
Datenanalyse mit R
4 - Data wrangling - 1.Import
Saskia A. Otto
BSH 11/02 - 13/02 2019
Data wrangling mit tidyverse
Data wrangling ist
- ein Konzept, welches von Hadley Wickam eingeführt wurde
- die Kunst, Daten in R so zu laden und umzuformen, dass damit leicht die anschl. Visualisierung und Modellierung erfolgen kann
- besteht aus drei Hauptkompontenen:
Data wrangling ist
- ein Konzept, welches von Hadley Wickam eingeführt wurde
- die Kunst, Daten in R so zu laden und umzuformen, dass damit leicht die anschl. Visualisierung und Modellierung erfolgen kann
- besteht aus drei Hauptkomponenten:
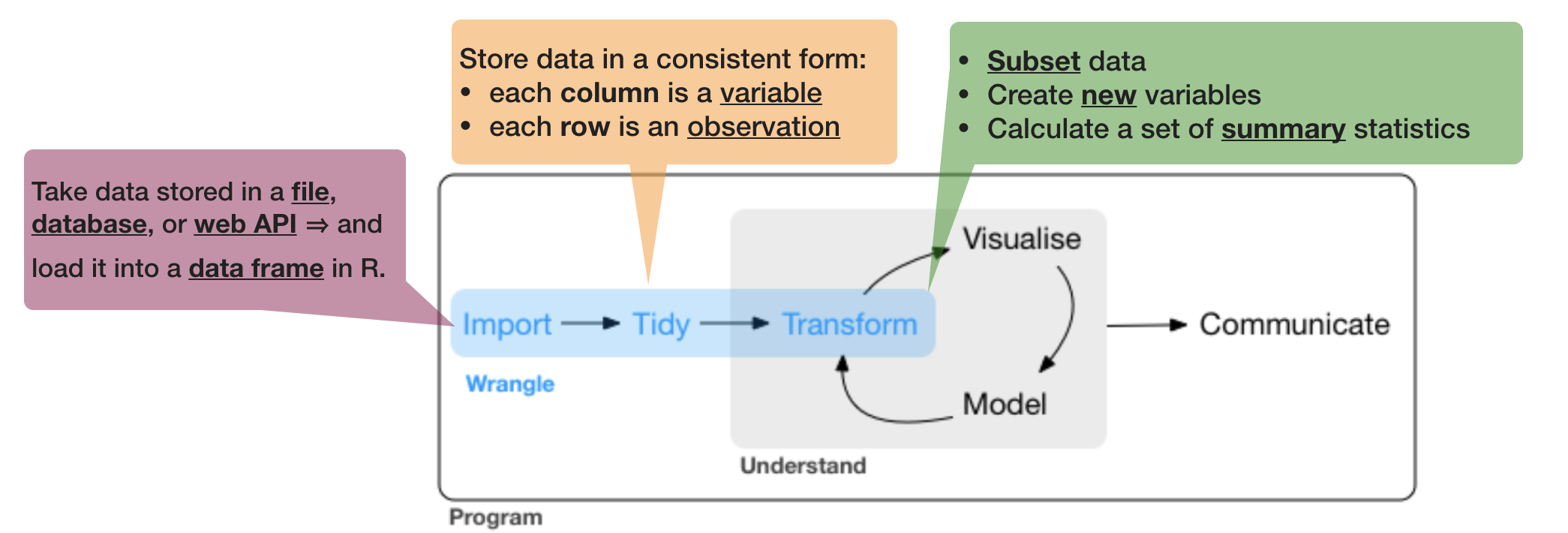
Quelle: R for Data Science von Wickam & Grolemund, 2017 (lizensiert unter CC-BY-NC-ND 3.0 US)
Tidy (uni)verse
Ist eine Sammlung von R Paketen die die gleiche Philosophie teilen und auf einander abgestimmt sind:
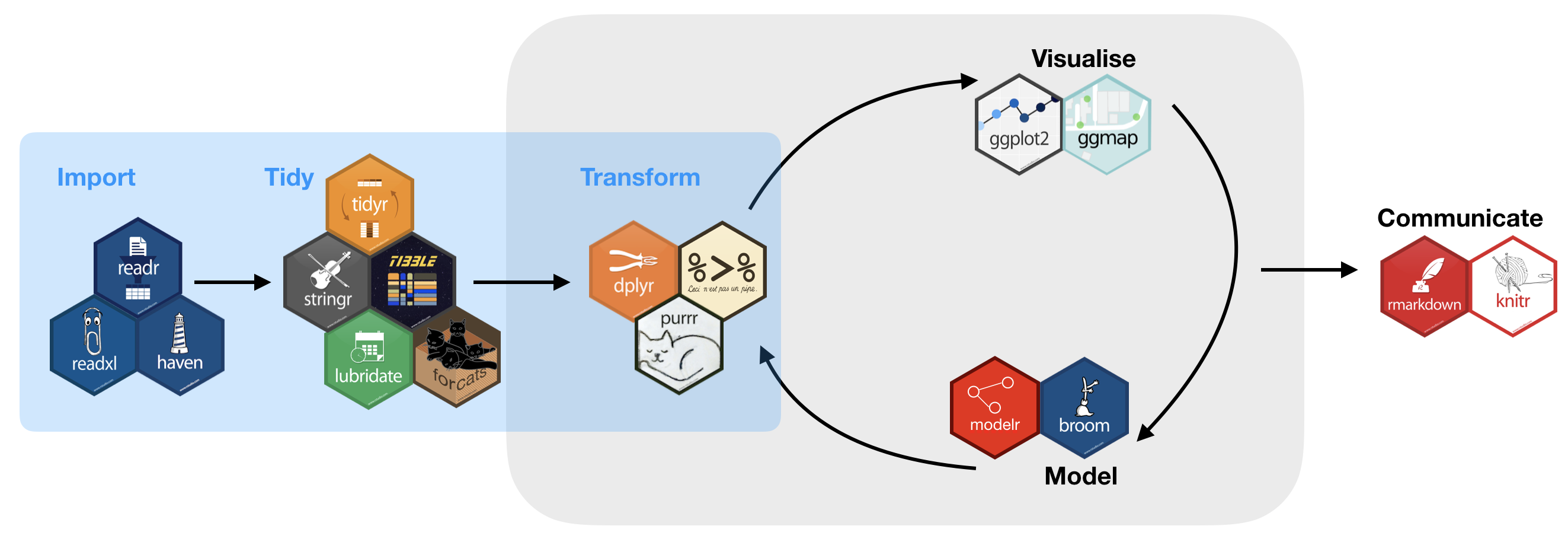
Warum tidyverse?
- Konsistenz, z.B.
- alle stringr Funktionen nehmen einen string als erstes Argument
- die meisten Funktionen nehmen den data frame als erstes Argument (piping)
- Es zwingt zu einer sorgfältigen Vorgehensweise
- Synergien zwischen verschiedenen Paketen/tools
- Implementiert einfache Lösungen zu allgemeinen Problemen
- Smartere default Einstellungen
- z.B.
utils::write.csv(row.names = FALSE),readr::write_csv()
- z.B.
- Funktionen sind oft wesentlich schneller (viele sind mit Rcpp umgesetzt)
- Zunahme an Paketen die das tidyverse Konzept implementieren
Am einfachsten ist die Installation (und das spätere Laden) eines einzigen Paketes, welches alle weiteren installiert
install.packages("tidyverse")
Moment ... ein kurzer Abstecher zu Paketen
Pakete
- Werden von der R community geschrieben
- Sind eine Sammlung von
- R Funktionen,
- der Dokumentation die beschreibt wie die Funktionen anzuwenden sind,
- und oft auch Beispieldaten
- Die offizielle CRAN package Webseite enthält aktuell 13700 (!) Pakete (Feb 10, 2019)
Installation (EINMALIG)
Die 'akzeptierte' Version kann von CRAN direkt über die Funktion install.packages() installiert werden
install.packages("package_name")
oder via R Studio:

