im Englischen ‘logical operators’

| Operator | Anwendung | Beschreibung |
|---|---|---|
| & | a & b | Elementweise UND Operation (arbeiten mit Vektoren) |
| | | a | b | Elementweise ODER Operation (arbeiten mit Vektoren) |
| ! | !a | Elementweise NICHT Operation (arbeiten mit Vektoren) |
Verknüpfungsoperatoren | 2
‘Regenschirm-Logik’
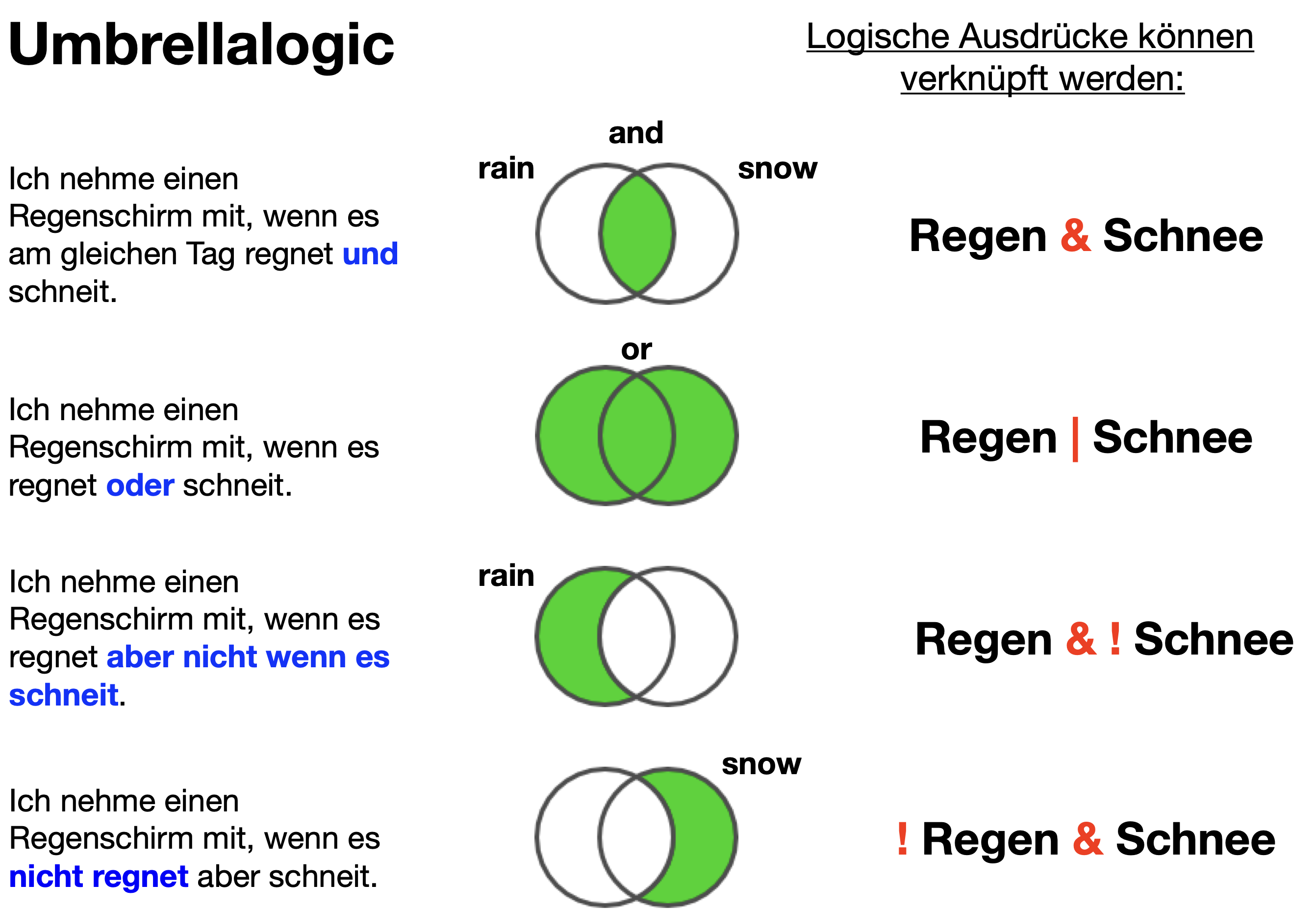
Vektorisierte Operationen in R
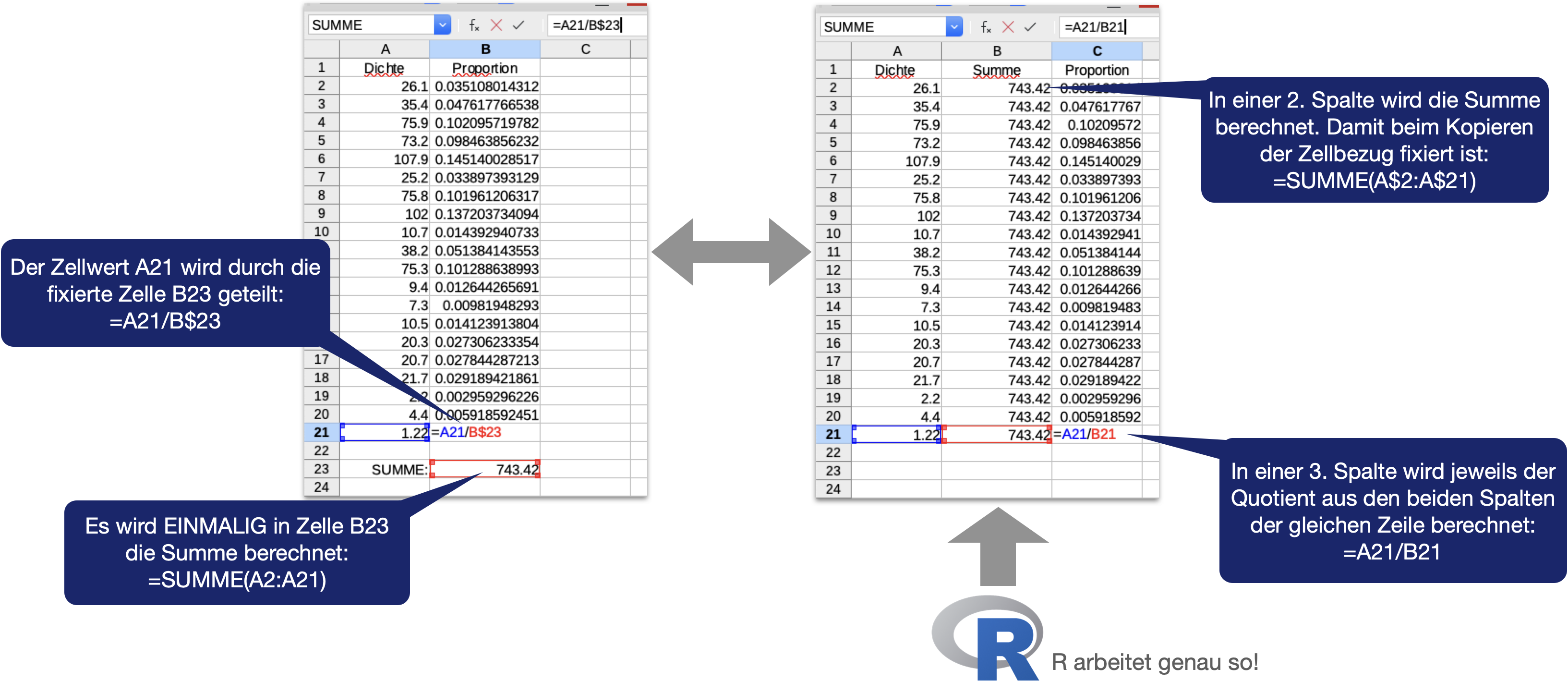
Calc vs. R | Bsp. proportionaler Anteil 1
Spinnendichte im Golf von Kalifornien
Gegeben ist eine Messreihe der Spinnendichte (\(no./m^2\)) auf verschiedenen Inseln im Golf von Kalifornien aus dem Jahre 1992 (aus Studie von Polis et al., 1998).