Paket laden (JEDE SESSION)
Ein Paket muss für jede session geladen werden, um auf die Funktionen zugreifen zu können. Dazu gibt es library() und require(). R überprüft dann erstmal, ob dieses Paket auch installiert ist. Der Unterschied zwischen beiden Funktionen liegt nur in dem was passiert, wenn das Paket nicht vorhanden ist:
library(any_package) # library("any_package") would also work
## Error in library(any_package): there is no package called 'any_package'
require(any_package) # require("any_package")
Paket laden (JEDE SESSION)
Wenn ein spezifisches Paket geladen wird, wird es als default zum Suchpfad hinzugefügt:

modifiziert von Advanced R von H. Wickam, 2014
- Um eine Funktion aufrufen zu können, muss R sie erstmal finden. Dafür sucht R als erstes in der globalen Umgebung.
- Anschl. sucht R im Suchpfad, also der Liste aller geladenen Pakete, und zwar in einer spezifischen Reihenfolge.
- Wenn R mehrere Funktionen mit dem gleichen Namen findet, verwendet es die Funktion des zuletzt geladenen Pakets.
Paket laden (Forts.)
Du kannst Dir den Suchpfad explizit anzeigen lassen mit search().
search()
## [1] ".GlobalEnv" "tools:rstudio" "package:stats"
## [4] "package:graphics" "package:grDevices" "package:utils"
## [7] "package:datasets" "package:methods" "Autoloads"
## [10] "package:base"
Nach dem Laden von tidyverse
library(tidyverse)
siehst Du 8 weitere tidyverse Pakete die geladen wurden.
Du siehst auch einen Konflikt mit Funktionsnamen (filter() und lag() existieren in 2 Paketen)!
Lass uns den Suchpfad noch mal anzeigen:
search()
## [1] ".GlobalEnv" "package:forcats" "package:stringr"
## [4] "package:dplyr" "package:purrr" "package:readr"
## [7] "package:tidyr" "package:tibble" "package:ggplot2"
## [10] "package:tidyverse" "tools:rstudio" "package:stats"
## [13] "package:graphics" "package:grDevices" "package:utils"
## [16] "package:datasets" "package:methods" "Autoloads"
## [19] "package:base"
9 Pakete wurden insgesamt hinzugefügt (direkt nach der globalen Umgebung).
Wie kann man Pakete aus der Session inaktivieren?
Pakete werden aus dem Suchpfad einfach mit detach() entfernt
detach(packagename)
Oder indem die Box neben dem Paketnamen im 'Packages' pane entfernt wird:

Information zu Paketen
- Wenn Du
?packagename(z.B.?tidyverse) aufrufst, erhältst Du weitere Informationen zu den Kernaufgaben des Pakets kann und welche Funktionen verfügbar sind. Manchmal gibt es auch Weblinks für weitere Infos. - Aktuellere Pakete haben auch sog. "Vignetten", welche ein kleines Tutorial darstellen. Diese können aufgerufen werden über
vignette("packagename"). - Machmal gibt es sogar mehrere Vignetten. Für einen Überblick verwende
browseVignettes("packagename").
vignette("dplyr")
browseVignettes("dplyr")
Aufgabe
Quiz 1: Funktionskonflikte
Aus welchem der beiden Pakete wird R die Funktionen filter() und lag() verwenden?
- dplyr
- stats
dplyr wurde NACHstats (welches mit jeder session automatisch von R geladen wird) geladen, daher kommt dplyr auch vor stats im Suchpfad (Position 2 vs 10).
Zurück zu data wrangling: 1. Import
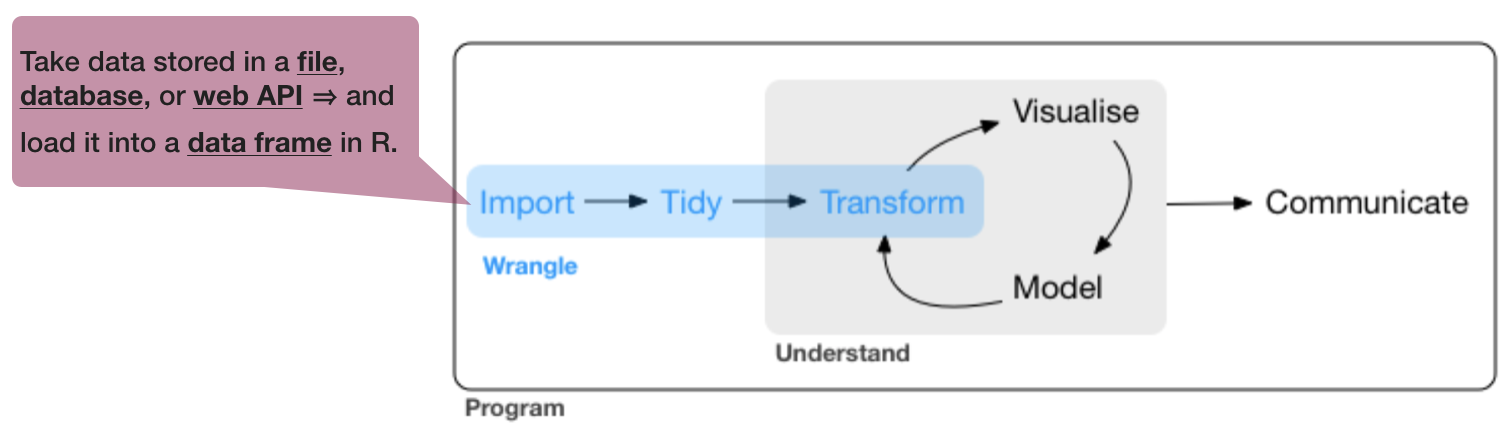
Datenquellen
- Excel Dateien (.xls / .xlsx)
- Komma-separierte Werte (.csv) --> gebräuchlichster Dateityp
- Textdateien (.txt)
- NetCDF (Network Common Data Form)
- Relationale Datenbanken (MySQL, PostgreSQL, etc.)
- URLs
- und viele weitere ...
Meistens wirst Du flache Dateien haben die Du in R laden willst (sprich ohne interne Hierarchien and Beziehungen wie in Datenbanken).
Import aus Excel

Basisfunktionen zum Importieren
read.table(file, header = TRUE, sep = "")read.csv(file, header = TRUE, sep = "")
Importfunktionen in 'readr'
- Die meisten readr’s Funktionen sind zum Importieren flacher Dateien in data frames bzw. sog.
tibbles:read_delim(): liest Dateien mit jedem delimiter ein.read_csv(): Komma-separierte Dateien (.csv)read_csv2(): Semikolon-separierte Dateien (.csv) - Gebräuchlich wenn das Komma als Dezimalzeichen verwendet wirdread_tsv(): Tab delimited Dateien (.txt files)- weitere
read_table(),read_fwf(),read_log()
- All diese Funktionen haben eine ähnliche oder die gleiche Syntax:

Eine kurze Demonstration von read_csv mit inline csv Dateien
Inline csv Dateien sind praktisch zum Experimentieren und um nachvollziehbare Beispiele zu erstellen:
read_csv("a,b,c
1,2,3
4,5,6")
## # A tibble: 2 x 3
## a b c
## <dbl> <dbl> <dbl>
## 1 1 2 3
## 2 4 5 6
Import optimieren - Zeilen auslassen
Die ersten n Zeilen mit Metadaten am Anfang einer Datei können ausgelassen werden mit skip = n:
read_csv("The first line of metadata
The second line of metadata
x,y,z
1,2,3", skip = 2)
## # A tibble: 1 x 3
## x y z
## <dbl> <dbl> <dbl>
## 1 1 2 3
Import optimieren - Spaltennamen
Wenn die Datei keine Spaltennamen enthält: col_names = FALSE; R vergibt dann die Labels X1 bis Xn:
read_csv("1,2,3
4,5,6", col_names = FALSE)
## # A tibble: 2 x 3
## X1 X2 X3
## <dbl> <dbl> <dbl>
## 1 1 2 3
## 2 4 5 6
Du kannst auch einen gesonderten character Vektor als col_names übergeben:
read_csv("1,2,3
4,5,6", col_names = c("x", "y", "z"))
## # A tibble: 2 x 3
## x y z
## <dbl> <dbl> <dbl>
## 1 1 2 3
## 2 4 5 6
Import optimieren - NAs
Das Argument na spezifiziert die Werte, die fehlende Werte repräsentieren (z.B. sind -999 oder -9999 oft Platzhalter):
read_csv("a,b,c
1,2,.", na = ".")
## # A tibble: 1 x 3
## a b c
## <dbl> <dbl> <lgl>
## 1 1 2 NA
read_csv("a,b,c
1,-9999,2", na = "-9999")
## # A tibble: 1 x 3
## a b c
## <dbl> <lgl> <dbl>
## 1 1 NA 2
Was sind eigentlich tibbles?
- Das 'tibble' Paket ermöglicht eine neue 'tbl_df' Klasse (das 'tibble'), welche striktere Qualitätschecks bereitstellt und sich besser formatieren lässt als die traditionellen data frames.
- Alle Funktionen für data frames funktionieren auch bei tibbles
- Alle tidyverse Pakete generieren tibbles automatisch
- Mehr zu tibbles gibt es hier:
vignette("tibble").
tibbles erstellen
- Geschieht automatisch beim Import mit readr
- Konvertiere einen bestehenden data frame mit
tibble::as_tibble(your_dataframe)
tibbles erstellen
- Geschieht automatisch beim Import mit readr
- Konvertiere einen bestehenden data frame mit
tibble::as_tibble(your_dataframe)
iris_tbl <- as_tibble(iris)
# Vergleiche mit
class(iris)
## [1] "data.frame"
class(iris_tbl)
## [1] "tbl_df" "tbl" "data.frame"
Wie Du siehst, iris_tbl vererbt auch die data.frame Klasse, hat jetzt aber eine zusätzliche tbl_df Klasse.
tibbles erstellen (Forts.)
- Oder Du erstellst einen neuen tibble mit individuellen Vektoren mit
tibble()
tibble(x = 1:5, y = 1, z = x ^ 2 + y)
## # A tibble: 5 x 3
## x y z
## <int> <dbl> <dbl>
## 1 1 1 2
## 2 2 1 5
## 3 3 1 10
## 4 4 1 17
## 5 5 1 26
Inputs von kürzeren Vektoren werden wieder automatisch recycled!
Printen von tibbles
- Jede Spalte gibt ihren Datentyp mit an
- Nur die ersten 10 Zeilen und alle Spalten die in den Screen passen werden angezeigt → einfacheres handling bei großen Datensätzen
- Wenn Du die Anzeige der Zeilen (n) und Spalten (width) ändern willst, benutze
print()und ändere die Argumente:
Printen von tibbles
- Jede Spalte gibt ihren Datentyp mit an
- Nur die ersten 10 Zeilen und alle Spalten die in den Screen passen werden angezeigt → einfacheres handling bei großen Datensätzen
- Wenn Du die Anzeige der Zeilen (n) und Spalten (width) ändern willst, benutze
print()und ändere die Argumente:
print(iris_tbl, n = 2, width = Inf) # = Inf zeigt alle Spalten
## # A tibble: 150 x 5
## Sepal.Length Sepal.Width Petal.Length Petal.Width Species
## <dbl> <dbl> <dbl> <dbl> <fct>
## 1 5.1 3.5 1.4 0.2 setosa
## 2 4.9 3 1.4 0.2 setosa
## # … with 148 more rows
Überblick an weiteren Funktionen:

Das cheat sheet ist frei verfügbar auf https://www.rstudio.com/resources/cheatsheets/
Andere Datentypen
Wenn Du weitere Datentypen hast die Du importieren willst, könnten folgende Pakete nützlich sein:
- haven - SPSS, Stata, und SAS Dateien
- readxl - Excel Dateien (.xls und .xlsx)
- ncdf4 or tidync - NetCDF (Network Common Data Form)
- DBI - Datenbanken
- jsonlite - json
- xml2 - XML
- httr - Web APIs
Roadmap

Reale Daten zum Importieren




Aufgabe
Import der ICES Daten
- Öffne die Datei "1111473b.csv" in einem Editor Deiner Wahl und schau Dir den Inhalt an.
- Lade die Datei in R ein:
- Setze zuerst das Arbeitsverzeichnis auf den Ordner, der die Datei einhält.
- Wähle die passende Importfunktion und die Argumenteinstellungen anhand des Inhalts und Dateiformats.
- Speichere die Daten unter dem Objektnamen
hydroab.
Import der ICES Daten
3.Inspiziere hydro.
- Was für eine Datenstruktur hat
hydro? - Stimmen die Dimensionen?
- Was ist mit den leeren Elementen passiert (z.B. Zeile 127-137)
- Stimmen die Datentypen pro Zeile?
4.Da die Spaltennamen ungeeignet sind, wähle hier passendere Namen.
Lass uns der Roadmap folgen:
1.Schritt: Öffne die Dateien in einem Editor und überprüfe den Inhalt
In RStudio:
- Gehe zum 'Files' pane.
- Navigiere Dich zum Ordner mit der '1111473b.csv' Datei
- Klicke auf die Datei und wähle "View file" aus → jetzt wird die Datei im Source' pane sichtbar