Calc vs. R | Bsp. proportionaler Anteil 2
Nun soll der proportionale Anteil der Dichte pro Insel berechnet werden: \(p_i=\frac{d_i}{\sum(d_i)}\)
In Calc gäbe es 2 Ansätze
Übungsaufgabe
Zu bearbeitende swirl-Lektionen
![]()
Kurs DS1-01-R Grundlagen
- L08-Atomare Vektoren als einfachster Objekttyp
- L09-Zahlenfolgen
- L10-Verhalten von Vektoren
- L11-Vektorindexierung
- L12-Filtern von Vektoren
Wie fühlen Sie sich jetzt…?

Total konfus?

Keine Sorge…
… im swirl-Kurs werden Sie direkt an die Hand genommen und Stück für Stück angeleitet.
Total gelangweilt?

Dann testen Sie doch Ihr Wissen in folgendem Abschlussquiz…
Abschlussquiz
![]()
Abschlussquiz
![]()
1 | Zuweisungen
Die Variable n in der letzten Operation wurde vorher nicht definiert. Daher muss sich die vorherige Zuweisung auf diese Variable beziehen. Auch y wurde vorher nicht definiert, daher kann es sich beim ‘Grösser’-Zeichen in in der letzten Zeile nicht um einen Vergleichsoperator handeln, sondern muss der erste Teil des Zuweisungsoperators sein.
2 | ‘Coercion’-Regel
Eine Zeichenkette (in diesem Fall ‘a’) hat keine korrespondierende Zahl, in die es umgewandelt werden kann. Dagegen kann eine Zahl einfach in eine Zeichenkette umgewandelt werden.
3 | ‘Coercion’-Regel
In diesem Fall ist 1 klar als ‘integer’ definiert, daher wird das TRUE zum ‘integer’ umgewandelt.
4 | ‘Coercion’-Regel
Alle TRUEs werden zu 1 umgewandelt und alle FALSEs zu 0. Summiere einfach den Vektor mit der sum() Funktion: sum(x)
5 - Challenge
Wie könnten alle NAs in einem Vektor x mit sehr vielen Elementen schnell ermittelt werden?
Zuerst wird mit der is.na() Funktion bei jedem Element abgefragt, ob es sich um ein NA handelt oder nicht.
Anschließend kann mit dem zurückgegebenen logischen Vektor die Summe aller TRUEs berechnet werden - denn R wandelt bei mathematischen Operationen von logischen Werten alle FALSEs in eine 0 um und alle TRUEs in eine 1!
6 | Indexierung
Ein Vektor x enthält 20 verschiedene Elemente.
7 | Indexierung
Ein Vektor x enthält 20 verschiedene Elemente.
8 | Indexierung
Ein Vektor vec enthält mehrere Zahlen.
Wir nutzen dazu den Modulo-Operator, welcher eine Restwert-Division zweier Elemente ausführt. Bei der Restwert-Division von 43 (Dividend) durch 5 (Divisor) wird z.B. gefragt, wie man die Zahl 43 als Vielfaches von 5 und einem kleinen Rest darstellen kann: \(43=5*c+r\) In diesem Beispiel wäre die 4 der sog. Ganzzahlquotient c und die 3 der Restwert r.
Ein Rest ungleich 0 ergibt sich folglich genau dann, wenn der Dividend kein Vielfaches des Divisors ist. Man sagt auch: Der Dividend ist nicht durch den Divisor teilbar, weshalb ein Rest übrigbleibt.
Dies können wir uns zunutze machen, indem wir als Divisor die 2 nehmen. Wenn kein Restbetrag übrig bleibt, muss der Dividend gerade sein!
9 | Indexierung
Ein Vektor vec enthält mehrere Zahlen.
10 | Indexierung
Ein numerischer Vektor nvec enthält eine unbekannte Anzahl an Elementen.
Abschlussquiz 11 | Indexierung
12 | Vektorisierte Berechnung
Der kürzere Vektor 1:3 wird durch das recyceln der eigenen Werte auf die gleiche Länge wie der erste Vektor gebracht (=6): c(1,2,3,1,2,3).
Nun wird das 5. Element (=2) mit dem 5.Element des 1. Vektors (=10) multipliziert.
13 | Vektorisierte Berechnung
Zur Erinnerung die Formel der Varianz: \(s^{2} = \frac{\sum\limits_{i=1}^{n} \left(x_{i} - \bar{x}\right)^{2}} {n-1}\)
df im Quiz steht für ‘degrees of freedom’, was im Deutschen die Freiheitsgrade sind. Und die betragen bei der Varianz n-1 (die Stichprobengröße oder Länge des Vektors minus 1).
Bei der Teilanweisung x-mean_x wird der eine Wert in mean_x auf die Länge von x recycelt. Anschl. wird der 1. Wert in mean_x vom 1. Wert in x, abgezogen, dann der zweite Wert, etc.
Das Ergebnis ist ein Vektor der gleichen Länge wie x mit den Differenzen, die anschl. quadriert und aufsummiert werden.
[1] 1268.611
Bei weiteren Fragen: saskia.otto(at)uni-hamburg.de

Diese Arbeit is lizenziert unter einer Creative Commons Attribution-ShareAlike 4.0 International License mit Ausnahme der entliehenen und mit Quellenangabe versehenen Abbildungen.