Lass uns der Roadmap folgen:
2.Schritt: Lade die Daten in R ein
- Stelle sicher, dass das Arbeitsverzeichnis (working directory) richtig ist.
- Das falsche Arbeitsverzeichnis ist die häufigste Ursache für Fehlermeldungen!
hydro <- read_csv("data/1111473b.csv")
Überprüfe die Struktur
class(hydro)
## [1] "spec_tbl_df" "tbl_df" "tbl" "data.frame"
dim(hydro)
## [1] 30012 11
print(hydro, n = 2)
## # A tibble: 30,012 x 11
## Cruise Station Type `yyyy-mm-ddThh:mm` `Latitude [degr…
## <chr> <chr> <chr> <dttm> <dbl>
## 1 ???? 0247 B 2015-02-17 09:54:00 55
## 2 ???? 0247 B 2015-02-17 09:54:00 55
## # … with 3.001e+04 more rows, and 6 more variables: `Longitude
## # [degrees_east]` <dbl>, `Bot. Depth [m]` <chr>, `PRES [db]` <dbl>,
## # `TEMP [deg C]` <dbl>, `PSAL [psu]` <dbl>, `DOXY [ml/l]` <dbl>
Überprüfung von leeren Feldern
hydro[127:136, ]
## # A tibble: 10 x 11
## Cruise Station Type `yyyy-mm-ddThh:mm` `Latitude [degr…
## <chr> <chr> <chr> <dttm> <dbl>
## 1 ???? 1612 B 2015-09-23 11:20:00 55.2
## 2 ???? 1612 B 2015-09-23 11:20:00 55.2
## 3 ???? 1612 B 2015-09-23 11:20:00 55.2
## 4 ???? 1612 B 2015-09-23 11:20:00 55.2
## 5 ???? 1612 B 2015-09-23 11:20:00 55.2
## 6 ???? 1612 B 2015-09-23 11:20:00 55.2
## 7 ???? 1612 B 2015-09-23 11:20:00 55.2
## 8 ???? 1612 B 2015-09-23 11:20:00 55.2
## 9 ???? 1612 B 2015-09-23 11:20:00 55.2
## 10 ???? 1612 B 2015-09-23 11:20:00 55.2
## # … with 6 more variables: `Longitude [degrees_east]` <dbl>, `Bot. Depth
## # [m]` <chr>, `PRES [db]` <dbl>, `TEMP [deg C]` <dbl>, `PSAL
## # [psu]` <dbl>, `DOXY [ml/l]` <dbl>
Überprüfung der Datentypen
# str(hydro)
# besser bei tibbles:
glimpse(hydro)
## Observations: 30,012
## Variables: 11
## $ Cruise <chr> "????", "????", "????", "????", "????…
## $ Station <chr> "0247", "0247", "0247", "0247", "0247…
## $ Type <chr> "B", "B", "B", "B", "B", "B", "B", "B…
## $ `yyyy-mm-ddThh:mm` <dttm> 2015-02-17 09:54:00, 2015-02-17 09:5…
## $ `Latitude [degrees_north]` <dbl> 55.00, 55.00, 55.00, 55.00, 55.00, 55…
## $ `Longitude [degrees_east]` <dbl> 13.3000, 13.3000, 13.3000, 13.3000, 1…
## $ `Bot. Depth [m]` <chr> "0048", "0048", "0048", "0048", "0048…
## $ `PRES [db]` <dbl> 0.2, 1.0, 5.0, 10.0, 15.0, 20.0, 25.0…
## $ `TEMP [deg C]` <dbl> 3.57, 3.57, 3.56, 3.56, 3.55, 3.55, 3…
## $ `PSAL [psu]` <dbl> 9.029, 9.006, 9.008, 9.053, 9.055, 9.…
## $ `DOXY [ml/l]` <dbl> 6.76, 6.71, 6.47, 6.17, 6.03, 6.03, 6…
Ändere die Spaltennamen
Um das spätere Manipulieren der Daten zu vereinfachen, nutze kurze Namen:
names(hydro) <- c("cruise", "station", "type", "date_time",
"lat", "long", "depth", "pres", "temp", "psal", "doxy")
Daten speichern und exportieren
Daten als R Objekte speichern
Du kannst Dein tibble oder data frame als .R Objekt abspeichern und jederzeit wieder laden mit save(your_tibble, "filename") und load("filename"):
save(hydro, file = "Mein_erstes_Objekt.R")
# Wir löschen hydro aus der globalen Umgebung
rm(hydro)
hydro
load(file = "Mein_erstes_Objekt.R")
hydro # jetzt sollte es wieder da sein
Exportieren von Daten
- Wenn Du Deine Daten exportieren willst um sie dann mit anderen Programmen zu bearbeiten, verwende am besten das gleiche Format wie beim Import.
- Die meisten Importfunktionen haben ein Äquivalent zum Exportieren:
read_delim()-->write_delim()read_csv()-->write_csv()read_tsv()-->write_tsv()- andere Funktionen:
write_excel_csv()
write_csv(hydro, "Mein_hydro_Datensatz.csv")
Übersicht an neuen Funktionen
install.packages(), library(), require(), search(), detach(), vignette(), browseVignettes(),
read_delim(), read_csv(), read_csv2(), read_tsv(), read_table(), read_fwf(), read_log(),
tibble(), as_tibble(), print(), save(), load(),
write_delim(), write_csv(), write_tsv(), write_excel_csv()
Wie fühlst Du Dich?
Total konfus?

Lese nach im Kapitel 10 Tibbles und 11 Data import in 'R for Data Science'.
Total gelangweilt?

Dann probiere mal eigene Daten zu importieren und in R zu explorieren.
Absolut zufrieden?
Dann hol Dir einen Kaffee, lehn Dich zurück und genieße den Rest des Tages...!

Bei weiteren Fragen kontaktieren Sie mich unter:
saskia.otto@uni-hamburg.de
http://www.researchgate.net/profile/Saskia_Otto
http://www.github.com/saskiaotto

Diese Arbeit ist lizensiert unter der
Creative Commons Attribution-ShareAlike 4.0 International License
mit Ausnahme externer
Materialien gekennzeichnet durch die source: Angabe.
Bild auf Titel- und Abschlussfolie: Frühjahrsblüte in der Nordsee
USGS/NASA Landsat:
Spring Color in the North Sea, Landsat 8 - OLI, May 7, 2018
(unter CC0 lizenz)